
Reinforcement Learning RL post-training is now a major lever for reasoning-centric LLMs, but unlike pre-training, it hasn’t had predictive scaling rules. Teams pour tens of thousands of GPU-hours into runs without a principled way to estimate whether a recipe will keep improving with more compute. A new research from Meta, UT Austin, UCL, Berkeley, Harvard, and Periodic Labs provides a compute-performance framework—validated over >400,000 GPU-hours—that models RL progress with a sigmoidal curve and supplies a tested recipe, ScaleRL, that follows those predicted curves up to 100,000 GPU-hours.
Fit a sigmoid, not a power law
Pre-training often fits power laws (loss vs compute). RL fine-tuning targets bounded metrics (e.g., pass rate/mean reward). The research team show sigmoidal fits to pass rate vs training compute are empirically more robust and stable than power-law fits, especially when you want to extrapolate from smaller runs to larger budgets. They exclude the very early, noisy regime (~first 1.5k GPU-hours) and fit the predictable portion that follows. The sigmoidal parameters have intuitive roles: one sets the asymptotic performance (ceiling), another the efficiency/exponent, and another the midpoint where gains are fastest.
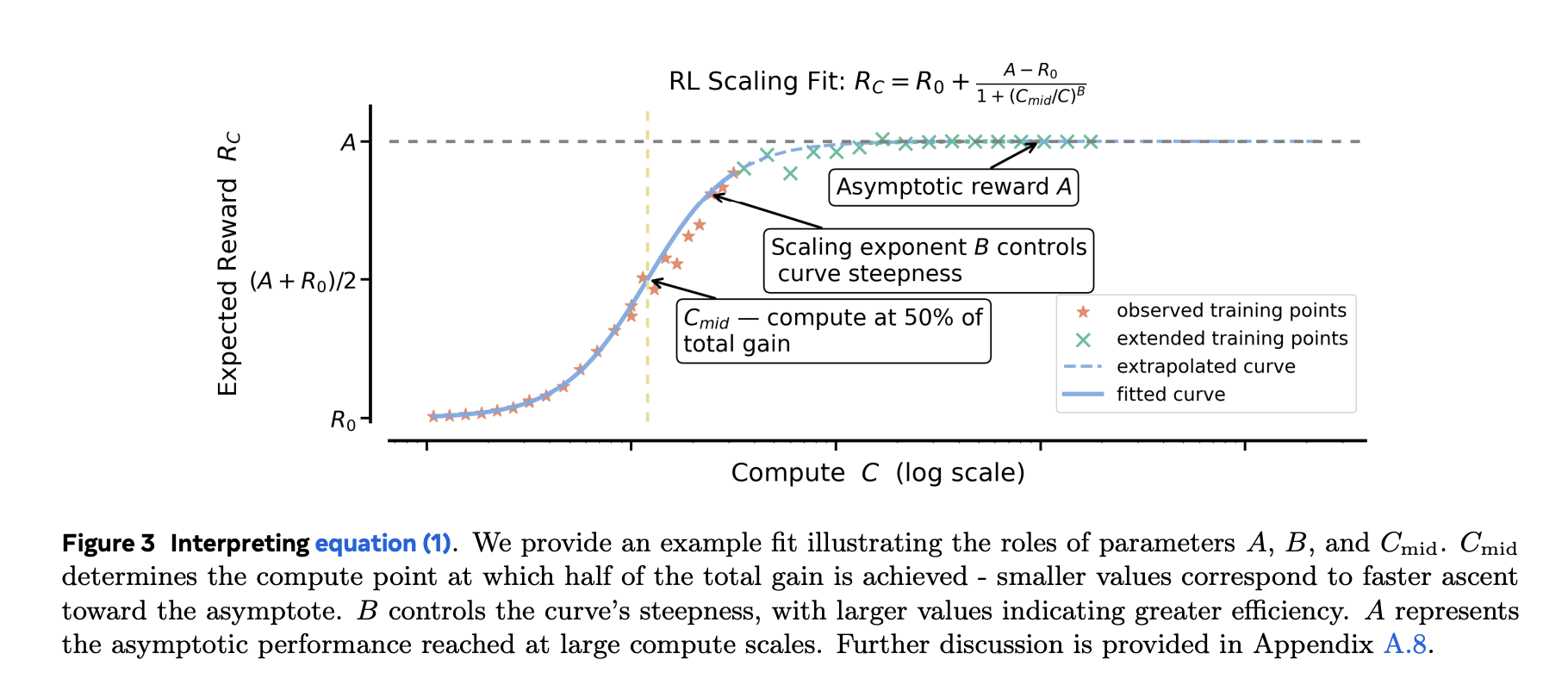
Why that matters: After ~1–2k GPU-hours, you can fit the curve and forecast whether pushing to 10k–100k GPU-hours is worth it—before you burn the budget. The research also shows power-law fits can produce misleading ceilings unless you only fit at very high compute, which defeats the purpose of early forecasting.
ScaleRL: a recipe that scales predictably
ScaleRL is not just new algorithm; it’s a composition of choices that produced stable, extrapolatable scaling in the study:
- Asynchronous Pipeline RL (generator–trainer split across GPUs) for off-policy throughput.
- CISPO (truncated importance-sampling REINFORCE) as the RL loss.
- FP32 precision at the logits to avoid numeric mismatch between generator and trainer.
- Prompt-level loss averaging and batch-level advantage normalization.
- Forced length interruptions to cap runaway traces.
- Zero-variance filtering (drop prompts that provide no gradient signal).
- No-Positive-Resampling (remove high-pass-rate prompts ≥0.9 from later epochs).
The research team validated each component with leave-one-out (LOO) ablations at 16k GPU-hours and show that ScaleRL’s fitted curves reliably extrapolate from 8k → 16k, then hold at much larger scales—including a single run extended to 100k GPU-hours.
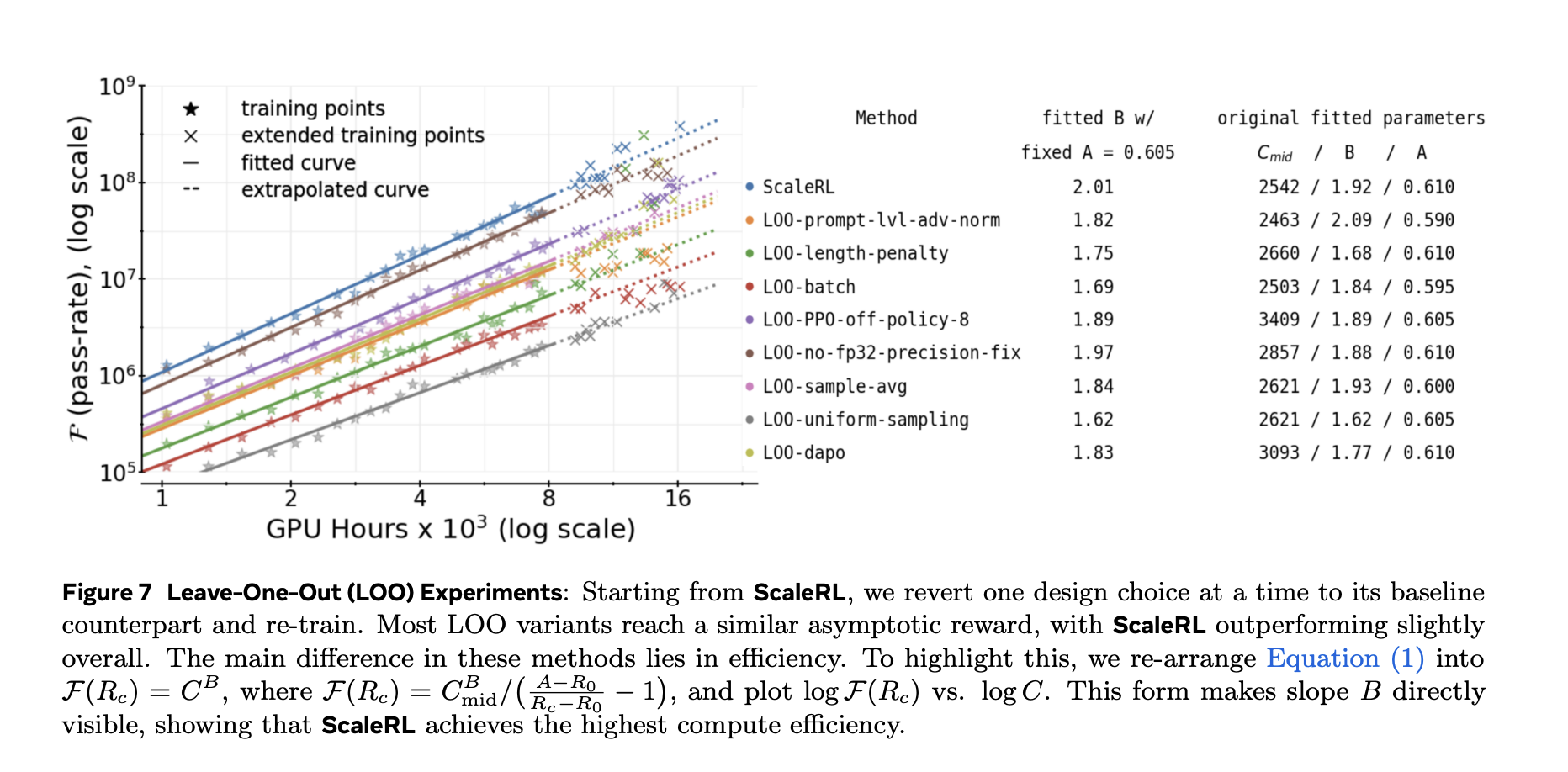
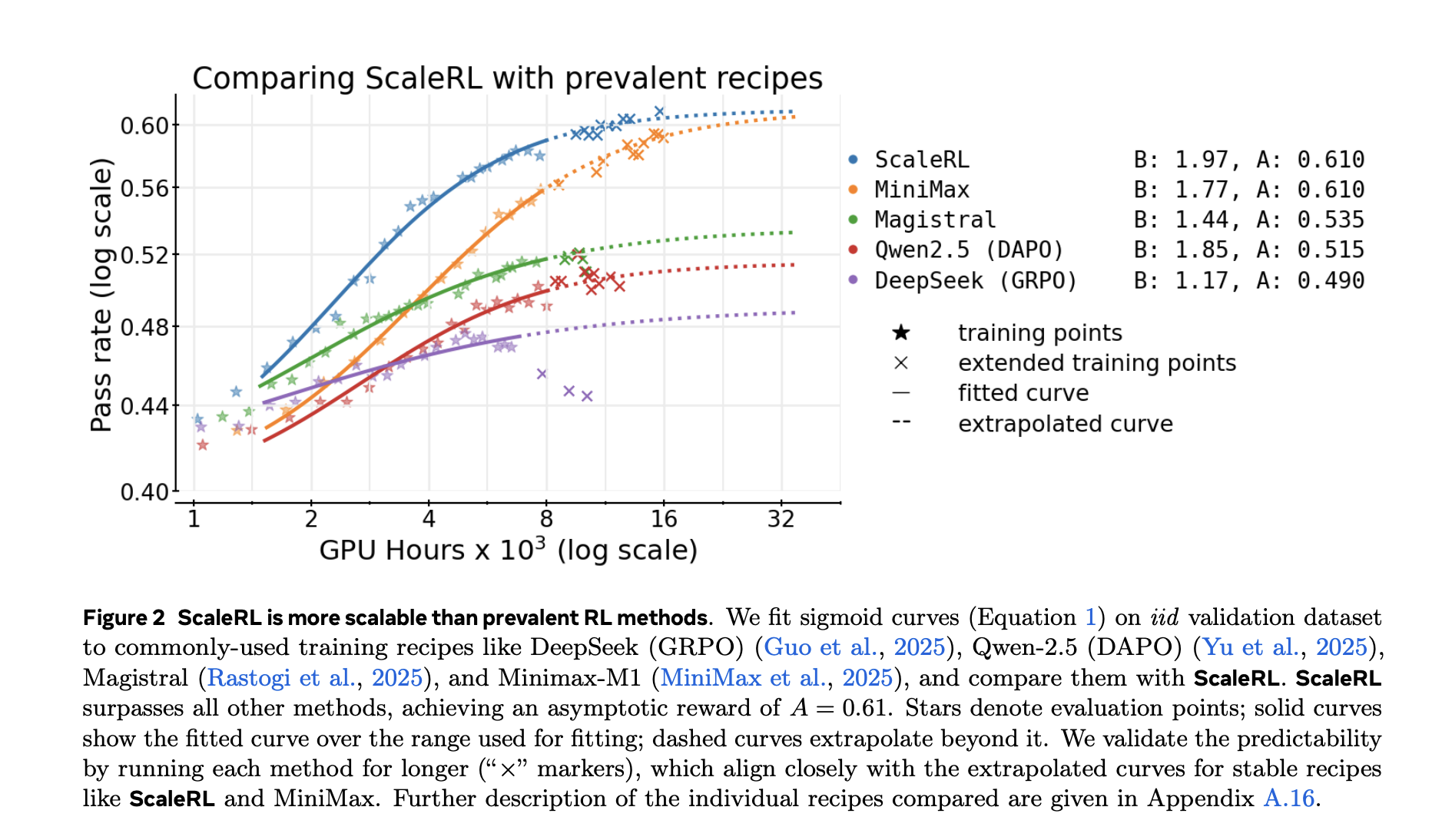
Results and generalization
Two key demonstrations:
- Predictability at scale: For an 8B dense model and a Llama-4 17B×16 MoE (“Scout”), the extended training closely followed the sigmoid extrapolations derived from smaller-compute segments.
- Downstream transfer: Pass-rate improvements on an iid validation set track downstream evaluation (e.g., AIME-24), suggesting the compute-performance curve isn’t a dataset artifact.
The research also compares fitted curves for prevalent recipes (e.g., DeepSeek (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) and reports higher asymptotic performance and better compute efficiency for ScaleRL in their setup.
Which knobs move the ceiling vs the efficiency?
The framework lets you classify design choices:
- Ceiling movers (asymptote): scaling model size (e.g., MoE) and longer generation lengths (up to 32,768 tokens) raise the asymptotic performance but may slow early progress. Larger global batch size can also lift the final asymptote and stabilize training.
- Efficiency shapers: loss aggregation, advantage normalization, data curriculum, and the off-policy pipeline mainly change how fast you approach the ceiling, not the ceiling itself.
Operationally, the research team advises fitting curves early and prioritizing interventions that raise the ceiling, then tune the efficiency knobs to reach it faster at fixed compute.
Key Takeaways
- The research team models RL post-training progress with sigmoidal compute-performance curves (pass-rate vs. log compute), enabling reliable extrapolation—unlike power-law fits on bounded metrics.
- A best-practice recipe, ScaleRL, combines PipelineRL-k (asynchronous generator–trainer), CISPO loss, FP32 logits, prompt-level aggregation, advantage normalization, interruption-based length control, zero-variance filtering, and no-positive-resampling.
- Using these fits, the research team predicted and matched extended runs up to 100k GPU-hours (8B dense) and ~50k GPU-hours (17B×16 MoE “Scout”) on validation curves.
- Ablations show some choices move the asymptotic ceiling (A) (e.g., model scale, longer generation lengths, larger global batch), while others mainly improve compute efficiency (B) (e.g., aggregation/normalization, curriculum, off-policy pipeline).
- The framework provides early forecasting to decide whether to scale a run, and improvements on the in-distribution validation track downstream metrics (e.g., AIME-24), supporting external validity.
Editorial Comments
This work turns RL post-training from trial-and-error into forecastable engineering. It fits sigmoidal compute-performance curves (pass-rate vs. log compute) to predict returns and decide when to stop or scale. It also provides a concrete recipe, ScaleRL, that uses PipelineRL-style asynchronous generation/training, the CISPO loss, and FP32 logits for stability. The study reports >400,000 GPU-hours of experiments and a single-run extension to 100,000 GPU-hours. Results support a clean split: some choices raise the asymptote; others mainly improve compute efficiency. That separation helps teams prioritize ceiling-moving changes before tuning throughput knobs.
Check out the PAPER. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Sigmoidal Scaling Curves Make Reinforcement Learning RL Post-Training Predictable for LLMs appeared first on MarkTechPost.

