

Video content is now everywhere, from security surveillance and media production to social platforms and enterprise communications. However, extracting meaningful insights from large volumes of video remains a major challenge. Organizations need solutions that can understand not only what appears in a video, but also the context, narrative, and underlying meaning of the content.
In this post, we explore how the multimodal foundation models (FMs) of Amazon Bedrock enable scalable video understanding through three distinct architectural approaches. Each approach is designed for different use cases and cost-performance trade-offs. The complete solution is available as an open source AWS sample on GitHub.
The evolution of video analysis
Traditional video analysis approaches rely on manual review or basic computer vision techniques that detect predefined patterns. While functional, these methods face significant limitations:
- Scale constraints: Manual review is time-consuming and expensive
- Limited flexibility: Rule-based systems can’t adapt to new scenarios
- Context blindness: Traditional CV lacks semantic understanding
- Integration complexity: Difficult to incorporate into modern applications
The emergence of multimodal foundation models on Amazon Bedrock changes this paradigm. These models can process both visual and textual information together. This enables them to understand scenes, generate natural language descriptions, answer questions about video content, and detect nuanced events that would be difficult to define programmatically.

Three approaches to video understanding
Understanding video content is inherently complex, combining visual, auditory, and temporal information that must be analyzed together for meaningful insights. Different use cases, such as media scene analysis, ad break detection, IP camera tracking, or social media moderation, require distinct workflows with varying cost, accuracy, and latency trade-offs.This solution provides three distinct workflows, each using different video extraction methods optimized for specific scenarios.
Frame-based workflow: precision at scale
The frame-based approach samples image frames at fixed intervals, removes similar or redundant frames, and applies image understanding foundation models to extract visual information at the frame level. Audio transcription is performed separately using Amazon Transcribe.

This workflow is ideal for:
- Security and surveillance: Detect specific conditions or events across time
- Quality assurance: Monitor manufacturing or operational processes
- Compliance monitoring: Verify adherence to safety protocols
The architecture uses AWS Step Functions to orchestrate the entire pipeline:
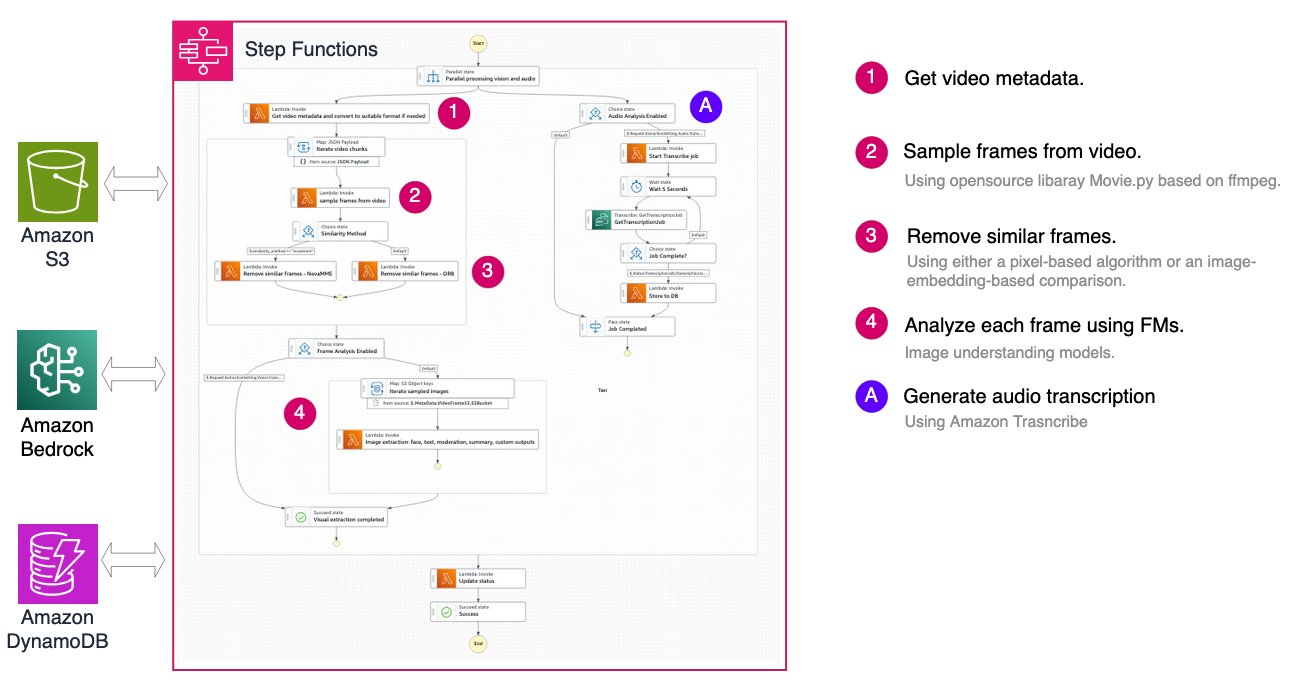
Smart sampling: optimizing cost and quality
A key feature of the frame-based workflow is intelligent frame deduplication, which significantly reduces processing costs by removing redundant frames while preserving visual information. The solution provides two distinct similarity comparison methods.
Nova Multimodal Embeddings (MME) Comparison uses the multimodal embeddings model of Amazon Nova to generate 256-dimensional vector representations of each frame. Each frame is encoded into a vector embedding using the Nova MME model, and the cosine distance between consecutive frames is computed. Frames with distance below the threshold (default 0.2, where lower values indicate higher similarity) are removed. This approach excels at semantic understanding of image content, remaining robust to minor variations in lighting and perspective while capturing high-level visual concepts. However, it incurs additional Amazon Bedrock API costs for embedding generation and adds slightly higher latency per frame. This method is recommended for content where semantic similarity matters more than pixel-level differences, such as detecting scene changes or identifying unique moments.
OpenCV ORB (Oriented FAST and Rotated BRIEF) takes a computer vision approach, using feature detection to identify and match key points between consecutive frames without requiring external API calls. ORB detects key points and computes binary descriptors for each frame, calculating the similarity score as the ratio of matched features to total key points. With a default threshold of 0.325 (where higher values indicate higher similarity), this method offers fast processing with minimal latency and no additional API costs. The rotation-invariant feature matching makes it excellent for detecting camera movement and frame transitions. However, it can be sensitive to significant lighting changes and may not capture semantic similarity as effectively as embedding-based approaches. This method is recommended for static camera scenarios like surveillance footage, or cost-sensitive applications where pixel-level similarity is sufficient.
Shot-based workflow: understanding narrative flow
Instead of sampling individual frames, the shot-based workflow segments video into short clips (shots) or fixed-duration segments and applies video understanding foundation models to each segment. This approach captures temporal context within each shot while maintaining the flexibility to process longer videos.
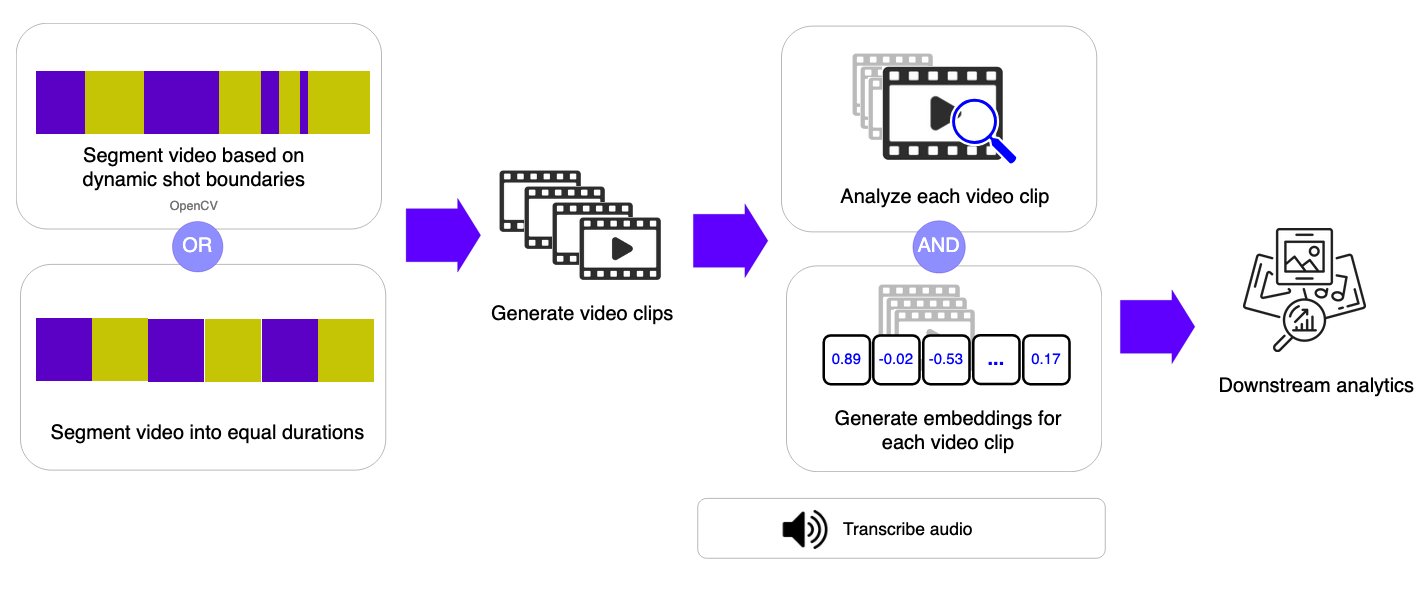
By generating both semantic labels and embeddings for each shot, this method enables efficient video search and retrieval while balancing accuracy and flexibility. The architecture groups shots into batches of 10 for parallel processing in subsequent steps, improving throughput while managing AWS Lambda concurrency limits.
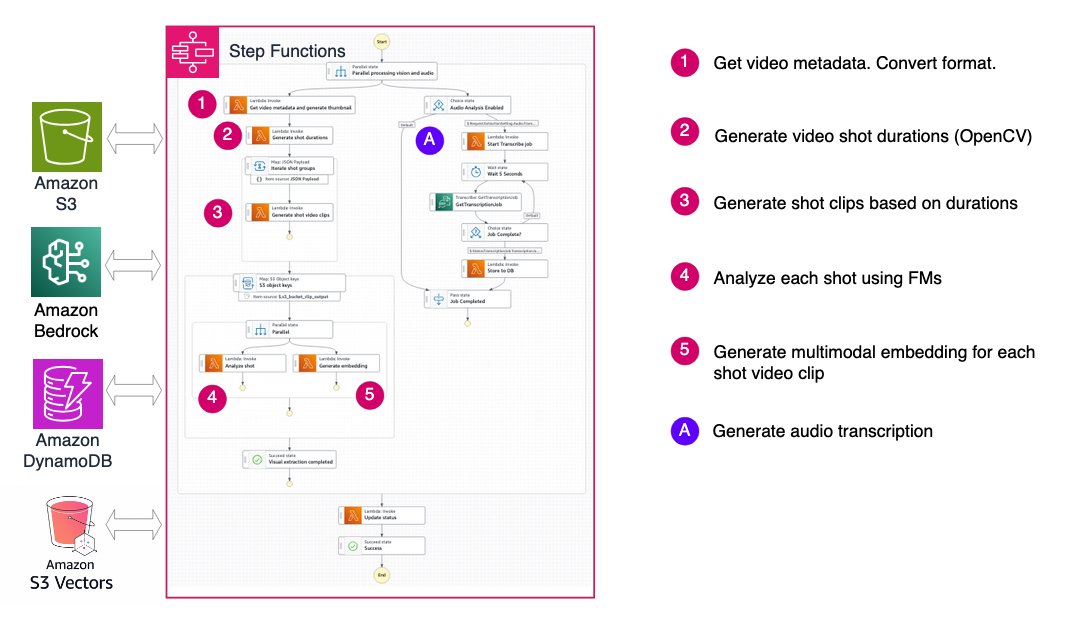
This workflow excels at:
- Media production: Analyze footage for chapter markers and scene descriptions
- Content cataloging: Automatically tag and organize video libraries
- Highlight generation: Identify key moments in long-form content
Video segmentation: two approaches
The shot-based workflow provides flexible segmentation options to match different video characteristics and use cases. The system downloads the video file from Amazon Simple Storage Service (Amazon S3) to temporary storage in AWS Lambda, then applies the selected segmentation algorithm based on the configuration parameters.
OpenCV Scene Detection automatically divides a video into segments based on visual changes in the content. This approach uses the PySceneDetect library to detect transitions such as cuts, camera changes, or significant shifts in visual content.
By identifying natural scene boundaries, the system keeps related moments grouped together. This makes the method particularly effective for edited or narrative-driven videos such as movies, TV shows, presentations, and vlogs, where scenes represent meaningful units of content. Because segmentation follows the structure of the video itself, segment lengths can vary depending on the pacing and editing style.
Fixed-Duration Segmentation divides a video into equal-length time intervals, regardless of what is happening in the video.
Each segment covers a consistent duration (for example, 10 seconds), creating predictable and uniform clips. This approach streamlines processing and improves processing time and cost estimations. Although it might split scenes mid-action, fixed-duration segmentation works well for continuous recordings such as surveillance footage, sports events, or live streams, where regular time sampling is more important than preserving narrative boundaries.
Multimodal embedding: semantic video search
Multimodal embedding represents an emerging approach to video understanding, particularly powerful for video semantic search applications. The solution offers workflows using Amazon Nova Multimodal Embedding and TwelveLabs Marengo models available on Amazon Bedrock.
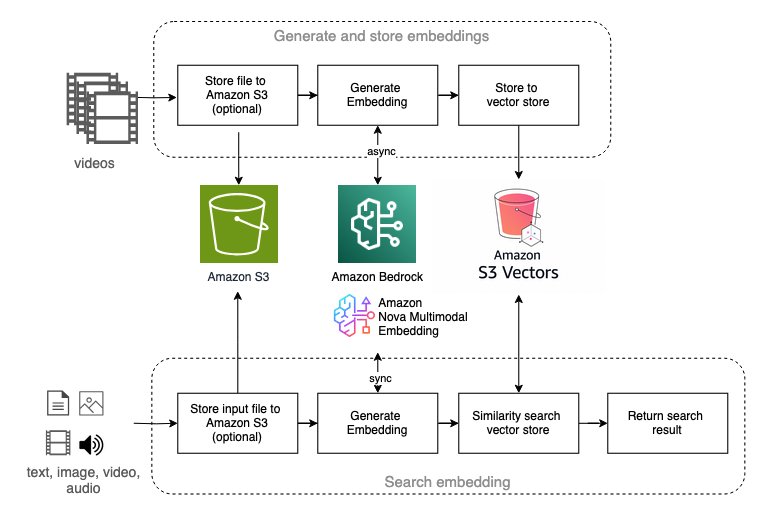
These workflows enable:
- Natural language search: Find video segments using text queries
- Visual similarity search: Locate content using reference images
- Cross-modal retrieval: Bridge the gap between text and visual content
The architecture supports both embedding models with a unified interface:
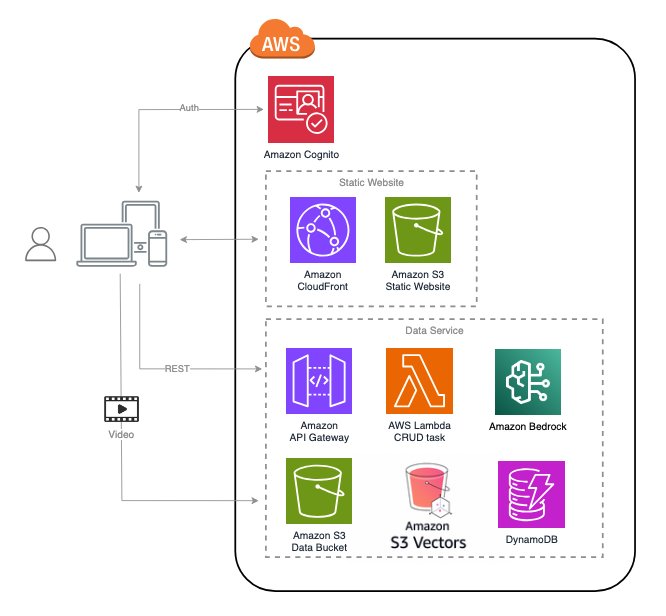
Understanding cost and performance trade-offs
One of the key challenges in production video analysis is managing costs while maintaining quality. The solution provides built-in token usage tracking and cost estimation to help you make informed decisions about model selection and workflow configuration.
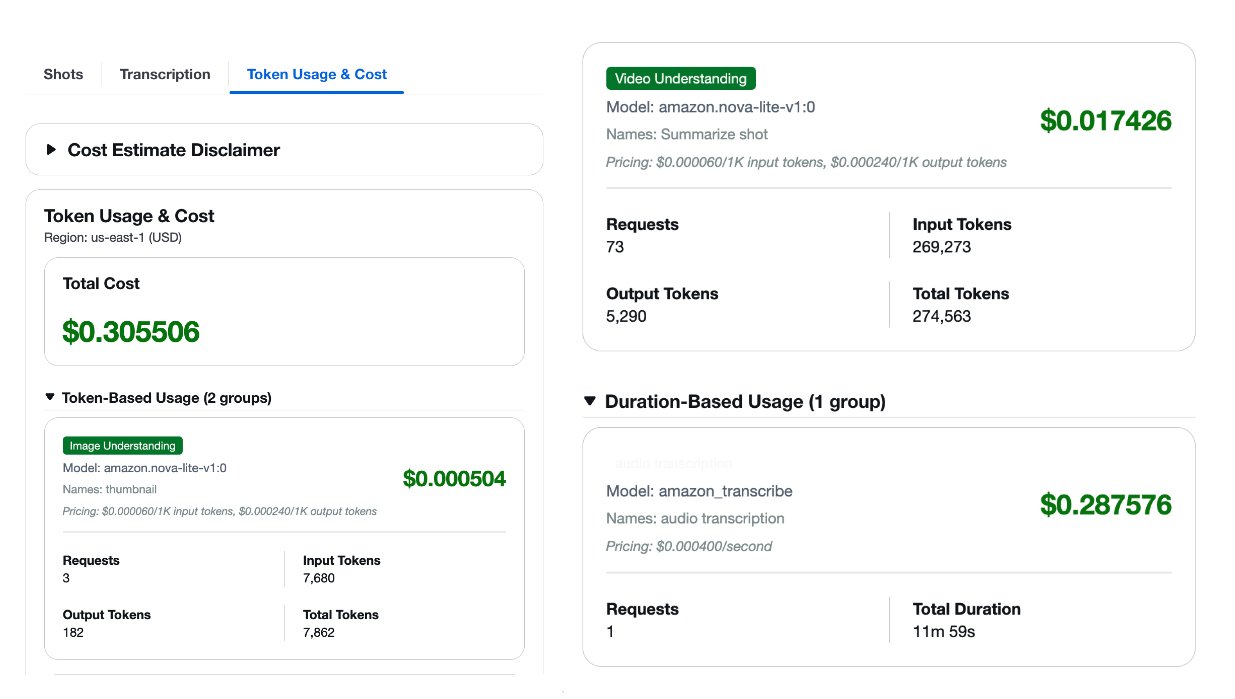
The previous screenshot shows a sample cost estimate generated by the solution to illustrate the format. It should not be used as a pricing source.For each processed video, you receive a detailed cost breakdown by model type, covering Amazon Bedrock foundation models and Amazon Transcribe for audio transcription. With this visibility, you can improve your configuration based on your specific requirements and budget constraints.
System architecture
The complete solution is built on AWS serverless services, providing scalability and cost-efficiency:
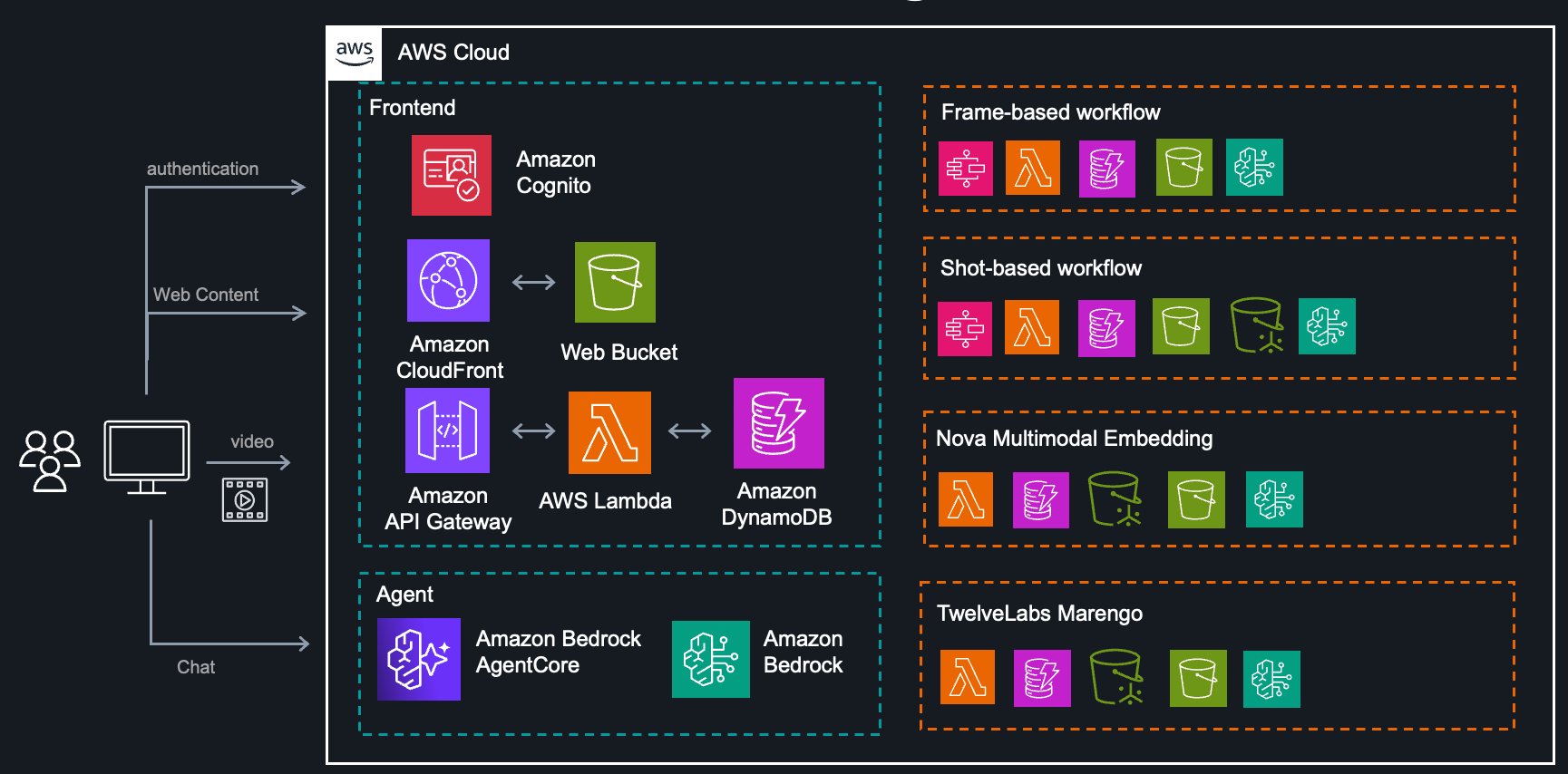
The architecture includes:
- Extraction Service: Orchestrates frame-based and shot-based workflows using Step Functions
- Nova Service: Backend for Nova Multimodal Embedding with vector search
- TwelveLabs Service: Backend for Marengo embedding models with vector search
- Agent Service: AI assistant powered by Amazon Bedrock Agents for workflow recommendations
- Frontend: React application served using Amazon CloudFront for user interaction
- Analytics Service: Sample notebooks demonstrating downstream analysis patterns
Accessing your video metadata
The solution stores extracted metadata in multiple formats for flexible access:
- Amazon S3: Raw foundation model outputs, complete task metadata, and processed assets organized by task ID and data type.
- Amazon DynamoDB: Structured, queryable data optimized for retrieval by video, timestamp, or analysis type across multiple tables for different services.
- Programmatic API: Direct invocation for automation, bulk processing, and integration into existing pipelines.
You can use this flexible access model to integrate the tool into your workflows—whether conducting exploratory analysis in notebooks, building automated pipelines, or developing production applications.
Real-world use cases
The solution includes sample notebooks demonstrating three common scenarios:
- IP Camera Event Detection: Automatically monitor surveillance footage for specific events or conditions without constant human oversight.
- Media Chapter Analysis: Segment long-form video content into logical chapters with automatic descriptions and metadata.
- Social Media Content Moderation: Review user-generated video content at scale to ensure that platform guidelines are met.
These examples provide starting points that you can extend and customize for your specific use cases.
Getting started
Deploy the solution
The solution is available as a CDK package on GitHub and can be deployed to your AWS account with only a few commands. The deployment creates all necessary resources including:
- Step Functions state machines for orchestration
- Lambda functions for processing logic
- DynamoDB tables for metadata storage
- S3 buckets for asset storage
- CloudFront distribution for the web interface
- Amazon Cognito user pool for authentication
After deployment, you can immediately start uploading videos, experimenting with different analysis pipelines and foundation models, and comparing performance across configurations.
Conclusion
Video understanding is no longer limited to organizations with specialized computer vision teams and infrastructure. The multimodal foundation models of Amazon Bedrock, combined with AWS serverless services, make sophisticated video analysis accessible and cost-effective.Whether you’re building security monitoring systems, media production tools, or content moderation platforms, the three architectural approaches demonstrated in this solution provide flexible starting points designed for different requirements. The key is choosing the right approach for your use case: frame-based for precision monitoring, shot-based for narrative content, and embedding-based for semantic search.As multimodal models continue to evolve, we will see even more sophisticated video understanding capabilities emerge. The future is about AI that doesn’t only see video frames, but truly understands the story they tell.
Ready to get started?
- Try the hands-on workshop for guided learning
- Explore the GitHub repository for deployment instructions and source code
