

This post is written by Nukul Sharma, Machine Learning Engineering Manager, and Karthik Dasani, Staff Machine Learning Engineer, at Warner Bros. Discovery.
Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. With iconic brands including HBO, Discovery Channel, Warner Bros., CNN, DC Entertainment, and many others, WBD delivers premium storytelling to audiences worldwide through diverse systems and experiences. Our streaming services, including HBO Max and discovery+, represent a cornerstone of our direct-to-consumer strategy, offering viewers unprecedented access to our 200,000+ hours of programming.
In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models.
Warner Bros. Discovery (WBD) brands
In the rapidly evolving world of digital entertainment, exceptional content alone isn’t enough—viewers need to discover programs that match their unique interests. Delivering highly personalized content has become essential for engaging audiences, driving viewing sessions, and building lasting relationships with users. To effectively serve our diverse base of over 125M+ users across 100+ countries (as of 2025), we employ data science, user behavior analysis, and human curation to predict what viewers will love. Our work focuses on crafting dynamic recommendation algorithms and tailoring suggestions to individual preferences, while continuously testing and refining strategies to improve content relevance accuracy.
The challenge: Scaling personalization globally while managing costs
HBO Max’s Search and Personalization infrastructure spans 9 AWS Regions spread across USA, EMEA and APAC to deliver localized recommendations tailored to regional preferences. This extensive infrastructure enables us to maintain consistent sub-100ms latency requirements while serving personalized content recommendations across diverse geographic regions.
With a vast portfolio of our beloved brands combined with a diverse user base, we faced the challenge of personalizing content recommendations without compromising on budget. Recommendation systems are latency critical; they need to be run in real-time which means stringent requirements for the ML infrastructure needed to deploy our services. This content discovery challenge requires sophisticated recommender systems that can perform reliably at massive scale, even during major premieres when traffic surges up to 500% within minutes. We were looking for real-time performance and a cost-effective infrastructure solution for our AI/ML workloads.
Our solution: Using AWS Graviton for cost-effective ML inference at scale
Our solution combined two key AWS technologies: AWS Graviton processors and Amazon SageMaker AI. This integrated approach allowed us to comprehensively address both our performance and cost challenges.
AWS Graviton is a family of processors designed to deliver the best price performance for cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2) and fully managed services. They are also optimized for ML workloads, including Neon vector processing engines, support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions, making them an ideal choice for our latency critical recommender systems.
We decided to try them for our XGBoost and TensorFlow-based ML models for which we followed a two-step process. First, we started with a sandbox environment, fine-tuned workers and threads to maximize the throughput on a single instance and observed substantially better performance compared to x86-based instances in our fleet. Second, we moved on to the production traffic, where we performed shadow testing to confirm the cost and the performance benefits we observed in the standalone environment. We noticed that Graviton instances were able to scale almost linearly even at higher CPU loading. We reconfigured our auto-scale configs to increase the instance utilization and because Graviton instances were able to handle burst traffic more effectively, we also reduced the minimum number of instances. Additionally, we balanced the cost vs performance not to impact one in over-optimizing for the other.
The SageMaker Inference Recommender played a crucial role in streamlining our testing workflow. By automating the benchmarking process across different instance types and configurations, this tool significantly reduced the time needed to identify optimal setups for our models. The automated performance analysis helped us make data-driven decisions about instance selection and accelerated our model deployment pipeline.
To validate the performance and reliability of our new infrastructure, we utilized the shadow testing capabilities of Amazon SageMaker. This testing framework enabled our team to evaluate new deployments alongside existing production systems, providing real-world performance comparisons without risking impact to our users’ experience. This approach proved particularly valuable for our Machine Learning Platform (MLP) team users as they assessed various infrastructure modifications. By running parallel tests of different hardware setups and fine-tuning inference parameters, we could thoroughly evaluate system performance before committing to changes. This strategic testing method helped us anticipate potential issues and optimize configurations early in our deployment process.
The following diagram highlights the end-to-end deployment of our ML inference workload on AWS. As shown here, we’ve already been using multiple fully managed AWS services like Amazon SageMaker, Amazon Simple Storage Service (Amazon S3), and Amazon DynamoDB to achieve our recommender systems’ objectives. This time, we took one step forward to migrate to AWS Graviton-based instances that resulted in cost savings and improved performance.
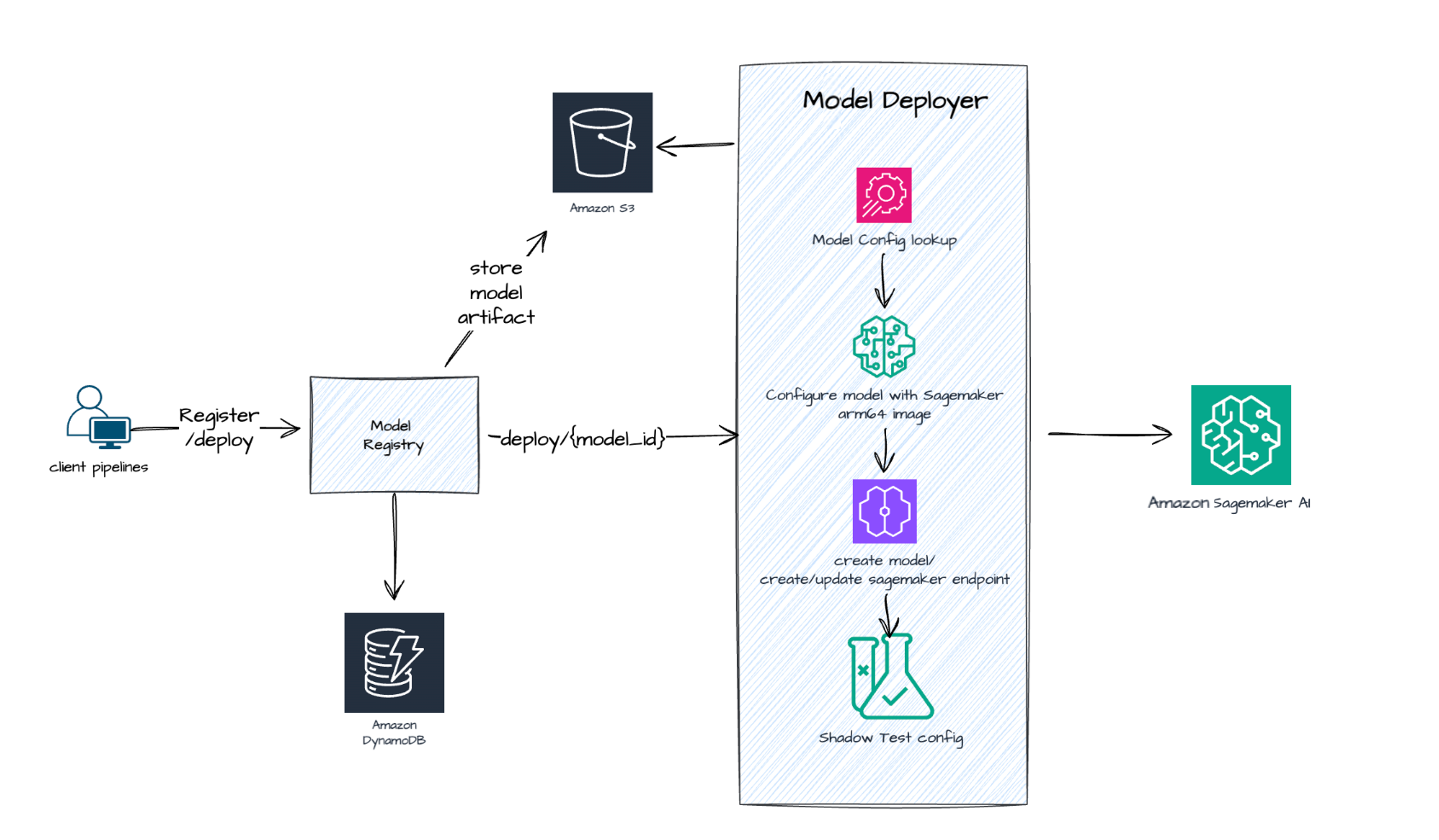
Results
The migration to AWS Graviton-based instances from x86-base instances delivered remarkable results across our recommendation system portfolio.
Achieved 60% cost savings
Our comprehensive analysis revealed substantial cost reductions across our personalization models, achieving an average cost savings of 60%. The improvements were particularly notable in our catalog ranking models, where we observed cost reductions of up to 88%.
Improved average and p99 latencies, ranging from 7% to 60% across different models
Apart from cost savings, we also achieved significant performance enhancements. The P99 latency improvements were impressive across our model suite with our XGBoost model showing a dramatic 60% reduction in latency. Other models in our portfolio demonstrated consistent latency improvements up to 21%. The following dashboard from our A/B testing highlights how migrating to AWS Graviton-based ML instances improved the average and p99 latencies and cut down the instance count substantially. GREEN lines are from x86 based servers in our fleet and the YELLOW lines are from AWS Graviton based servers.
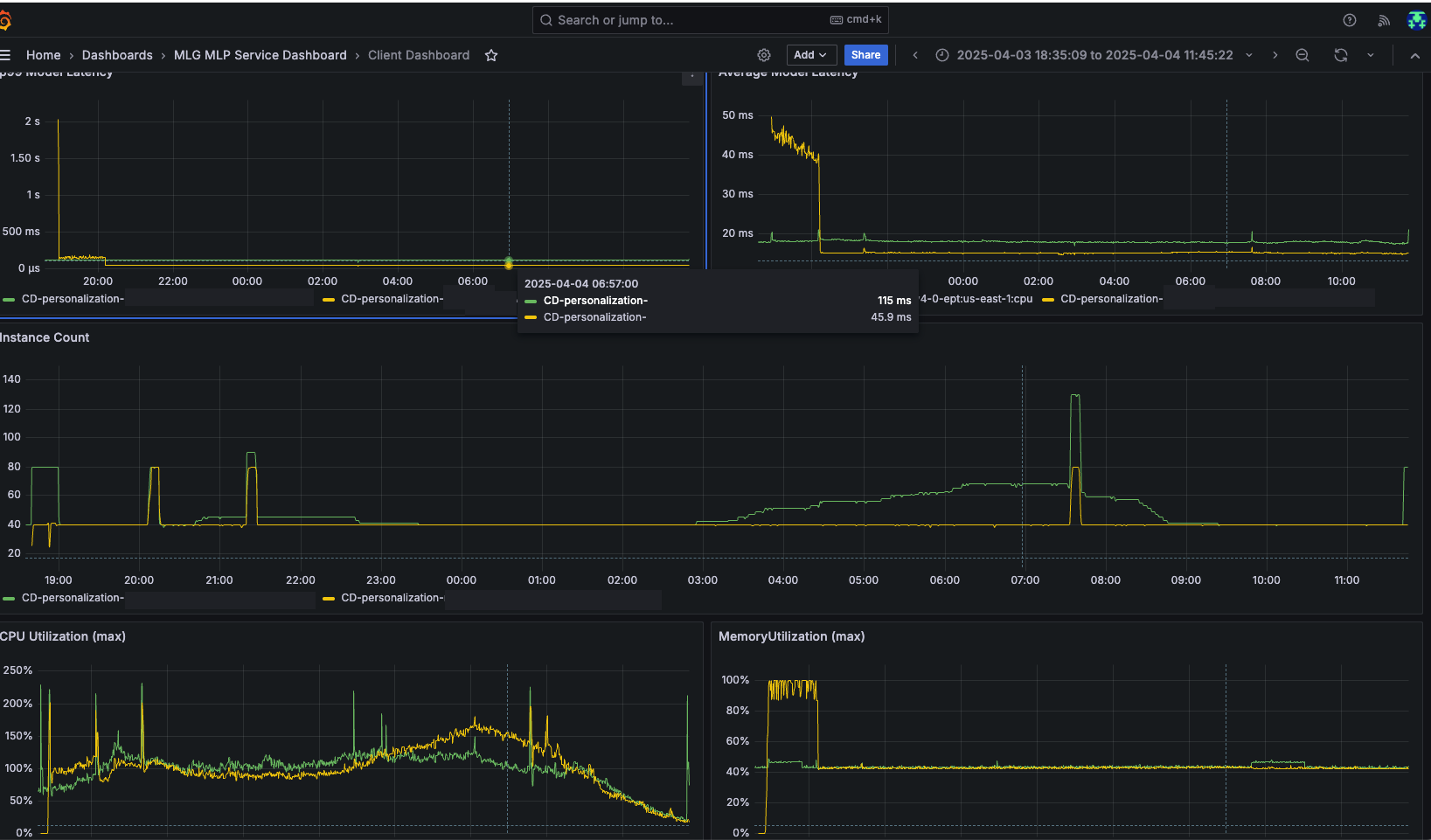
Improved user experience
By reducing latency, we significantly improved the performance of our services and the user experience for our customers; viewers experienced more responsive recommendations that better match their interests.
Experienced seamless migration
We had a great collaboration with AWS account and service teams throughout the project. The migration was seamless. From the initial benchmarking to the final migration it took around one month; proof of concept on a catalog ranking model that gave 60% cost saving was done in a week’s time, which was much faster than the time we had originally estimated.
Motivated to achieve 100% of recommender system to run on Graviton-based instance
Looking at the substantial cost savings we’ve achieved with Graviton adoption, we are currently working on migrating our remaining models to Graviton with a target of achieving 100% of recommender system to run on Graviton-based instances.
Conclusion
By migrating our ML inference workloads to AWS Graviton-based instances, we’ve transformed how we deliver personalized content recommendations to our 125M+ users across 100+ countries. The migration yielded impressive results with cost reductions averaging 60% across our recommender systems and latency improvements ranging from 7% to 60% across different models. These performance gains translate into tangible business outcomes: viewers experience more responsive recommendations that better match their interests, resulting in deeper engagement, extended viewing sessions, and ultimately stronger retention on our systems—all while allowing us to scale our operations efficiently.
Overall, the adoption of AWS Graviton processors exemplifies how innovative cloud solutions can drive both operational efficiency and business value. Our experience demonstrates that organizations can successfully balance the competing demands of performance, cost, and scale in the rapidly evolving business landscape. As we continue to optimize our ML infrastructure, these improvements will help us stay competitive while delivering increasingly personalized experiences to our global audience.
For further reading, refer to the following:
- Reduce Amazon SageMaker inference cost with AWS Graviton
- Optimized PyTorch 2.0 Inference with AWS Graviton processors
- AWS Graviton Technical Guide: Machine Learning
The WBD team would like to thank Sunita Nadampalli, Utsav Joshi, Karthik Rengasamy, Tito Panicker, Sapna Patel, and Gautham Panth from AWS for their contributions to this solution.
About the authors
 Nukul Sharma is a Machine Learning Engineering Manager with 18+ years of experience leading top-performing engineering and MLOps teams at Warner Bros. Discovery. Skilled in developing scalable solutions, end-to-end ML pipelines, cloud systems, and CI/CD. Proven track record in delivering impactful personalization and MLOps solutions that drive efficiency and growth.
Nukul Sharma is a Machine Learning Engineering Manager with 18+ years of experience leading top-performing engineering and MLOps teams at Warner Bros. Discovery. Skilled in developing scalable solutions, end-to-end ML pipelines, cloud systems, and CI/CD. Proven track record in delivering impactful personalization and MLOps solutions that drive efficiency and growth.
 Karthik Dasani is a Staff Machine Learning Engineer with expertise in large-scale recommendation systems and ML Ops at Warner Bros. Discovery. He has extensive experience in productionizing AI solutions with a strong focus on performance and cost optimization. His work bridges applied research and scalable, real-world machine learning systems.
Karthik Dasani is a Staff Machine Learning Engineer with expertise in large-scale recommendation systems and ML Ops at Warner Bros. Discovery. He has extensive experience in productionizing AI solutions with a strong focus on performance and cost optimization. His work bridges applied research and scalable, real-world machine learning systems.
About the AWS Team
 Sunita Nadampalli is a Principal Engineer and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open-source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
Sunita Nadampalli is a Principal Engineer and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open-source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
 Utsav Joshi is a Principal Technical Account Manager at AWS. He lives in New Jersey and enjoys working with AWS customers in solving architectural, operational, and cost optimization challenges. In his spare time, he enjoys traveling, road trips, and playing with his kids.
Utsav Joshi is a Principal Technical Account Manager at AWS. He lives in New Jersey and enjoys working with AWS customers in solving architectural, operational, and cost optimization challenges. In his spare time, he enjoys traveling, road trips, and playing with his kids.
 Karthik Rengasamy is a Senior Solutions Architect at AWS, specializing in helping media and entertainment customers design and scale their cloud architectures. He focuses on media supply chain, archive, and video streaming solutions, working closely with customers to drive innovation and optimize media workloads on AWS. His passion lies in building secure, scalable, and cost-effective solutions that transform how media is managed and delivered to global audiences.
Karthik Rengasamy is a Senior Solutions Architect at AWS, specializing in helping media and entertainment customers design and scale their cloud architectures. He focuses on media supply chain, archive, and video streaming solutions, working closely with customers to drive innovation and optimize media workloads on AWS. His passion lies in building secure, scalable, and cost-effective solutions that transform how media is managed and delivered to global audiences.
 Tito Panicker is a Sr. Global Solutions Architect who helps the largest enterprise customers architect secure, scalable, and resilient solutions in the cloud. His primary area of focus is the Media and Entertainment vertical, where he specializes in Direct-to-Consumer (D2C) streaming, data/analytics, AI/ML, and generative AI.
Tito Panicker is a Sr. Global Solutions Architect who helps the largest enterprise customers architect secure, scalable, and resilient solutions in the cloud. His primary area of focus is the Media and Entertainment vertical, where he specializes in Direct-to-Consumer (D2C) streaming, data/analytics, AI/ML, and generative AI.
 Sapna Patel is a Principal Customer Solutions Manager at AWS who helps media and entertainment customers optimize their cloud journey through strategic guidance and relationship management. She focuses on driving customer success by aligning AWS solutions with business objectives, making sure customers maximize value from their cloud investments while achieving their technical and operational goals.
Sapna Patel is a Principal Customer Solutions Manager at AWS who helps media and entertainment customers optimize their cloud journey through strategic guidance and relationship management. She focuses on driving customer success by aligning AWS solutions with business objectives, making sure customers maximize value from their cloud investments while achieving their technical and operational goals.
 Gautham Panth is a Principal Product Manager at AWS focused on building pioneering cloud infrastructure solutions. With over 20 years of cross-disciplinary expertise spanning cloud computing, enterprise infrastructure, and software, Gautham leverages his comprehensive understanding of customer challenges, to drive future direction and capabilities of AWS offerings.
Gautham Panth is a Principal Product Manager at AWS focused on building pioneering cloud infrastructure solutions. With over 20 years of cross-disciplinary expertise spanning cloud computing, enterprise infrastructure, and software, Gautham leverages his comprehensive understanding of customer challenges, to drive future direction and capabilities of AWS offerings.


