

How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet beat imitation learning across eight benchmarks? Meta Superintelligence Labs propose ‘Early Experience‘, a reward-free training approach that improves policy learning in language agents without large human demonstration sets and without reinforcement learning (RL) in the main loop. The core idea is simple: let the agent branch from expert states, take its own actions, collect the resulting future states, and convert those consequences into supervision. The research team instantiates this with two concrete strategies—Implicit World Modeling (IWM) and Self-Reflection (SR)—and reports consistent gains across eight environments and multiple base models.
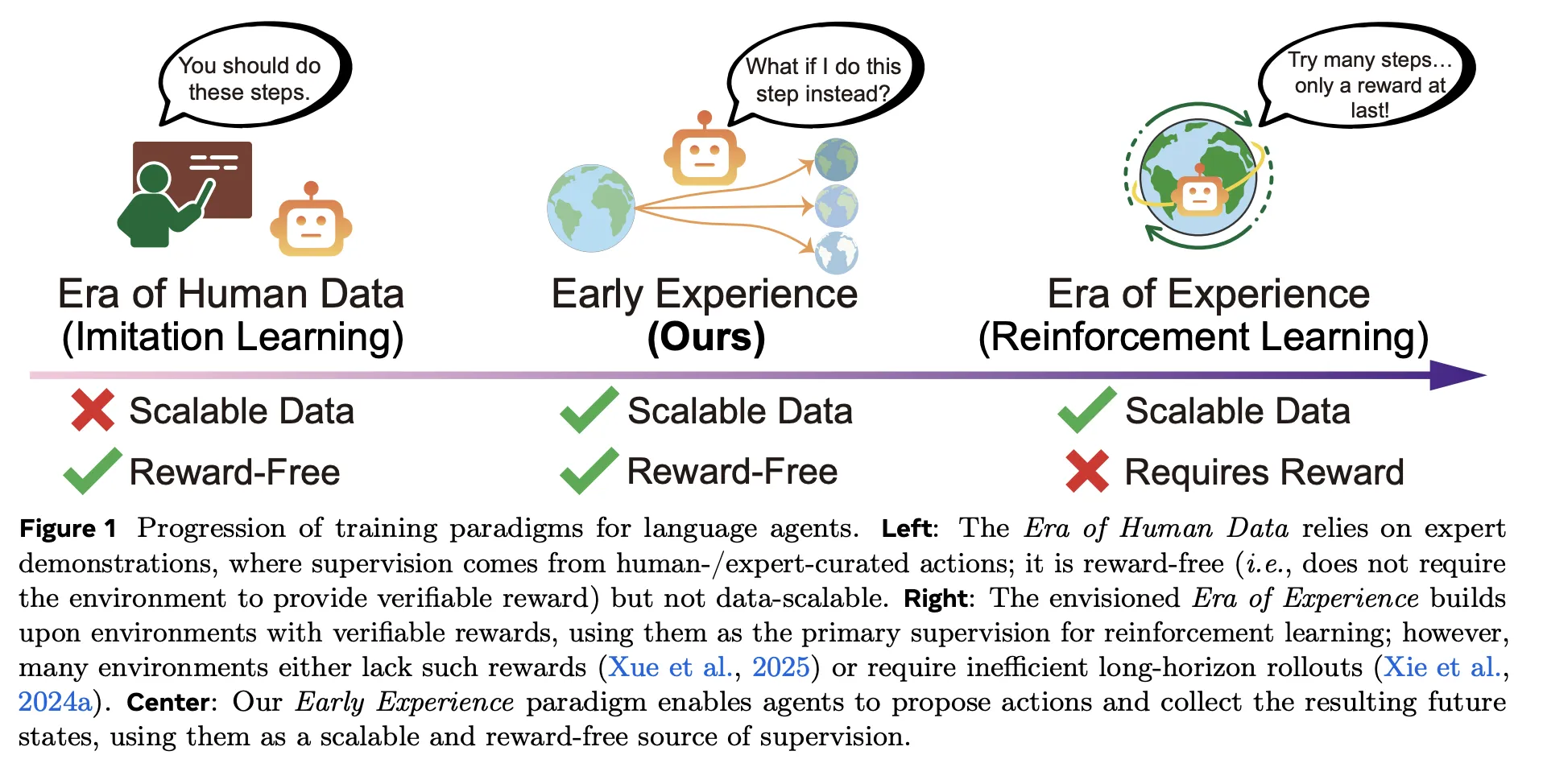
What Early Experience changes?
Traditional pipelines lean on imitation learning (IL) over expert trajectories, which is cheap to optimize but hard to scale and brittle out-of-distribution; reinforcement learning (RL) promises learning from experience but needs verifiable rewards and stable infrastructure—often missing in web and multi-tool settings. Early Experience sits between them: it is reward-free like imitation learning (IL), but the supervision is grounded in consequences of the agent’s own actions, not just expert actions. In short, the agent proposes, acts, and learns from what actually happens next—no reward function required.
- Implicit World Modeling (IWM): Train the model to predict the next observation given the state and chosen action, tightening the agent’s internal model of environment dynamics and reducing off-policy drift.
- Self-Reflection (SR): Present expert and alternative actions at the same state; have the model explain why the expert action is better using the observed outcomes, then fine-tune the policy from this contrastive signal.
Both strategies use the same budgets and decoding settings as IL; only the data source differs (agent-generated branches rather than more expert trajectories).
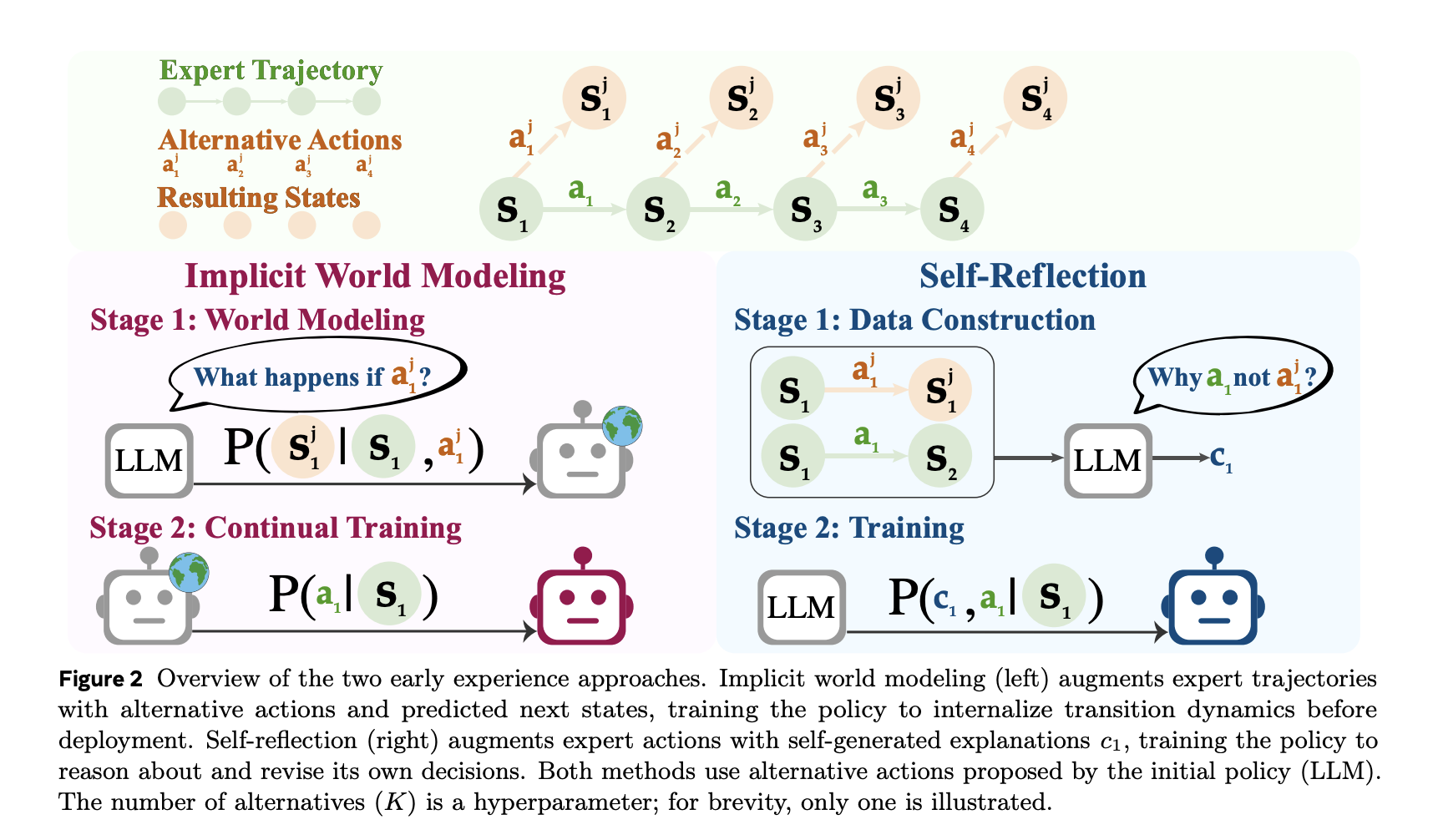
Understanding the Benchmarks
The research team evaluate on eight language-agent environments spanning web navigation, long-horizon planning, scientific/embodied tasks, and multi-domain API workflows—e.g., WebShop (transactional browsing), TravelPlanner (constraint-rich planning), ScienceWorld, ALFWorld, Tau-Bench, and others. Early Experience yields average absolute gains of +9.6 success and +9.4 out-of-domain (OOD) over IL across the full matrix of tasks and models. These gains persist when the same checkpoints are used to initialize RL (GRPO), improving post-RL ceilings by up to +6.4 compared to reinforcement learning (RL) started from imitation learning (IL).
Efficiency: less expert data, same optimization budget
A key practical win is demo efficiency. With a fixed optimization budget, Early Experience matches or beats IL using a fraction of expert data. On WebShop, 1/8 of the demonstrations with Early Experience already exceeds IL trained on the full demo set; on ALFWorld, parity is hit at 1/2 the demos. The advantage grows with more demonstrations, indicating the agent-generated future states provide supervision signals that demonstrations alone do not capture.
How the data is built?
The pipeline seeds from a limited set of expert rollouts to obtain representative states. At selected states, the agent proposes alternative actions, executes them, and records the next observations.
- For IWM, the training data are triplets ⟨state, action, next-state⟩ and the objective is next-state prediction.
- For SR, the prompts include the expert action and several alternatives plus their observed outcomes; the model produces a grounded rationale explaining why the expert action is preferable, and this supervision is then used to improve the policy.
Where reinforcement learning (RL) fits?
Early Experience is not “RL without rewards.” It is a supervised recipe that uses agent-experienced outcomes as labels. In environments with verifiable rewards, the research team simply add RL after Early Experience. Because the initialization is better than IL, the same RL schedule climbs higher and faster, with up to +6.4 final success over IL-initialized RL across tested domains. This positions Early Experience as a bridge: reward-free pre-training from consequences, followed (where possible) by standard reinforcement learning (RL).
Key Takeaways
- Reward-free training via agent-generated future states (not rewards) using Implicit World Modeling and Self-Reflection outperforms imitation learning across eight environments.
- Reported absolute gains over IL: +18.4 (WebShop), +15.0 (TravelPlanner), +13.3 (ScienceWorld) under matched budgets and settings.
- Demo efficiency: exceeds IL on WebShop with 1/8 of demonstrations; reaches ALFWorld parity with 1/2—at fixed optimization cost.
- As an initializer, Early Experience boosts subsequent RL (GRPO) endpoints by up to +6.4 versus RL started from IL.
- Validated on multiple backbone families (3B–8B) with consistent in-domain and out-of-domain improvements; positioned as a bridge between imitation learning (IL) and reinforcement learning (RL).
Editorial Comments
Early Experience is a pragmatic contribution: it replaces brittle rationale-only augmentation with outcome-grounded supervision that an agent can generate at scale, without reward functions. The two variants—Implicit World Modeling (next-observation prediction to anchor environment dynamics) and Self-Reflection (contrastive, outcome-verified rationales against expert actions)—directly attack off-policy drift and long-horizon error accumulation, explaining the consistent gains over imitation learning across eight environments and the stronger RL ceilings when used as an initializer for GRPO. In web and tool-use settings where verifiable rewards are scarce, this reward-free supervision is the missing middle between IL and RL and is immediately actionable for production agent stacks.
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning appeared first on MarkTechPost.

