
Meta AI has introduced Agents Research Environments (ARE), a modular simulation stack for creating and running agent tasks, and Gaia2, a follow-up benchmark to GAIA that evaluates agents in dynamic, write-enabled settings. ARE provides abstractions for apps, environments, events, notifications, and scenarios; Gaia2 runs on top of ARE and focuses on capabilities beyond search-and-execute.
Why move from sequential to asynchronous interaction?
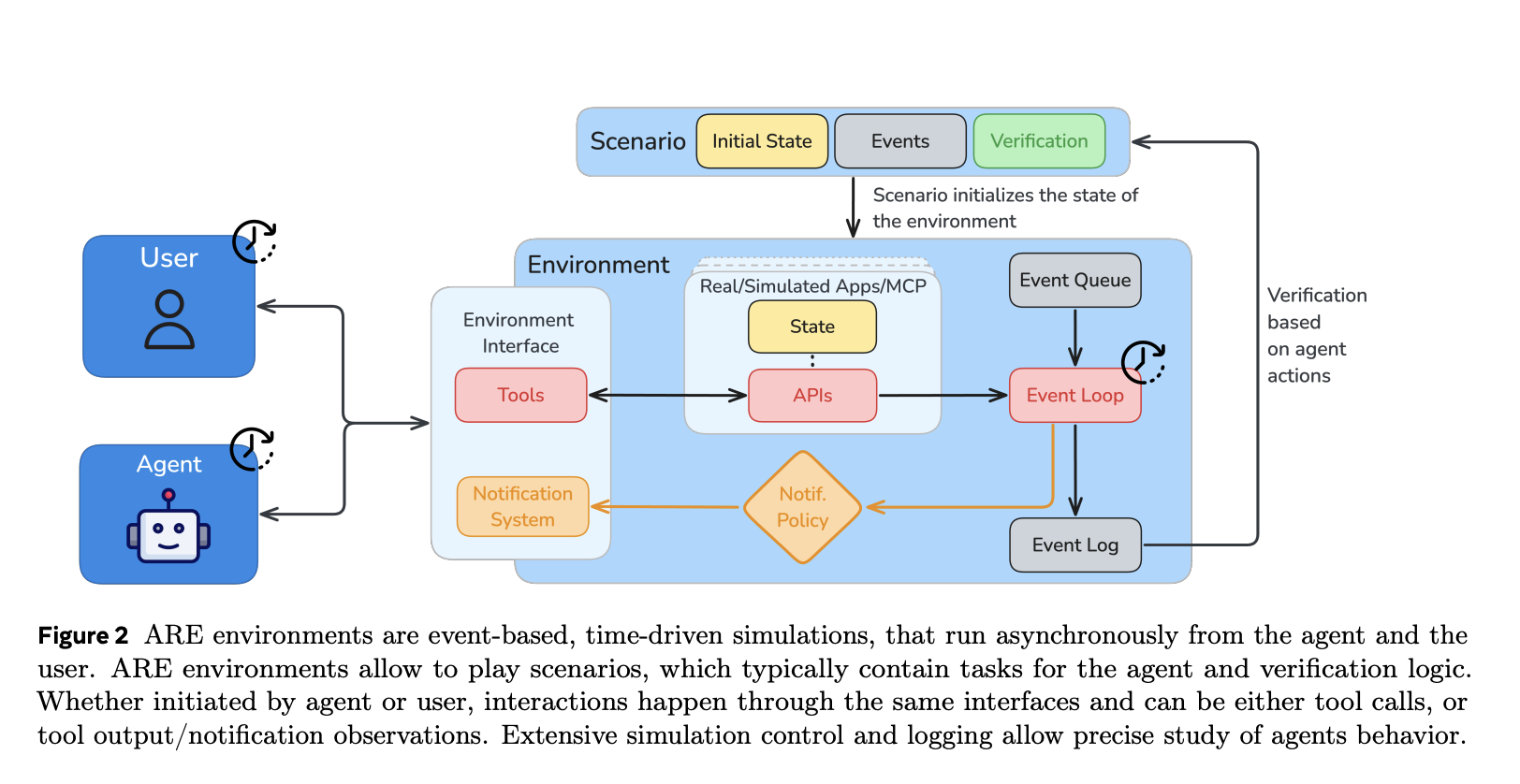
Most prior agent benchmarks pause the world while the model “thinks.” ARE decouples agent and environment time: the environment evolves while the agent is reasoning, injecting scheduled or stochastic events (e.g., replies, reminders, updates). This forces competencies like proactivity, interruption handling, and deadline awareness, which are under-measured in synchronous settings.
How is the ARE platform structured?
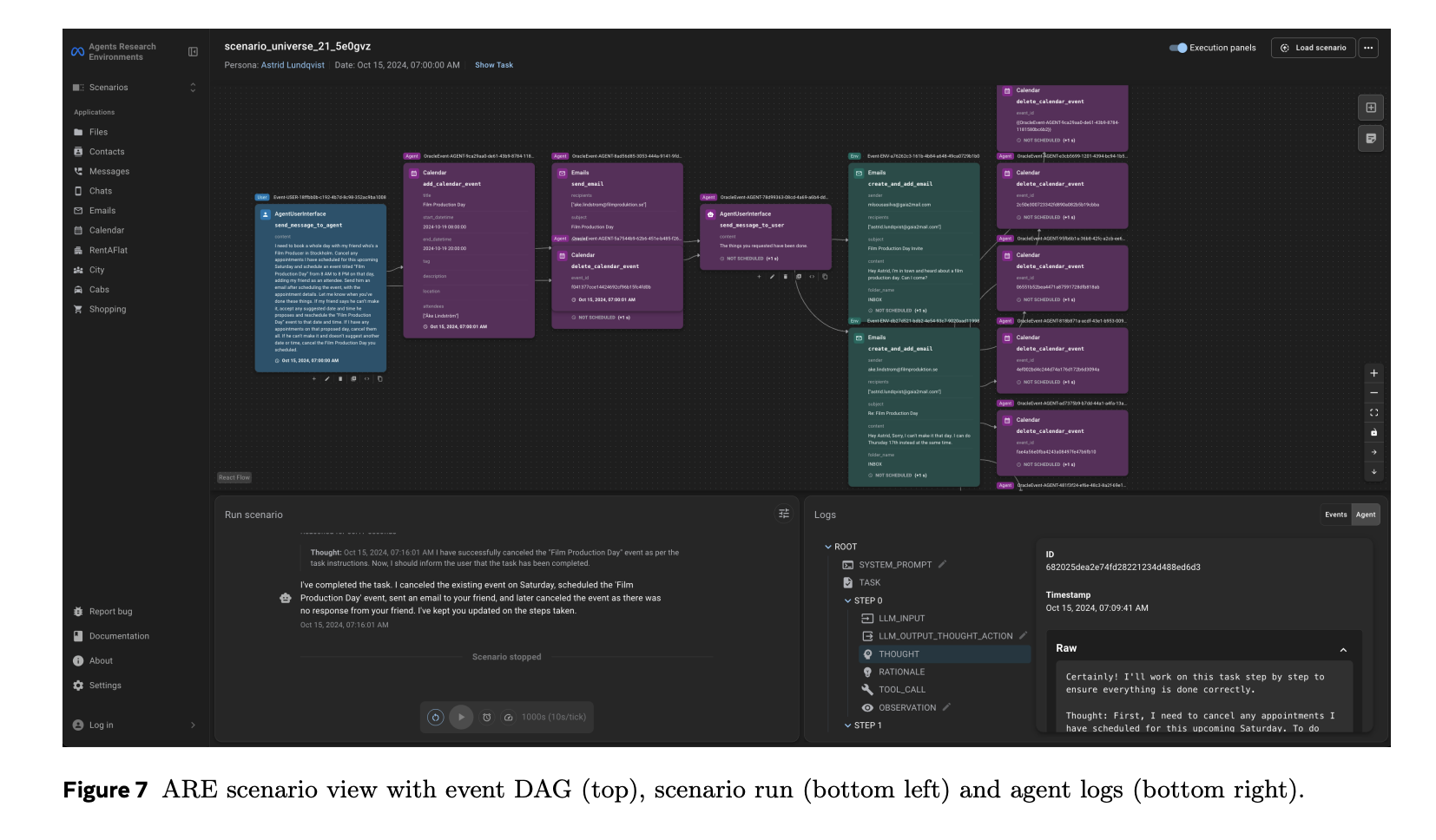
ARE is time-driven and treats “everything as an event.” Five core concepts organize simulations: Apps (stateful tool interfaces), Environments (collections of apps, rules, data), Events (logged happenings), Notifications (configurable observability to the agent), and Scenarios (initial state + scheduled events + verifier). Tools are typed as read or write, enabling precise verification of actions that mutate state. The initial environment, Mobile, mimics a smartphone with apps such as email, messaging, and calendar.
What does Gaia2 actually measure?
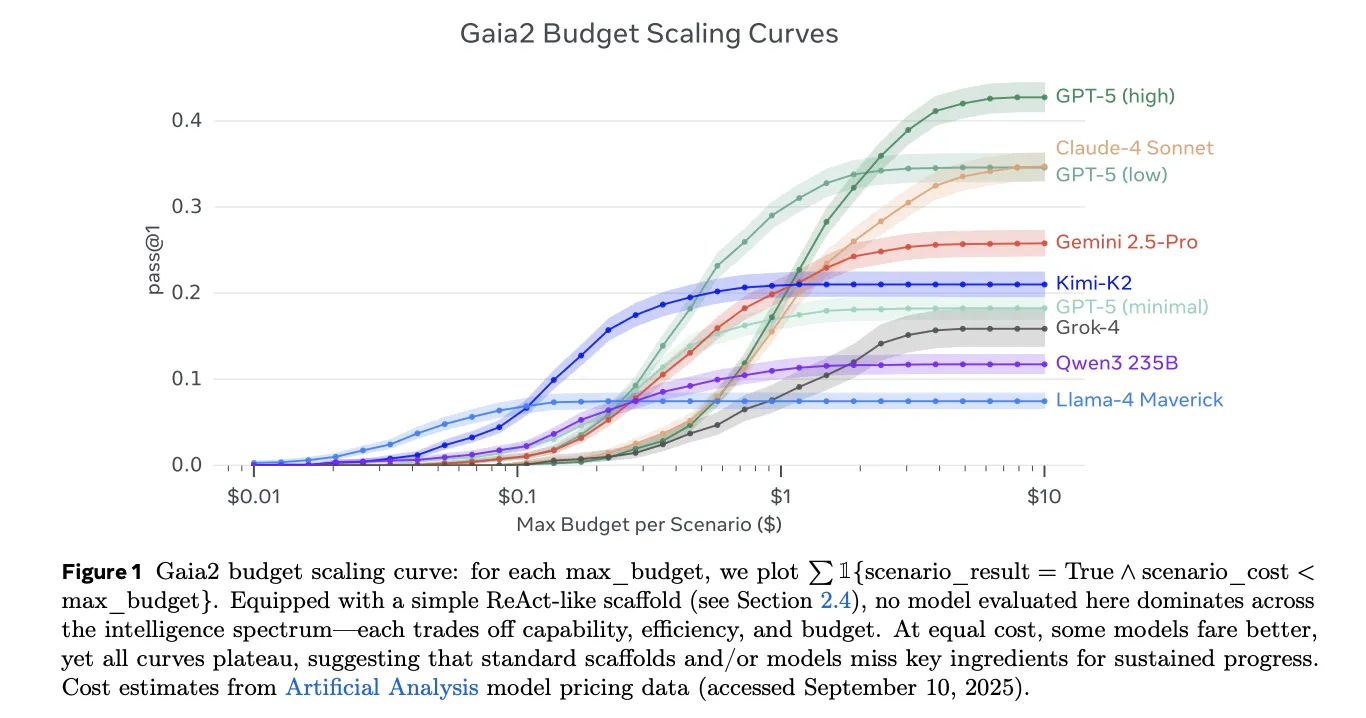
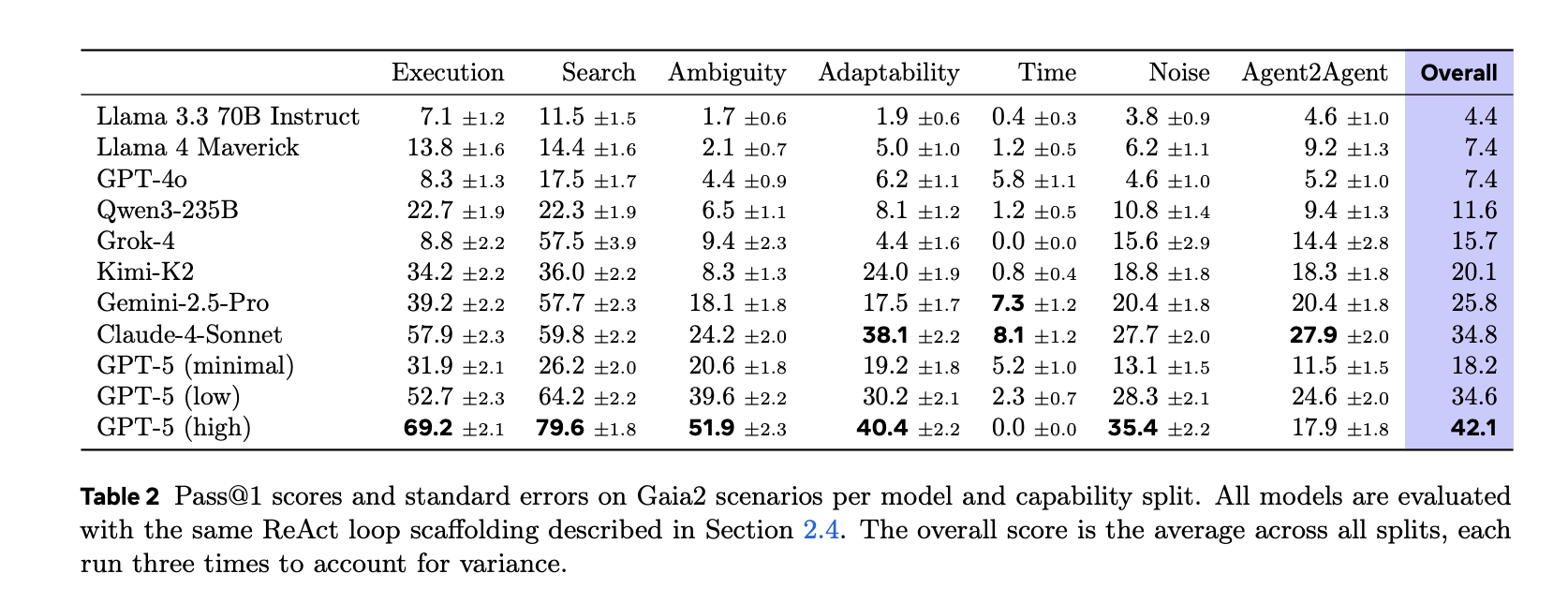
Gaia2 targets general agent capabilities under realistic pressure: adaptability to environment responses, handling of ambiguity, noise robustness, time constraints (actions within tolerances), and Agent-to-Agent collaboration (coordinating sub-agents standing in for apps). Scenarios are verifiable and reproducible via deterministic seeds and oracle traces.
How large is the benchmark—800 or 1,120 scenarios?
The public dataset card specifies 800 scenarios across 10 universes. The paper’s experimental section references 1,120 verifiable, annotated scenarios in the Mobile environment (reflecting extended/augmented configurations used in the study). Practitioners will commonly encounter the 800-scenario release on Hugging Face, with the paper showing how the suite scales.
How are agents scored if the world is changing?
Gaia2 evaluates sequences of write actions against oracle actions with argument-level checks. Arguments are validated via hard (exact) or soft (LLM-judge) comparisons depending on type, maintaining causality and respecting relative-time constraints. This avoids the pitfall of judging only by end state when many trajectories are unsafe or policy-violating.
Summary
ARE + Gaia2 shift the target from static correctness to correctness-under-change. If your agent claims to be production-ready, it should handle asynchrony, ambiguity, noise, timing, and multi-agent coordination—and do so with verifiable write-action traces. This release supplies: a controllable simulator, a challenging benchmark, and a transparent evaluation loop to stress real-world behaviors.
Check out the Paper, GitHub Codes and Technical Details.. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Meta’s ARE + Gaia2 Set a New Bar for AI Agent Evaluation under Asynchronous, Event-Driven Conditions appeared first on MarkTechPost.
