

Hapag-Lloyd stands as one of the world’s leading liner shipping companies, operating a modern fleet of 313 container ships with a total transport capacity of 2.5 million TEU (Twenty-foot Equivalent Unit—a standard unit of measurement for cargo capacity in container shipping). The company maintains a container capacity of 3.7 million TEU, which includes one of the industry’s largest and most modern fleets of reefer containers. With approximately 14,000 employees in the Liner Shipping Segment and more than 400 offices spread across 140 countries, Hapag-Lloyd maintains a robust global presence. Through 133 liner services worldwide, we facilitate reliable connections between more than 600 ports across the continents.
The company’s Digital Customer Experience and Engineering team, distributed between Hamburg and Gdańsk, drives digital innovation by developing and maintaining customer-facing web and mobile products.
Over the past years, the Digital Customer Experience and Engineering team has evolved from a delivery-focused channel into a true digital product driver, with strong customer focus, engineering excellence, and measurable business impact. We take end-to-end ownership of our digital products, combining customer-centric innovation with engineering craft to directly support growth and business outcomes. Building on a modern, independently owned tech stack and a high level of engineering maturity, we are committed to staying at the forefront of technology. Now, we are taking the next step by moving toward becoming AI-native, investing heavily in artificial intelligence as a core capability. This journey is about amplifying powerful engineering with AI to build smarter products, faster innovation, and greater customer value.
Understanding user impact.
So far, our customer feedback analysis process had largely been manual and reactive. Especially ahead of review ceremonies, manually analyzing customer feedback could take hours, sometimes days, when hundreds of ratings and comments needed to be reviewed. Every two weeks, Product Managers exported customer feedback data as CSV files, read through large volumes of comments, and manually categorized sentiment and themes. Although this work was valuable and deeply connected to product decisions, it was also repetitive, time-consuming, and difficult to scale, limiting flexibility whenever faster or deeper insights were needed.
With our generative AI solution, we fundamentally changed this approach. Instead of manually aggregating and interpreting feedback, we now automate the entire workflow: collecting customer comments, extracting sentiment, identifying themes, and surfacing actionable insights. Product Managers and teams can focus less on operational analysis and more on strategy, innovation, and creating exceptional user experiences.
In this post, we walk you through our generative AI–powered feedback analysis solution built using Amazon Bedrock, Elasticsearch, and open-source frameworks like LangChain and LangGraph. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies such as AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. With this solution, you can automatically ingest customer comments, generate rich summaries, and deliver targeted insights. This allows our product teams to make faster, smarter decisions and drive continuous improvement.
We walk you through the architecture and implementation of this solution, demonstrating how using generative AI foundations, such as orchestration, data management, security, and privacy, allowed us to rapidly build a scalable, production-ready feedback processing pipeline.
Solution overview
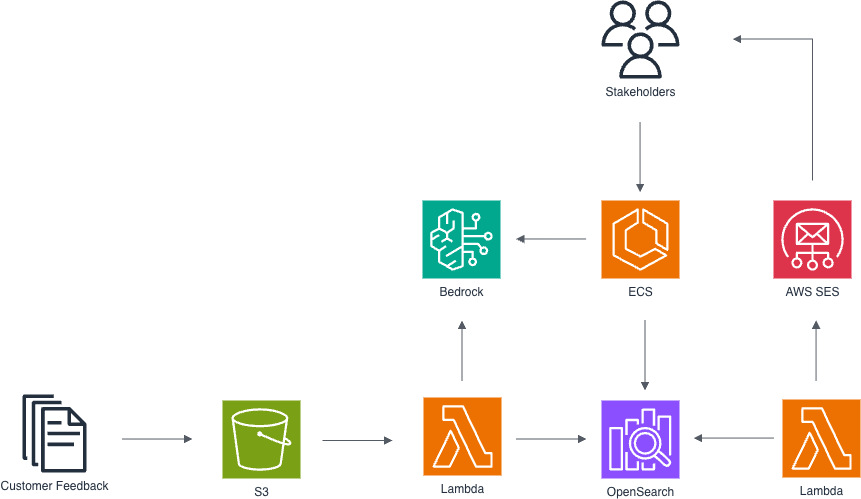
AWS architecture for automated feedback processing and analysis, utilizing Lambda functions for data ingestion from Amazon S3, Amazon Bedrock for AI-powered insights accessed by stakeholders via Amazon ECS, and Elasticsearch for indexing and querying feedback data with email notifications via SES.
The solution is built on AWS architecture designed to address these challenges through scalability, maintainability, and security. It is deployed by using AWS CloudFormation.
- Continuous & Quarterly Feedback Collection
- Our web and mobile applications serve hundreds of thousands of customers each month.
- Users can leave a rating plus text comments, helping us understand user experience and improve services.
- Daily Feedback Ingestion & Processing
- A AWS Lambda function runs once per day to fetch the new feedback entries.
- We use Amazon Bedrock to classify sentiment (positive, negative, mixed, or neutral) for each open comment, streamlining downstream analysis.
- Processed records are indexed in Amazon OpenSearch Service, serving both as our full-text search engine and vector database.
- Interactive feedback exploration via OpenSearch Service
- Stakeholders can access real-time feedback insights through OpenSearch Dashboards, giving them a bird’s-eye view of user sentiment, ratings, and trends over time.
- Starting with high-level visualizations, such as sentiment distribution, rating scores, and feedback volume, users can drill down into specific applications, features, or even individual comments.
- Dashboards support filtering by time period, comment sentiment, product version, and more, enabling targeted root cause analysis.
- For example, a Product Manager can visualize how sentiment around a recent app update changed week over week, or zoom into negative comments mentioning a specific feature.
- AI-Powered Internal Chatbot
- Our stakeholder-facing chatbot queries the OpenSearch index as its knowledge base.
- We use Bedrock Guardrails, to enforce safety and reliability and make sure responses align with our brand and compliance standards.
- Product managers and support teams can ask natural-language questions, for example, “What pain points do customers mention most often?” and receive instant, context-rich answers.
- Biweekly Insights Report
- Every two weeks, a second Lambda function aggregates and analyzes the latest feedback trends.
- It generates a concise report with key metrics, highlights, and sentiment breakdowns.
- The report is automatically delivered to our Product Managers and Product Owners, feeding directly into sprint planning and roadmap discussions.
Generative AI Orchestration
Orchestration is a core foundation of our solution, because generative AI workflows typically involve multiple steps that need to be coordinated. In our pipeline, data ingestion and processing steps, such as sentiment analysis, embedding generation, and indexing, are orchestrated using LangChain, which provides modular, reusable components for calling models, transforming data, and integrating with external systems like Amazon OpenSearch Service. For our internal chatbot, we rely on LangGraph to implement a multi-agent architecture. Each assistant is defined declaratively in LangGraph, encapsulating its own logic and tools. This design makes assistants flexible and composable: instead of rigid step-by-step flows, we use an agent-based approach where an LLM selects the right tools and actions dynamically to answer user queries. This gives product managers and support teams a natural, interactive way to explore feedback and related operational insights.
Integration with Amazon Bedrock models is straightforward using LangChain’s native support. For example, our AI-powered internal chatbot uses the Claude Sonnet 4.6 model via Amazon Bedrock. We chose Claude Sonnet 4.6 because it offers frontier performance across coding and agentic workflows. The model excels in multi-turn conversational exchanges and agentic workflows, making it ideal for our internal chatbot that requires reliable performance across single and multi-turn interactions with stakeholders. With its precise workflow management capabilities and ability to serve in both lead agent and subagent roles, Claude Sonnet 4.6 delivers the consistent conversational quality our product managers and support teams need when exploring feedback insights at scale. Additionally, we leverage geographic Cross-Region Inference Service (CRIS) endpoint to seamlessly manage unplanned traffic bursts by distributing compute across multiple EU AWS Regions. This cross-region capability ensures our feedback processing pipeline remains resilient during peak usage periods while maintaining consistent performance for our global stakeholder base. The model is configured with guardrails applied directly through LangChain configuration:
Data Management
An AWS Lambda function runs once per day to fetch the new feedback entries from the feedback repository into Amazon S3, after which the data is categorized with semantic detection through Amazon Bedrock. The data is then indexed in Amazon OpenSearch Service, serving both as our full-text search engine and vector database.
Responsible AI
To responsibly use the solution, we implement safeguards using Amazon Bedrock Guardrails. This allows us to attach Amazon Bedrock Guardrails to an AI interaction and enforce content moderation policies and make sure responses align with our brand and compliance standards.
Using AWS CloudFormation, we define guardrail policies as infrastructure-as-code, providing examples of configurations to help block harmful content.
Guardrails as Code: CloudFormation
Programmatic Input Validation
We also use Amazon Bedrock Guardrails independently to validate raw user input before passing it to the LLM, helping prevent prompt injection and other misuse:
With this setup, we have created a more secure, scalable, and explainable pipeline that puts Generative AI to work, responsibly and effectively, across our product feedback lifecycle.
Monitoring
We monitor the parts of the application using Amazon CloudWatch, which collects raw data and processes it into readable, near real-time metrics. We enabled model invocation logging to collect invocation logs, model input data, and model output data for the invocations, enabling collection of full request data, response data, and metadata associated with the calls. Amazon Bedrock also integrates with AWS CloudTrail, which captures API calls for Amazon Bedrock as events. This generates insights that you can use to optimize the applications further like improving response latency or reducing costs.
Next Steps
The solution processes over 15,000 feedback items per month with an accuracy of 95% for sentiment classification on a labeled test dataset. Instead of spending hours reviewing raw feedback, teams can now receive clear, structured summaries in seconds that highlight the most important topics and recurring signals. This helps them move from information to action much faster, making decisions within days rather than weeks. Over time, the reports helped us understand not only when sentiment improved, but also why it didn’t. By continuously monitoring customer feedback, we can react quickly to early signals, adjust decisions, and correct course when needed. In several areas, actions taken based on these insights have already resulted in more positive comments and a noticeable reduction in negative feedback. A strong example is the “Preview” functionality in Shipping Instructions. This feature was prioritized directly in response to a high volume of negative user feedback highlighting the lack of a preview capability. After its release, AI-driven reports allowed us to track user reactions in detail. Feedback related specifically to this feature showed that the previously frequent requests for preview capability were effectively resolved, demonstrating that the core user need had been successfully addressed. At the same time, broader feedback continued to surface other areas for improvement across the application. AI insights also guided future feature planning and prioritization. Based on user comments, we created new OpenSearch Service-based dashboards that help teams quickly verify and analyze issues reported by users. Another example is the ability to upload cargo data via Excel files, a repeatedly requested feature highlighted by AI recommendations. This functionality is now fully available and is expected to significantly reduce manual effort, particularly for large shipments. During review sessions, the stakeholders can now see top positive and negative comments in real time, alongside AI-generated recommendations, creating a far more informed and productive discussion.
This feedback analysis solution is one example of how we are applying generative AI across our processes, and it marks the beginning, not the end, of our AI-native journey. Under our AI-Native Umbrella Program, which serves as a single source of truth for AI adoption, our next focus is to establish a shared, robust AI foundation with Amazon Bedrock. By providing standardized infrastructure, security, and guardrails, we aim to enable every role in the department, engineering, product and delivery (PM, PO, SM), UX/design, and operations/support, to create their own AI “spaces” safely and independently while having access to the best in-class foundation models. This setup is designed to lower the barrier to experimentation, streamline discovery, and encourage hands-on exploration of generative AI use cases in day-to-day work. In doing so, we help teams move faster from ideas to impact, while maintaining consistency, responsibility, and scalability across the AI initiatives.
If you want to scale your generative AI applications, you can get started by reading this Architect a mature generative AI foundation on AWS that dives deeper on the various foundational components that help accelerate the end-to-end generative AI application lifecycle.
