

This post is written by Chaim Rand, Principal Engineer, Pini Reisman, Software Senior Principal Engineer, and Eliyah Weinberg, Performance and Technology Innovation Engineer, at Mobileye. The Mobileye team would like to thank Sunita Nadampalli and Guy Almog from AWS for their contributions to this solution and this post.
Mobileye is driving the global evolution toward smarter, safer mobility by combining pioneering AI, extensive real-world experience, a practical vision for the advanced driving systems of today, and the autonomous mobility of tomorrow. Road Experience Management (REM) is a crucial component of Mobileye’s autonomous driving ecosystem. REM is responsible for creating and maintaining highly accurate, crowdsourced high-definition (HD) maps of road networks worldwide. These maps are essential for:
(REM) is a crucial component of Mobileye’s autonomous driving ecosystem. REM is responsible for creating and maintaining highly accurate, crowdsourced high-definition (HD) maps of road networks worldwide. These maps are essential for:
- Precise vehicle localization
- Real-time navigation
- Identifying changes in road conditions
- Enhancing overall autonomous driving capabilities
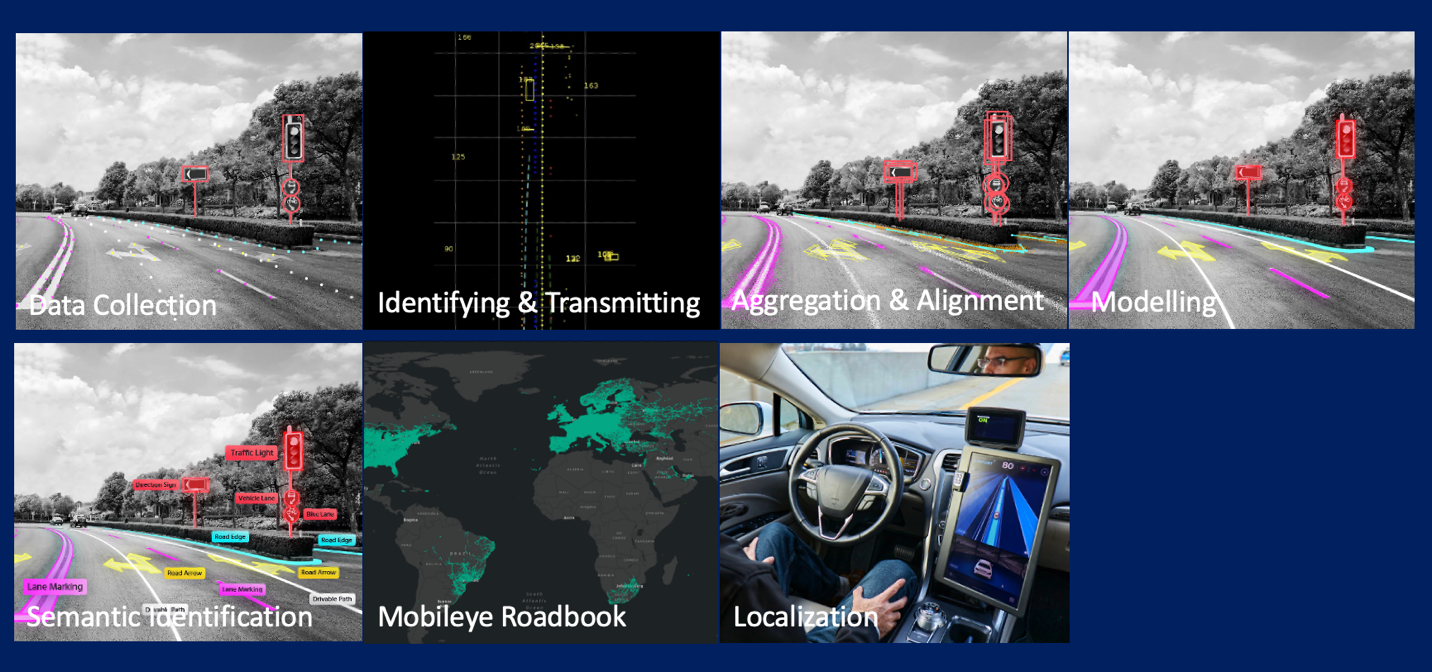
Mobileye Road Experience Management (REM) (Source: https://www.mobileye.com/technology/rem/)
Map generation is a continuous process that requires collecting and processing data from millions of vehicles equipped with Mobileye technology, making it a computationally intensive operation that requires efficient and scalable solutions.
In this post, we focus on one portion of the REM system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will cover the following points:
- The tradeoff between running on GPU compared to CPU, and why our current solution runs on CPU.
- The impact of using a model inference server, specifically Triton Inference Server.
- Running the Change Detection pipeline on AWS Graviton based Amazon Elastic Compute Cloud (Amazon EC2) instances and its impact on deployment flexibility, ultimately resulting more than a 2x improvement in throughput.
We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput.
Road change detection
High-definition maps are one of many components of Mobileye’s solution for autonomous driving that are commonly used by autonomous vehicles (AVs) for vehicle localization and navigation. However, as human drivers know, it is not uncommon for road structure to change. Borrowing a quote often attributed to the Greek philosopher Heraclitus: When it comes to road maps – “The only constant in life is change.” A typical cause of a road change is road construction, when lanes, and their associated lane-markings, may be added, removed, or repositioned.
For human drivers, changes in the road may be inconvenient, but they are usually manageable. But for autonomous vehicles, such changes can pose significant challenges if not properly accounted for. The possibility of road changes requires that the AV systems be programmed with sufficient redundancy and adaptability. It also requires appropriate mechanisms for modifying and deploying corrected REM maps as quickly as possible. The diagram below captures the change detection subsystem in REM that is responsible for identifying changes in the map and, in the case a change is detected, deploying a map update.
 REM Road Change Detection and Map Update flow
REM Road Change Detection and Map Update flow
Change detection is run in parallel and independently on multiple road segments from around the world. It is triggered using a proprietary algorithm that proactively inspects data collected from vehicles equipped with Mobileye technology. The change detection task is typically triggered millions of times a day where each task runs on a separate road segment. Each road segment is evaluated at a minimal, predetermined, cadence.
The main component of the Change Detection task is Mobileye’s proprietary AI model, CDNet, that consumes a proprietary encoding of the data collected from multiple recent drives, along with the current map data, and produces a sequence of outputs that are used to automatically assess whether, in fact, a road change occurred, and determine if remapping is required. Although the full change detection algorithm includes additional components, the CDNet model is the heaviest in terms of its compute and memory requirements. During a single Change Detection task running on a single segment, the CDNet model might be called dozens of times.
Prioritizing cost efficiency
Given the enormous scale of the change detection system, the primary objective we set for ourselves when designing a solution for its deployment was minimizing costs through increasing the average number of completed change detection tasks per dollar. This objective took precedence over other common metrics such as minimizing latency or maximizing reliability. For example, a key component of the deployment solution is reliance on Amazon EC2 Spot Instances for our compute resources, which are best to run fault-tolerant workloads. When running offline processes, we are prepared for the possibility of instance preemption and a delayed algorithm response in order to benefit from the steep discounts of using Spot Instances. As we will explain, prioritizing cost efficiency motivated many of our design decisions.
Architecting a solution
We made the following considerations when designing our architecture.
1. Run Deep Learning inference on CPU instead of GPU
Since the core of the Change Detection pipeline is an AI/ML model, the initial approach was to design a solution based on the use of GPU instances. And indeed, when isolating just the CDNet model inference execution, GPUs demonstrated a significant advantage over CPUs. The following table illustrates the CDNet inference raw performance on CPU compared to GPU.
| Instance type | Samples per second |
| CPU (c7i.4xlarge) | 5.85 |
| GPU (g6e.2xlarge) | 54.8 |
However, we quickly concluded that although CDNet inference would be slower, running it on a CPU instance would improve overall cost efficiency without compromising end-to-end speed, for the following reasons:
- The pricing of GPU instances is generally much higher than CPU instances. Compound that with the fact that, because they are in high demand, GPU instances have much lower Spot availability, and suffer from more frequent Spot preemptions, than CPU instances.
- While CDNet is a primary component, the change detection algorithm includes many more components that are more suited for running on CPU. Although the GPU was extremely fast for running CDNet, it would remain idle for much of the change detection pipeline, thereby reducing its efficiency. Furthermore, running the entire algorithm on CPU reduces the overhead of managing and passing data between different compute resources (using CPU instances for the non-inference work and GPU instances for inference work).
Initial deployment solution
For our initial approach, we designed an auto-scaling solution based on multi-core EC2 CPU Spot Instances processing tasks that are streamed from Amazon Simple Queue Service (Amazon SQS). As change detection tasks were received, they would be scheduled, distributed, and run in a new process on a vacant slot on one of the CPU instances. The instances would be scaled up and down based on the task load.
The following diagrams illustrate the architecture of this configuration.
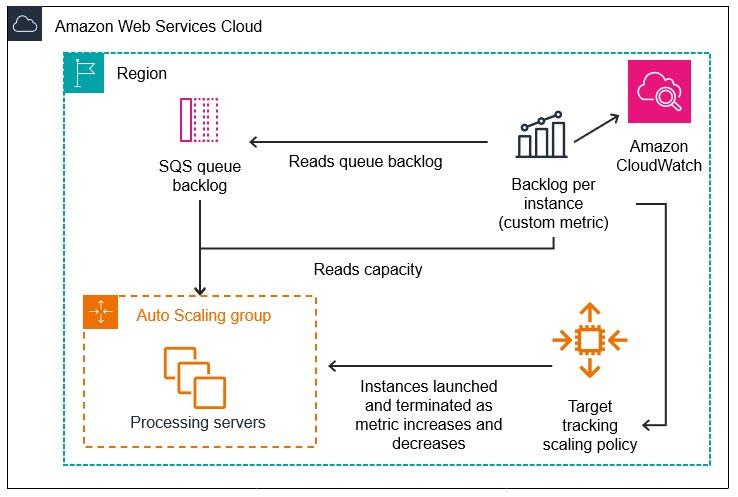
At this stage in development, each process would load and manage its own copy of CDNet. However, this turned out to be a significant and limiting bottleneck. The memory resources required by each process for loading and running its copy of CDNet was 8.5 GB. Assuming for example, that our instance type was a r6i.8xlarge with 256 GB of memory, this implied that we were limited to running just 30 tasks per instance. Moreover, we found that roughly 50% of the total time of a change detection task was spent downloading the model weights and initializing the model.
2. Serve model inference with Triton Inference Server
The first optimization we applied was to centralize the model inference executions using a model inference server solution. Instead of each process maintaining its own copy of CDNet, each CPU worker instance would be initialized with a single (containerized) copy of CDNet managed by an inference server, serving the change detection processes running on the instance. We chose to use Triton Inference Server as our inference server because it is open source, straightforward to deploy, and includes support for multiple runtime environments and AI/ML frameworks.
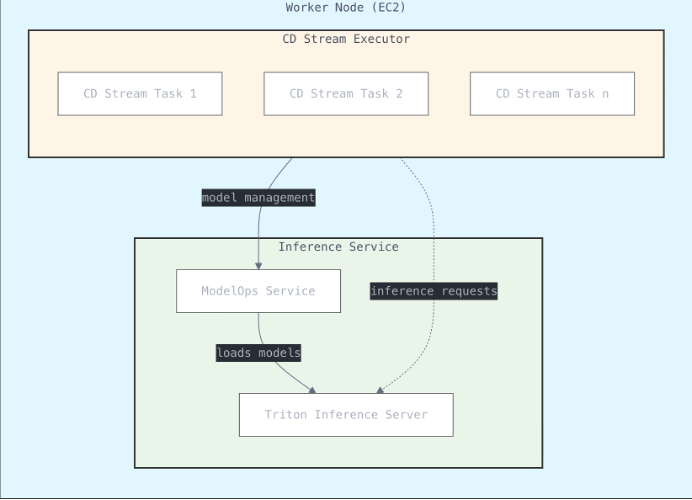
The results of this optimization were profound: The memory footprint of 8.5 GB per process dropped all the way down to 2.5 GB and the average runtime per change detection task dropped from four minutes to two minutes. With removal of the CPU memory bottleneck we could increase the number of tasks per instance up to full CPU utilization. In the case of Change Detection, the optimal number of tasks per 32-vCPU instance turned out to be 32. Overall, this optimization increased efficiency by just over 2x.
The following table illustrates the CDNet Inference performance improvement with centralized Triton Inference Server hosting.
| Memory required per task | Tasks per instance | Average runtime | Tasks per minute | |
| Isolated inference | 8.5 GB | 30 | 4 minutes | 7.5 |
| Centralized inference | 2.5 GB | 32 | 2 minutes | 16 |
We also considered an alternative architecture in which a scalable inference server would run in a separate unit and on independent instances, possibly on GPUs. However, this option was rejected for several reasons:
- Increased latency: Calling CDNet over the network rather than on the same device added significant latency.
- Increased network traffic: The relatively large payload of CDNet significantly increased network traffic, thereby further increasing latency.
We found that the automatic scaling of inference capacity inherent in our solution (using an additional server for each CPU worker instance), was well suited to the inference demand.
Optimizing Triton Inference Server: Reducing Docker image size for leaner deployments
The default Triton image includes support for multiple machine learning backends and both CPU and GPU execution, resulting in a hefty image size of around 15 GB. To streamline this, we rebuilt the Docker image by including only the ML backend we required and restricting execution to CPU-only. The result was a dramatically reduced image size, down to just 2.7 GB. This served to further reduce memory utilization and increase the capacity for additional change detection processes. A smaller image size translates to faster container startup times.
3. Increase instance diversification: Use AWS Graviton instances for better price performance
At peak capacity there are many thousands of change detection tasks running concurrently on a large group of Spot Instances. Inevitably, Spot availability per instance fluctuates. A key to keeping up with the demand is to support a large pool of instance types. Our strong preference was for newer and stronger CPU instances which demonstrated significant benefits both in speed and in cost efficiency compared to other comparable instances. Here is where AWS Graviton presented a significant opportunity.
AWS Graviton is a family of processors designed to deliver the best price performance for cloud workloads running in Amazon EC2. They are also optimized for ML workloads, including Neon vector processing engines, support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions, making them an ideal choice to run our batched deep learning inference workloads for our Change Detection systems. Leading machine learning frameworks such as PyTorch, TensorFlow, and ONNX have been optimized for Graviton processors.
As it turned out, adapting our solution to run on Graviton was straightforward. Most modern AI/ML frameworks including Triton Inference Server include built in support for AWS Graviton. To adapt our solution, we had to make the following changes:
- Create a new Docker image dedicated to running the change detection pipeline on AWS Graviton (ARM architecture).
- Recompile the trimmed down version of Triton Inference Server for Graviton.
- Add Graviton instances to node pool.
Results
By enabling change detection to run on AWS Graviton instances we improved the overall cost efficiency of the change detection sub-system and increased our instance diversification and Spot Instance availability substantially.
1. Increased throughput
To quantify the impact, we can share an example. Suppose that the current task load demands 5,000 compute instances, only half of which can be filled by modern non-Graviton CPU instances. Before adding AWS Graviton to our resource pool, we would need to fill the rest of the demand with older generation CPUs which run 3x slower. Following our instance diversification optimization, we can fill these with AWS Graviton Spot availability. In the case of our example, this doubles the overall efficiency.Finally, in this example, the throughput improvement turns out to exceed 2x, as the runtime performance of CDNet on AWS Graviton instances is often faster than the comparable EC2 instances.
The following table illustrates the CDNet Inference performance improvement with AWS Graviton instances.
| Instance Type | Samples per second |
| AWS Graviton based EC2 instance – r8g.8xlarge | 19.4 |
| Comparable non Graviton CPU instance – 8xlarge | 13.5 |
| Older Generation non Graviton CPU instance – 8xlarge | 6.64 |
With AWS Graviton instances, we could see the following CDNet Inference performance.
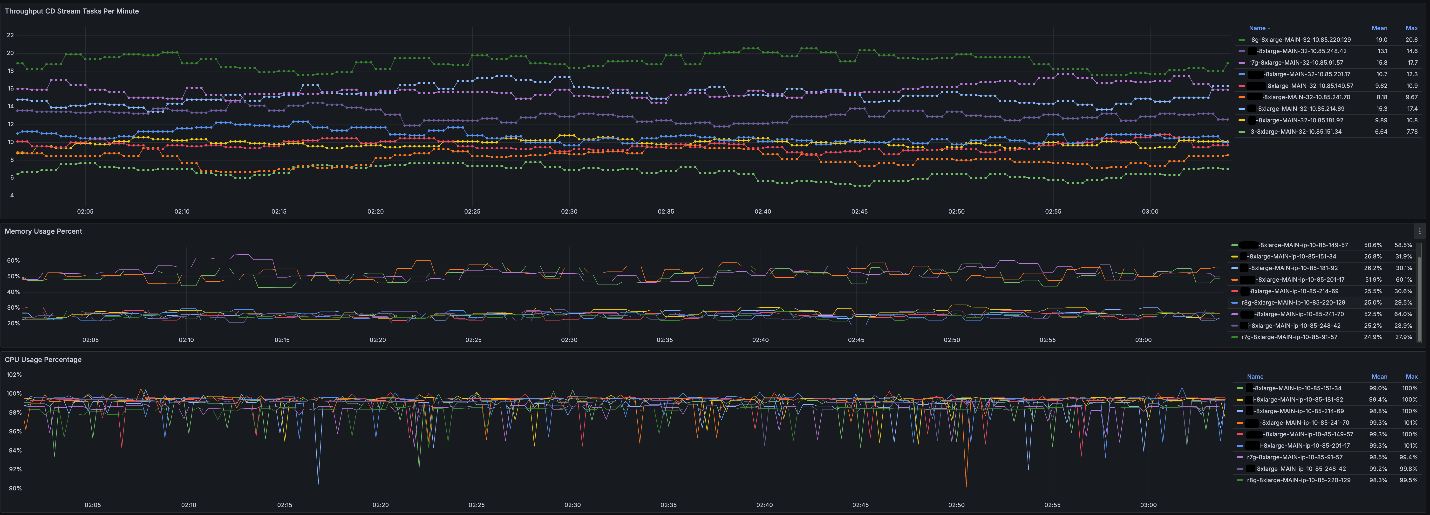
2. Improved user experience
With the Triton Inference Server deployment and increased fleet diversification and instance availability, we have improved our Change Detection system throughput substantially that provides an enhanced user experience for our customers.
3. Experienced seamless migration
Most modern AI/ML frameworks including Triton Inference Server include built in support for AWS Graviton which made adapting our solution to run on Graviton straightforward.
Conclusion
When it comes to optimizing runtime efficiency, the work is not done. There are often more parameters to tune and more flags to apply. AI/ML frameworks and libraries are constantly enhancing and optimizing their support for many different endpoint instance types, particularly AWS Graviton. We expect that with further effort, we will continue to improve on our optimization efforts. We look forward to sharing the next steps in our journey in a future post.For further reading, refer to the following:
- Optimized PyTorch 2.0 Inference with AWS Graviton processors
- AWS Graviton Technical Guide: Machine Learning
About the authors
 Chaim Rand is a Principal Engineer and machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye.
Chaim Rand is a Principal Engineer and machine learning algorithm developer working on deep learning and computer vision technologies for Autonomous Vehicle solutions at Mobileye.
 Pini Reisman is a Software Senior Principal Engineer leading the Performance Engineering and Technological Innovation in the Engineering group in REM – the mapping group in Mobileye.
Pini Reisman is a Software Senior Principal Engineer leading the Performance Engineering and Technological Innovation in the Engineering group in REM – the mapping group in Mobileye.
 Eliyah Weinberg is a Performance and scale optimization and technology innovation engineer at Mobileye REM.
Eliyah Weinberg is a Performance and scale optimization and technology innovation engineer at Mobileye REM.
 Sunita Nadampalli is a Principal Engineer and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open-source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
Sunita Nadampalli is a Principal Engineer and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open-source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
 Guy Almog is a Senior Solutions Architect at AWS, specializing in compute and machine learning. He works with large enterprise AWS customers to design and implement scalable cloud solutions. His role involves providing technical guidance on AWS services, developing high-level solutions, and making architectural recommendations that focus on security, performance, resiliency, cost optimization, and operational efficiency.
Guy Almog is a Senior Solutions Architect at AWS, specializing in compute and machine learning. He works with large enterprise AWS customers to design and implement scalable cloud solutions. His role involves providing technical guidance on AWS services, developing high-level solutions, and making architectural recommendations that focus on security, performance, resiliency, cost optimization, and operational efficiency.

