
The Ukrainian president has underlined they will not give up territory to Russia ahead of a meeting between Trump and Putin.

The Ukrainian president has underlined they will not give up territory to Russia ahead of a meeting between Trump and Putin.

Britain’s Labour government on Wednesday announced plans to raise the rate of capital gains tax on sales of shares —…
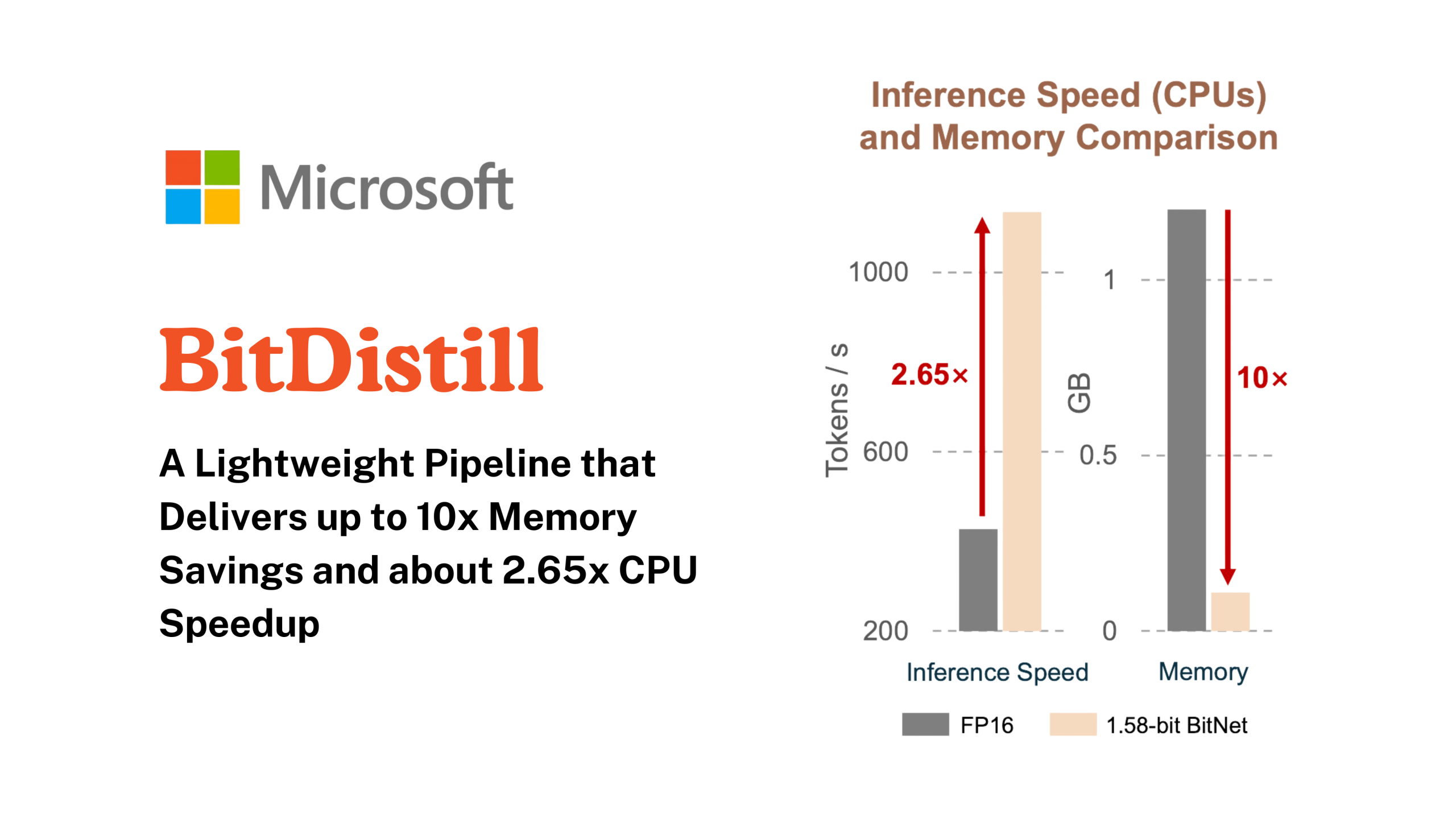
Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific…

President Donald Trump will address the nation at 10:00 p.m. Saturday.