

This post was written with Audra Devoto, Owen Janson, and Christopher Brown of Metagenomi, and Adam Perry of Tennex.
A promising strategy to augment the extensive natural diversity of high value enzymes is to use generative AI, specifically protein language models (pLMs), trained on known enzymes to create orders of magnitude more predicted examples of given enzyme classes. Expanding natural enzyme diversity through generative AI has many advantages, including providing access to numerous enzyme variants that might offer enhanced stability, specificity, or efficacy in human cells—but high throughput generation can be costly depending on the size of the model used and the number of enzyme variants needed.
At Metagenomi, we are developing potentially curative therapeutics with proprietary CRISPR gene editing enzymes. We use the extensive natural diversity of enzymes in our database (MGXdb) to identify natural enzyme candidates, and to train protein language models used for generative AI. Expansion of natural enzyme classes with generative AI allows us to access additional variants of a given enzyme class, which are filtered with multi-model workflows to predict key enzyme characteristics and used to enable protein engineering campaigns to improve enzyme performance in a given context.
In this blog post, we detail methods for cost reduction of high throughput protein generative AI workflows by implementing the Progen2 model on AWS Inferentia, which enabled high throughput generation of enzyme variants with up to 56% lower cost on AWS Batch and Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances. This work was done in partnership with the AWS Neuron team and engineers at Tennex.
Progen2 on AWS Inferentia
PyTorch models can use AWS neuron cores as accelerators, which led us to use AWS Inferentia powered EC2 Inf2 instance types for our high-throughput protein design workflow to use their cost-effectiveness and higher availability as Spot Instances. We chose the autoregressive transformer model Progen2 to implement on EC2 Inf2 instance types, because it met our needs for high throughput synthetic protein generation from fine tuned models based on earlier work running Progen2 on EC2 instances with NVIDIA L40S GPUs (g6e.xlarge), and because there is established support in Neuron for transformer decoder type models. To implement Progen2 on EC2 Inf2 instances, we traced custom Progen2 checkpoints trained on proprietary enzymes using the bucketing technique. Tracing out models to multiple sizes optimizes for model performance by generating sequences on consecutively larger traced models, passing the output of the previous model as a prompt to the next one, which minimizes the inference time required to generate each token.
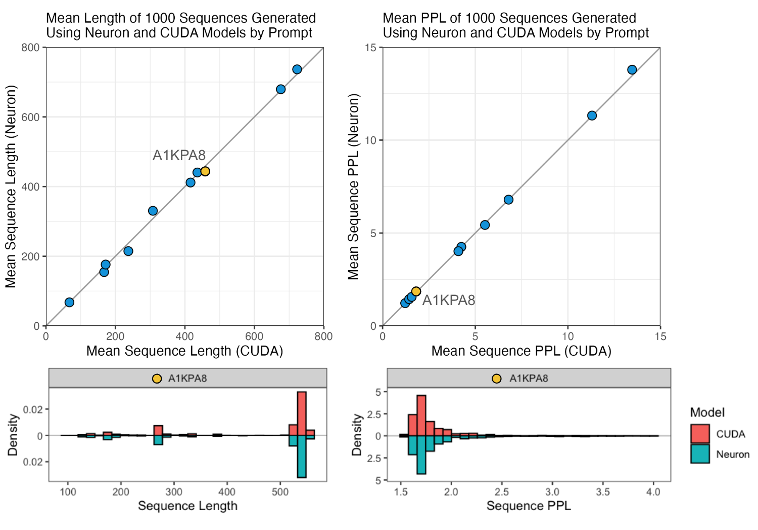
However, the tracing and bucketing approach used to enable Progen2 to run on EC2 Inf2 instance introduces some changes that could impact model accuracy. For example, Progen2-base was not trained with padding tokens, which must be added to input tensors when running on EC2 Inf2 instances. To test the effects of our tracing and bucketing approach, we compared the perplexity and sequence lengths of sequences generated using the progen2-base model on EC2 Inf2 instances to those using the native implementation of the progen2-base model on NVIDIA GPUs.
To test the models, we generated 1,000 protein sequences for each of 10 prompts under both the tracing and bucketing (AWS AI Chip Inferentia) implementation and the native (NVIDIA GPU) implementation. The set of prompts was created by drawing 10 well-characterized proteins from UniprotKB, and truncating each to the first 50 amino acids. To check for abnormalities in the generated sequences, all generated sequences from both models were then run through a forward pass of the native implementation of progen2-base, and the mean perplexity of each sequence was calculated. The following figure illustrates this method.
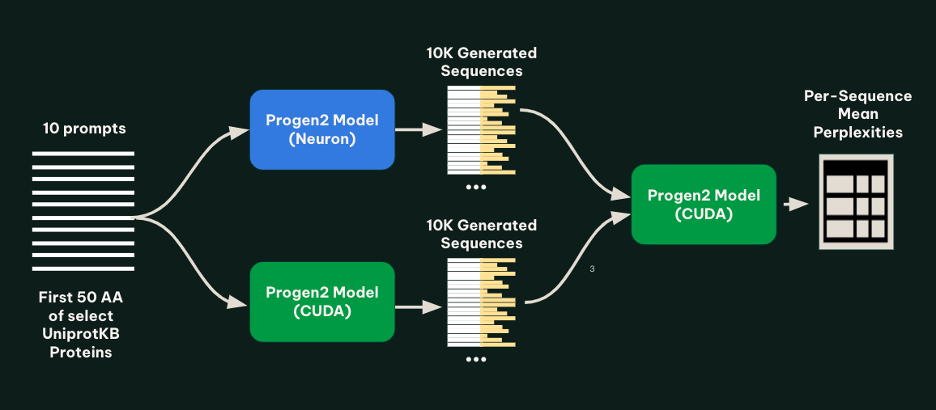
As shown in the following figure, we found that for each prompt, the lengths and perplexities of sequences generated using the tracing and bucketing implementation and native implementation looked similar.
Scaled inference on AWS Batch
With the basic inference logic using Progen2 on EC2 Inf2 instances worked out, the next step was to massively scale inference across a large fleet of compute nodes. AWS Batch was the ideal service to scale this workflow, because it can efficiently run hundreds of thousands of batch computing jobs and dynamically provision to the optimal quantity and type of compute resources (such as Amazon EC2 On-Demand or Spot Instances) based on the volume and resource requirements of the submitted jobs.
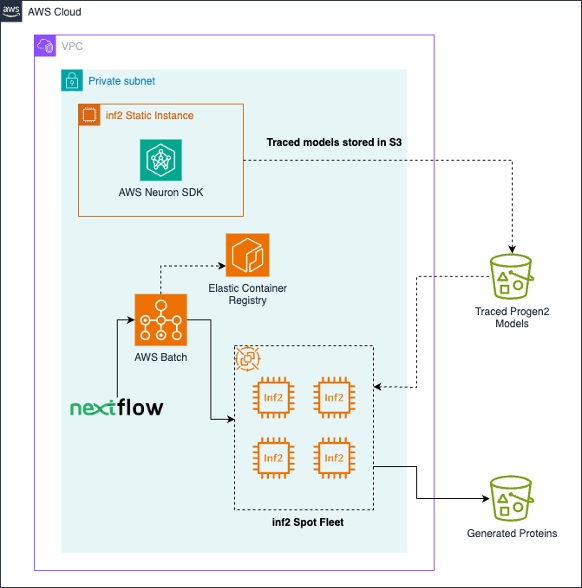
Progen2 was implemented as a batch workload following best practices. Jobs are submitted by a user, and run on a dedicated compute environment that orchestrates Amazon EC2 inf2.xlarge Spot Instances. Custom docker containers are stored on the Amazon Amazon Elastic Container Registry (Amazon ECR). Models are pulled down from Amazon Simple Storage Service (Amazon S3) by each job, and generated sequences in the form of a FASTA file are placed on Amazon S3 at the end of each job. Optionally, Nextflow can be used to orchestrate jobs, handle automatic spot retries, and automate downstream or upstream tasks. The following figure illustrates the solution architecture.
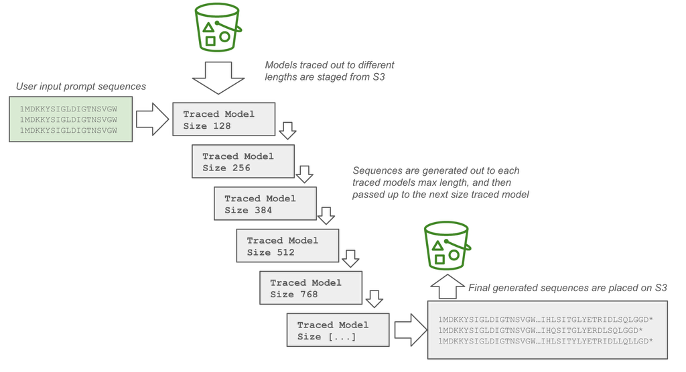
As shown in the following figure, within each individual batch job, sequences are generated by first loading the smallest bucket size from available traced models. Sequences are generated out to the max tokens for that bucket, and sequences that were generated with a stop codon or a start codon are dropped. The remaining unfinished sequences are passed up to subsequently larger bucket sizes for further generation, until the parameter max_length is reached. Tensors are stacked and decoded at the end and written to a FASTA file that is placed on Amazon S3.
The following is an example configuration sketch for setting up an AWS Batch environment using EC2 Inf2 instances that can run Progen2-neuron workloads.
DISCLAIMER: This is sample configuration for non-production usage. You should work with your security and legal teams to adhere to your organizational security, regulatory, and compliance requirements before deployment.
Prerequisites
Before implementing this configuration, make sure you have the following prerequisites in place:
- A Progen2-NeuronContainerImage stored in Amazon ECR
- An AWS Identity and Access Management (IAM) instance role configured with appropriate permissions
- An Amazon Virtual Private Cloud (Amazon VPC) set up
The following is an example Dockerfile for containerizing Progen2-neuron. This container image builds on Amazon Linux 2023 and includes the necessary components for running Progen2 on AWS Neuron—including the Neuron SDK, Python dependencies, PyTorch, and Transformers libraries. It also configures offline mode for Hugging Face operations and includes the required sequence generation scripts.
The following is an example generate_sequences.sh that orchestrates the sequence generation workflow for Progen2 on EC2 Inf2 instances.
Cost comparisons
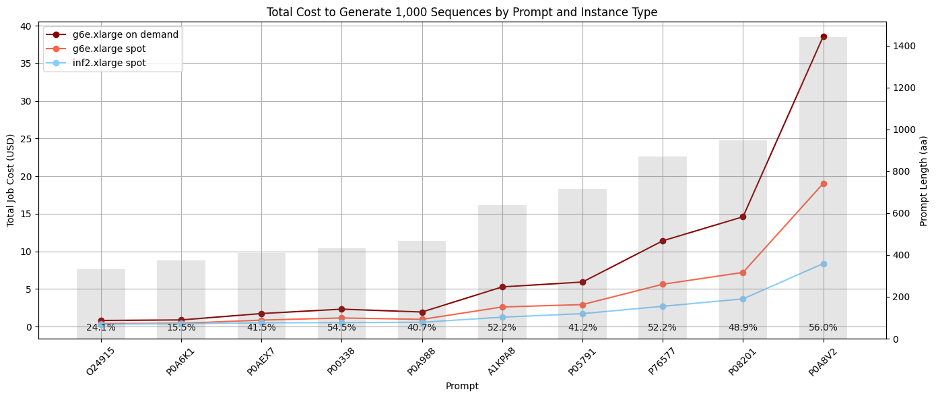
The primary goal of this project was to lower the cost of generating protein sequences with Progen2, so that we could use this model to significantly expand the diversity of multiple enzyme classes. To compare the cost of generating sequences using both services, we generated 10,000 sequences based on prompts derived from 10 common sequences in UniProtKB, using a temperature of 1.0. Batch jobs were run in parallel, with each job generating 100 sequences for a single prompt. We observed that the implementation of Progen2 on EC2 Inf2 Spot Instances was significantly cheaper than implementation on Amazon EC2 G6e Spot Instances for longer sequences, representing savings of up to 56%. These cost estimates include expected Amazon EC2 Spot interruption frequencies of 20% for Amazon EC2 g6e.xlarge instances powered by NVIDIA L40S Tensor Core GPUs and 5% for EC2 inf2.xlarge instances. The following figure illustrates total cost where gray bars represent the average length of generated sequences.
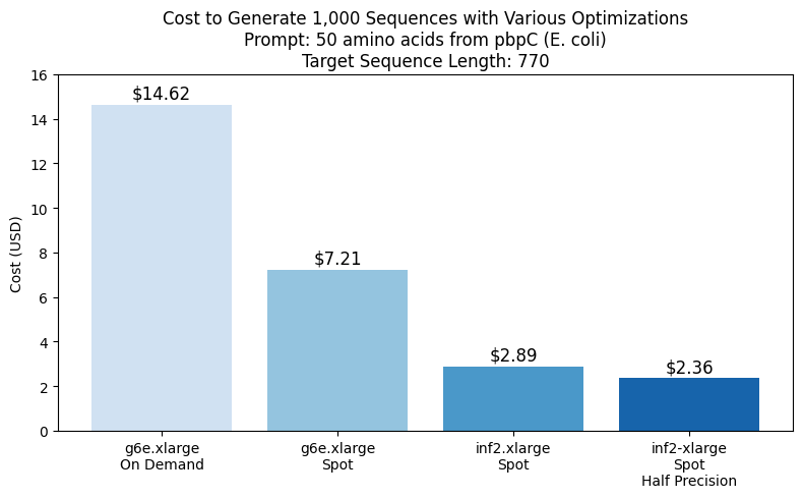
Additional cost savings can be achieved by running jobs at half precision, which appeared to produce equivalent results, as shown in the following figure.
It is important to note that because the time it takes to add new tokens to the sequence during generation scales quadratically, the time and cost to generate sequences is highly dependent on the types of sequences you’re trying to generate. Overall, we observed that the cost to generate sequences depends on the specific model checkpoint used and the distribution of sequence lengths the model generated. For cost estimates, we recommend generating a small subset of enzymes with your chosen model and extrapolating costs for a larger generation set, instead of trying to calculate based on costs for previous experiments.
Scaling generation to millions of proteins
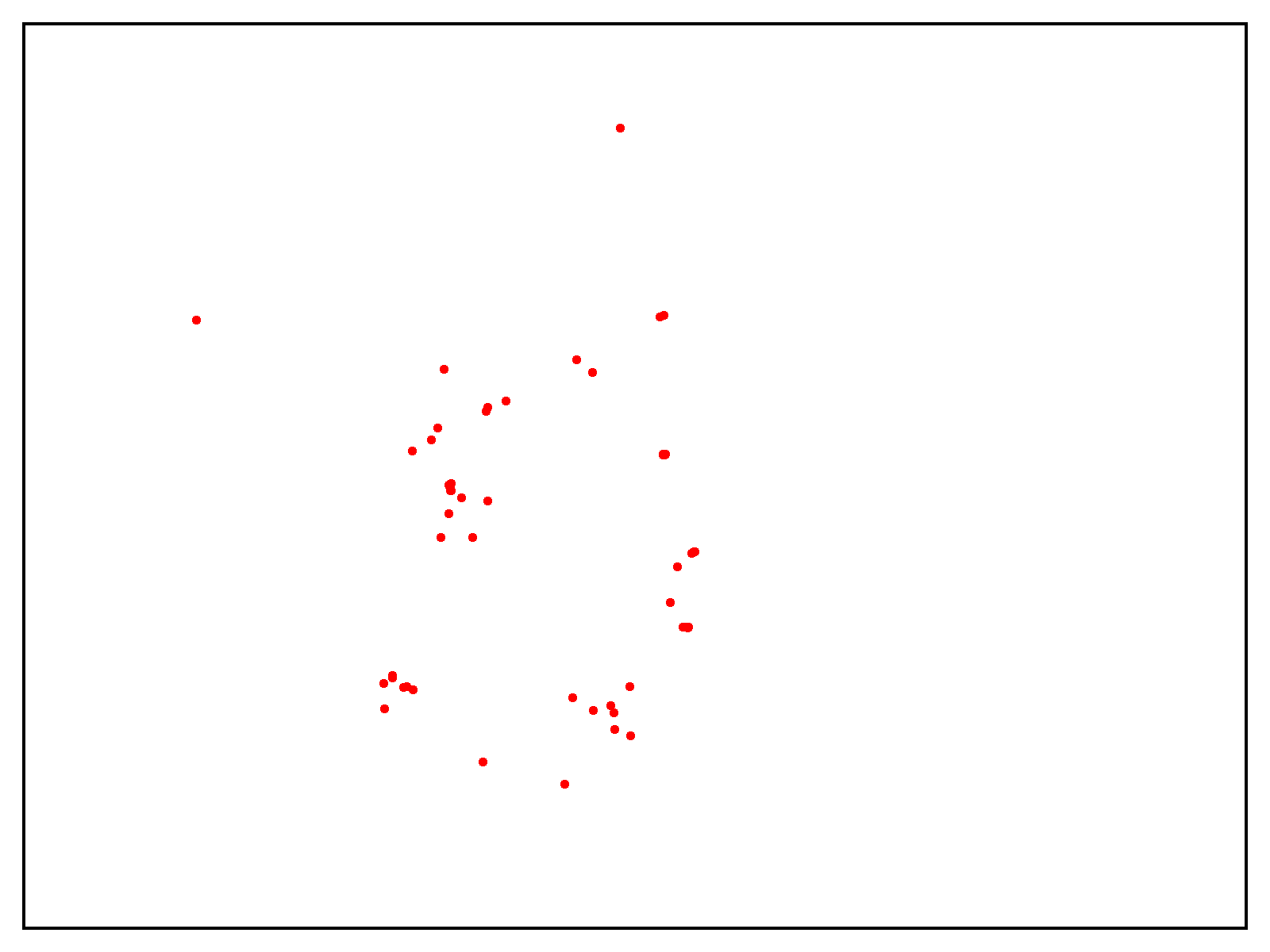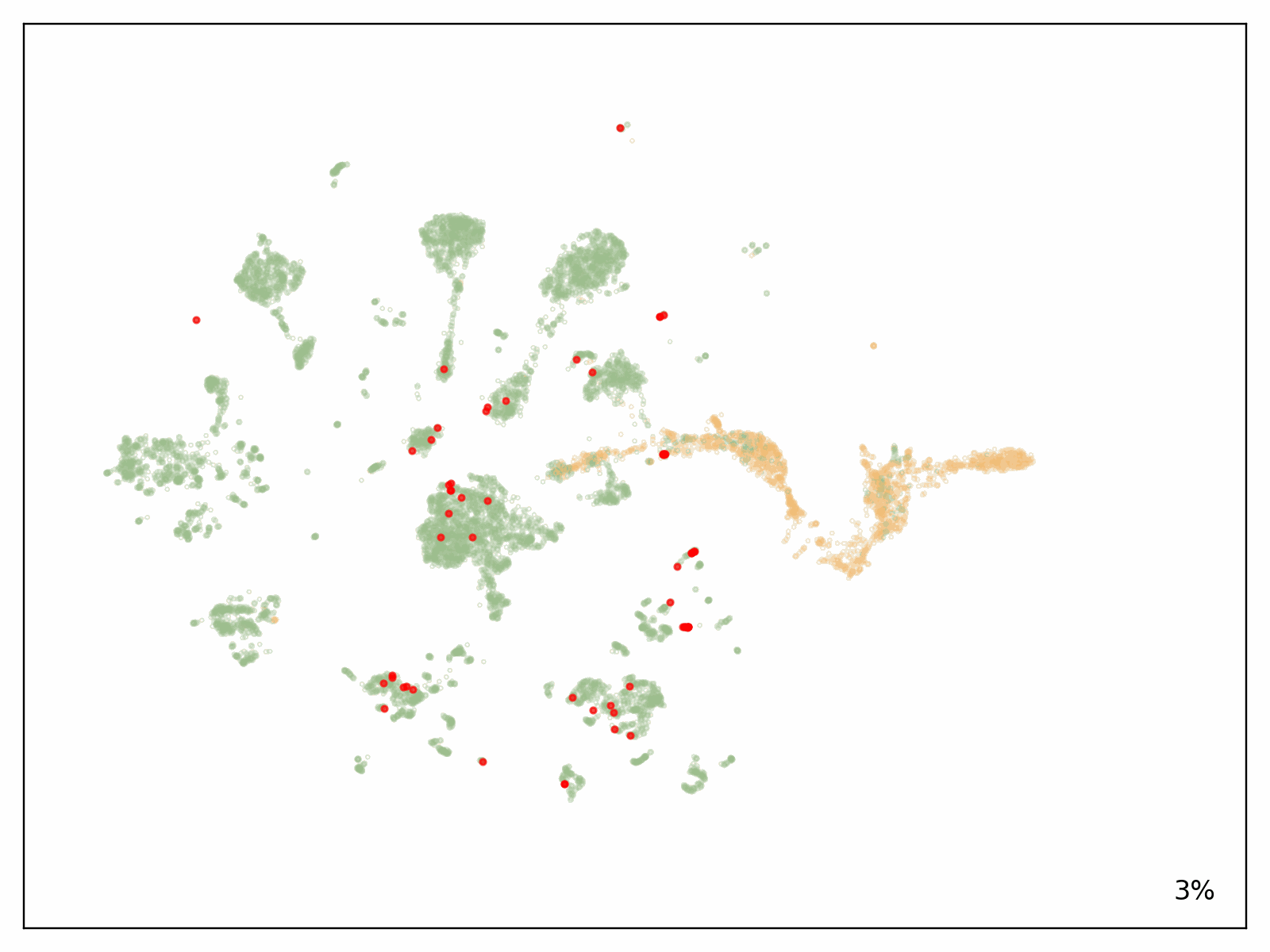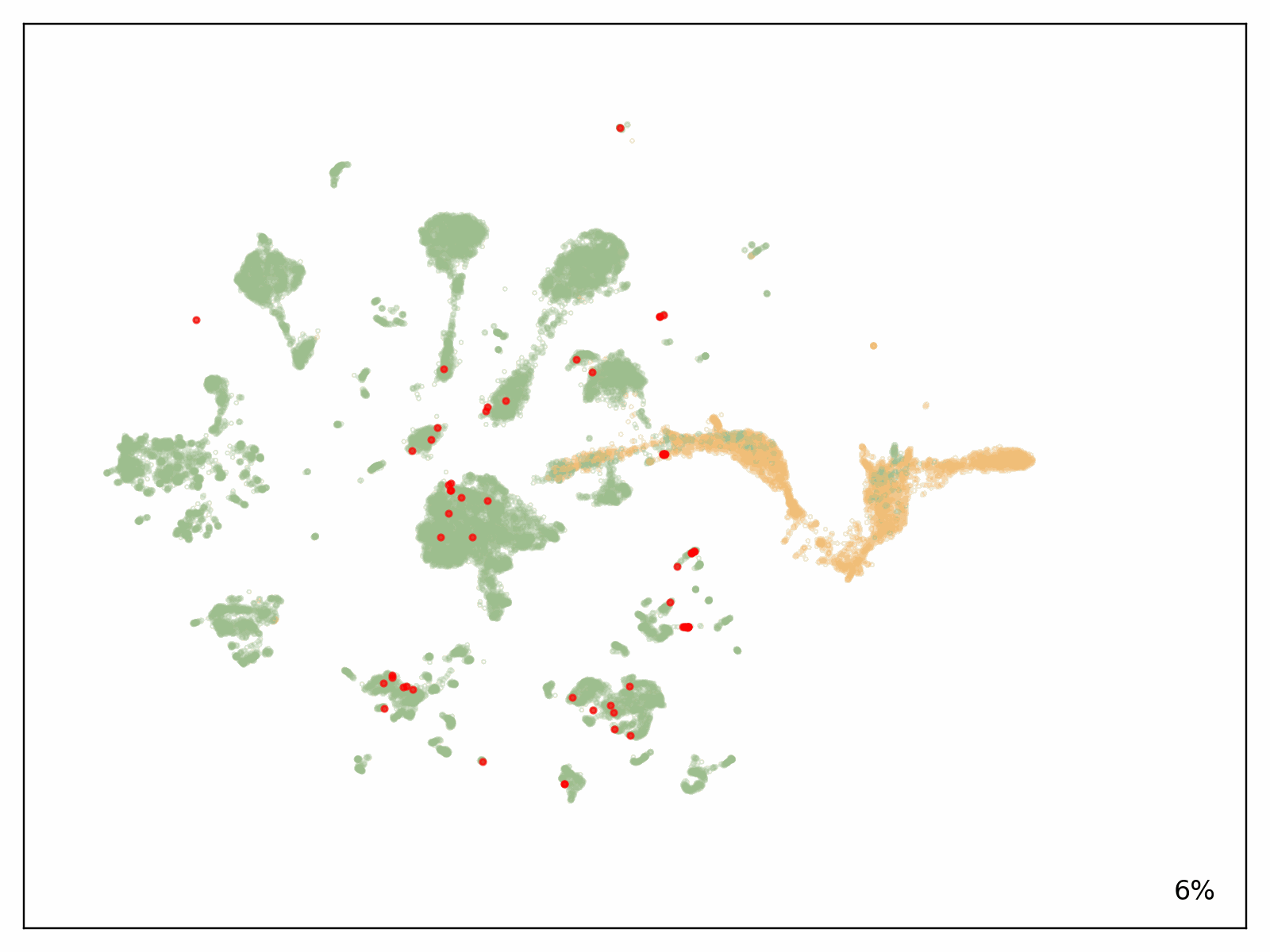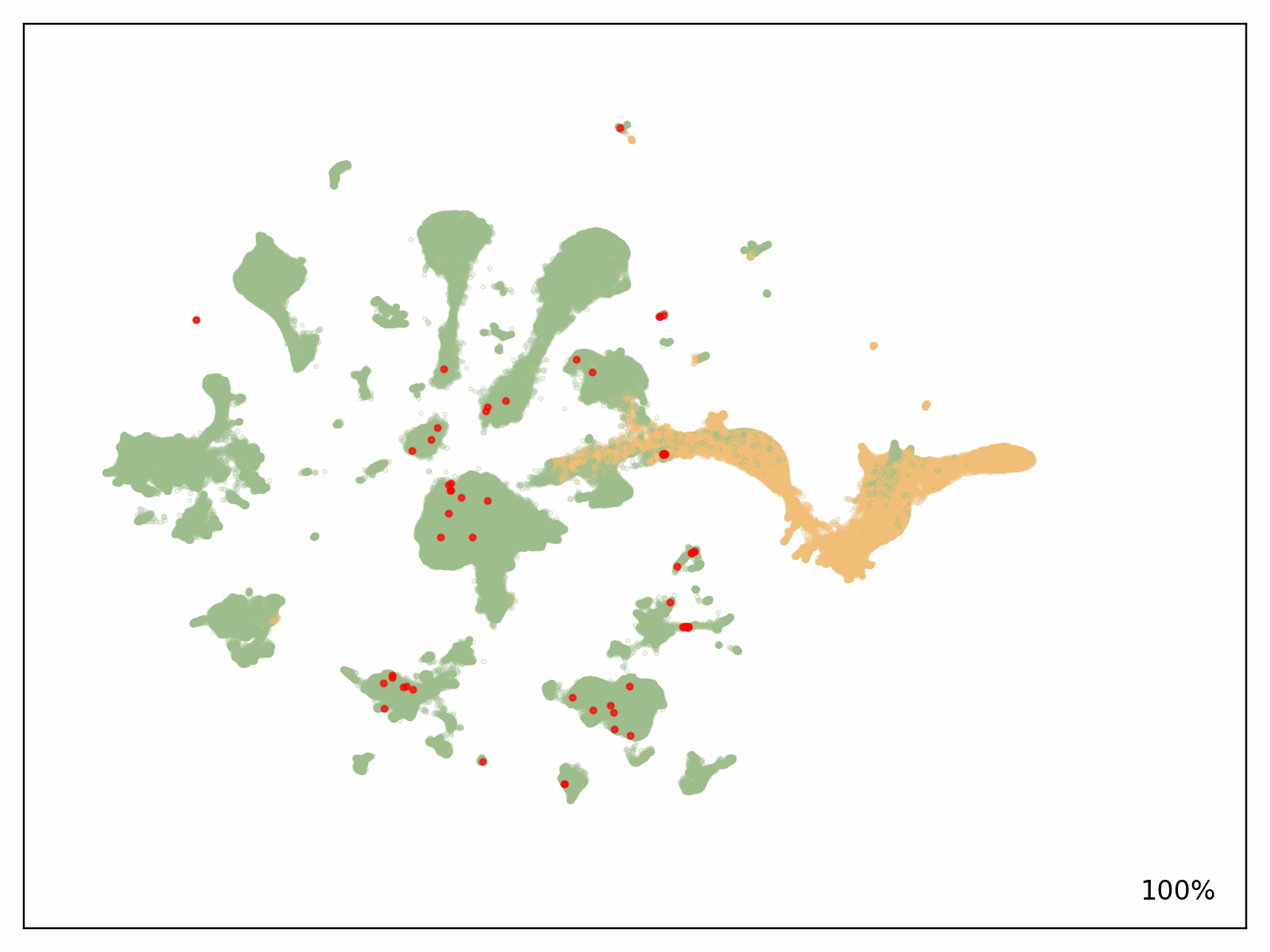
To test the scalability of our solution, Metagenomi fine tuned a model on natural examples of a valuable but rare class of enzymes sourced from Metagenomi’s large, proprietary database of metagenomics data. The model was fine tuned using traditional GPU instances, then traced onto AWS AI chips Inferentia. Using our batch and Nextflow pipeline, we launched batch jobs to generate well over 1 million enzymes, varying generation parameters between jobs to test the effect of different sampling methods, temperatures, and precisions. The total compute cost of generation using our optimized AWS AI pipeline, including costs incurred from EC2 Inf2 Spot retries, was $2,613 (see preceding note on estimating costs for your workloads). Generated sequences were validated with a pipeline that used a combination of AI and traditional sequence validation techniques. Sequences were dereplicated using mmseqs, filtered for appropriate length, checked for accurate domain structures with hmmsearch, folded using ESMFold, and embedded using AMPLIFY_350M. Structures were used for comparison to known enzymes in the class, and embeddings were used to validate intrinsic enzyme fitness. Results of the generation are shown in the following figure, with several hundred thousand generative AI enzymes plotted in the embedding space. Natural, characterized enzymes used as prompts shown in red, generative AI enzymes passing all filters are shown in green, and generative AI enzymes not passing filters shown in orange.
Conclusion
In this post, we outlined methods to reduce the cost of large-scale protein design projects by up to 56% using Amazon EC2 Inf instances, which has allowed Metagenomi to generate millions of novel enzymes across several high value protein classes using models trained on our proprietary protein dataset. This implementation showcases how AWS Inferentia can make large-scale protein generation more accessible and economical for biotechnology applications. To learn more about EC2 Inf instances and to start implementing your own workflows on AWS Neuron, see the AWS Neuron documentation. To read more about some of the novel enzymes Metagenomi has discovered, see Metagenomi’s publications and posters.
About the authors
 Audra Devoto is a Data Scientist with a background in metagenomics and many years of experience working with large genomics datasets on AWS. At Metagenomi, she builds out infrastructure to support large scale analysis projects and enables discovery of novel enzymes from MGXdb.
Audra Devoto is a Data Scientist with a background in metagenomics and many years of experience working with large genomics datasets on AWS. At Metagenomi, she builds out infrastructure to support large scale analysis projects and enables discovery of novel enzymes from MGXdb.
 Owen Janson is a bioinformatics Engineer at Metagenomi who focuses on building tools and cloud infrastructure to support analysis of massive genomic datasets.
Owen Janson is a bioinformatics Engineer at Metagenomi who focuses on building tools and cloud infrastructure to support analysis of massive genomic datasets.
 Adam Perry is a seasoned cloud architect with deep expertise in AWS, where he’s designed and automated complex cloud solutions for hundreds of businesses. As a co-founder of Tennex, he has led technology strategy, built custom tools, and collaborated closely with his team to help early stage biotech companies scale securely and efficiently on cloud.
Adam Perry is a seasoned cloud architect with deep expertise in AWS, where he’s designed and automated complex cloud solutions for hundreds of businesses. As a co-founder of Tennex, he has led technology strategy, built custom tools, and collaborated closely with his team to help early stage biotech companies scale securely and efficiently on cloud.
 Christopher Brown, PhD, is head of the Discovery team at Metagenomi. He is an accomplished scientist and expert in metagenomics, and has led the discovery and characterization of numerous novel enzyme systems for gene editing applications.
Christopher Brown, PhD, is head of the Discovery team at Metagenomi. He is an accomplished scientist and expert in metagenomics, and has led the discovery and characterization of numerous novel enzyme systems for gene editing applications.
 Jamal Arif is a Senior Solutions Architect and Generative AI Specialist at AWS with over a decade of experience helping customers design and operationalize next-generation AI and cloud-native architectures. His work focuses on agentic AI, Kubernetes, and modernization frameworks, guiding enterprises through scalable adoption strategies and production-ready design patterns. Jamal builds thought-leadership content and speaks at AWS Summits, re:Invent, and industry conferences, sharing best practices for building secure, resilient, and high-impact AI solutions.
Jamal Arif is a Senior Solutions Architect and Generative AI Specialist at AWS with over a decade of experience helping customers design and operationalize next-generation AI and cloud-native architectures. His work focuses on agentic AI, Kubernetes, and modernization frameworks, guiding enterprises through scalable adoption strategies and production-ready design patterns. Jamal builds thought-leadership content and speaks at AWS Summits, re:Invent, and industry conferences, sharing best practices for building secure, resilient, and high-impact AI solutions.
 Pavel Novichkov, PhD, is a Senior Solutions Architect at AWS specializing in genomics and life sciences. He brings over 15 years of bioinformatics and cloud development experience to help healthcare and life sciences startups design and implement cloud-based solutions on AWS. He completed his postdoc at the National Center for Biotechnology Information (NIH) and served as a Computational Research Scientist at Berkeley Lab for over 12 years, where he co-developed innovative NGS-based technology that was recognized among Berkeley Lab’s top 90 breakthroughs in its history.
Pavel Novichkov, PhD, is a Senior Solutions Architect at AWS specializing in genomics and life sciences. He brings over 15 years of bioinformatics and cloud development experience to help healthcare and life sciences startups design and implement cloud-based solutions on AWS. He completed his postdoc at the National Center for Biotechnology Information (NIH) and served as a Computational Research Scientist at Berkeley Lab for over 12 years, where he co-developed innovative NGS-based technology that was recognized among Berkeley Lab’s top 90 breakthroughs in its history.


