
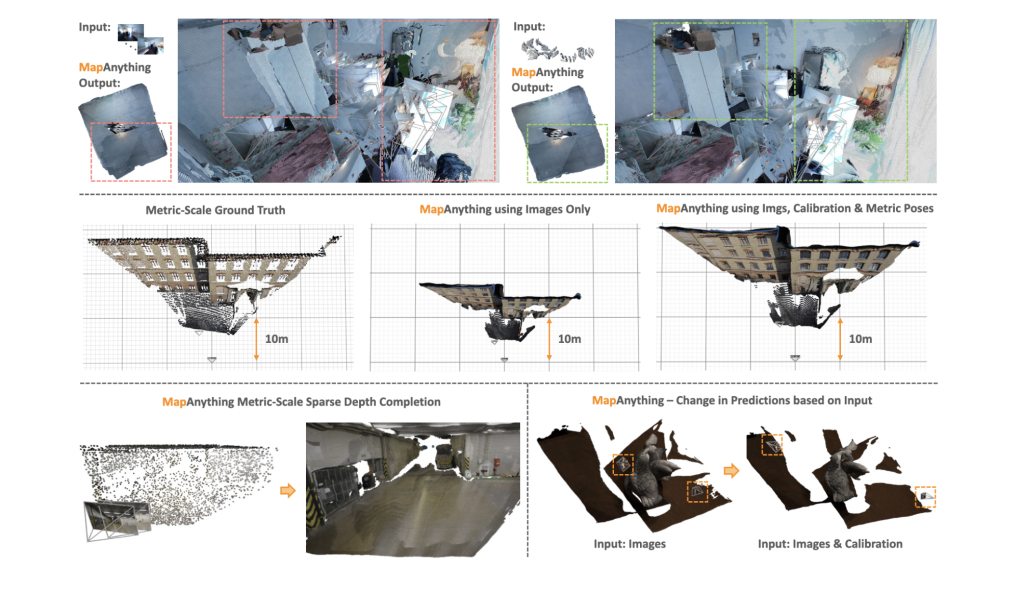
A team of researchers from Meta Reality Labs and Carnegie Mellon University has introduced MapAnything, an end-to-end transformer architecture that directly regresses factored metric 3D scene geometry from images and optional sensor inputs. Released under Apache 2.0 with full training and benchmarking code, MapAnything advances beyond specialist pipelines by supporting over 12 distinct 3D vision tasks in a single feed-forward pass.

Why a Universal Model for 3D Reconstruction?
Image-based 3D reconstruction has historically relied on fragmented pipelines: feature detection, two-view pose estimation, bundle adjustment, multi-view stereo, or monocular depth inference. While effective, these modular solutions require task-specific tuning, optimization, and heavy post-processing.
Recent transformer-based feed-forward models such as DUSt3R, MASt3R, and VGGT simplified parts of this pipeline but remained limited: fixed numbers of views, rigid camera assumptions, or reliance on coupled representations that needed expensive optimization.
MapAnything overcomes these constraints by:
- Accepting up to 2,000 input images in a single inference run.
- Flexibly using auxiliary data such as camera intrinsics, poses, and depth maps.
- Producing direct metric 3D reconstructions without bundle adjustment.
The model’s factored scene representation—composed of ray maps, depth, poses, and a global scale factor—provides modularity and generality unmatched by prior approaches.
Architecture and Representation
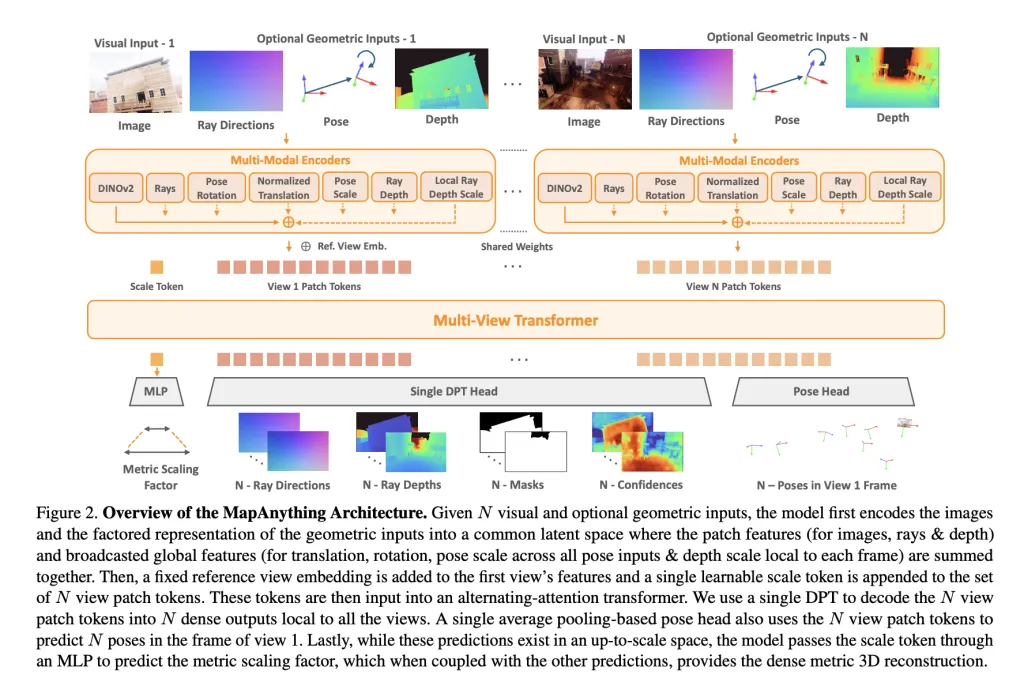
At its core, MapAnything employs a multi-view alternating-attention transformer. Each input image is encoded with DINOv2 ViT-L features, while optional inputs (rays, depth, poses) are encoded into the same latent space via shallow CNNs or MLPs. A learnable scale token enables metric normalization across views.
The network outputs a factored representation:
- Per-view ray directions (camera calibration).
- Depth along rays, predicted up-to-scale.
- Camera poses relative to a reference view.
- A single metric scale factor converting local reconstructions into a globally consistent frame.
This explicit factorization avoids redundancy, allowing the same model to handle monocular depth estimation, multi-view stereo, structure-from-motion (SfM), or depth completion without specialized heads.
Training Strategy
MapAnything was trained across 13 diverse datasets spanning indoor, outdoor, and synthetic domains, including BlendedMVS, Mapillary Planet-Scale Depth, ScanNet++, and TartanAirV2. Two variants are released:
- Apache 2.0 licensed model trained on six datasets.
- CC BY-NC model trained on all thirteen datasets for stronger performance.
Key training strategies include:
- Probabilistic input dropout: During training, geometric inputs (rays, depth, pose) are provided with varying probabilities, enabling robustness across heterogeneous configurations.
- Covisibility-based sampling: Ensures input views have meaningful overlap, supporting reconstruction up to 100+ views.
- Factored losses in log-space: Depth, scale, and pose are optimized using scale-invariant and robust regression losses to improve stability.
Training was performed on 64 H200 GPUs with mixed precision, gradient checkpointing, and curriculum scheduling, scaling from 4 to 24 input views.
Benchmarking Results
Multi-View Dense Reconstruction
On ETH3D, ScanNet++ v2, and TartanAirV2-WB, MapAnything achieves state-of-the-art (SoTA) performance across pointmaps, depth, pose, and ray estimation. It surpasses baselines like VGGT and Pow3R even when limited to images only, and improves further with calibration or pose priors.
For example:
- Pointmap relative error (rel) improves to 0.16 with only images, compared to 0.20 for VGGT.
- With images + intrinsics + poses + depth, the error drops to 0.01, while achieving >90% inlier ratios.
Two-View Reconstruction
Against DUSt3R, MASt3R, and Pow3R, MapAnything consistently outperforms across scale, depth, and pose accuracy. Notably, with additional priors, it achieves >92% inlier ratios on two-view tasks, significantly beyond prior feed-forward models.
Single-View Calibration
Despite not being trained specifically for single-image calibration, MapAnything achieves an average angular error of 1.18°, outperforming AnyCalib (2.01°) and MoGe-2 (1.95°).
Depth Estimation
On the Robust-MVD benchmark:
- MapAnything sets new SoTA for multi-view metric depth estimation.
- With auxiliary inputs, its error rates rival or surpass specialized depth models such as MVSA and Metric3D v2.
Overall, benchmarks confirm 2× improvement over prior SoTA methods in many tasks, validating the benefits of unified training.
Key Contributions
The research team highlight four major contributions:
- Unified Feed-Forward Model capable of handling more than 12 problem settings, from monocular depth to SfM and stereo.
- Factored Scene Representation enabling explicit separation of rays, depth, pose, and metric scale.
- State-of-the-Art Performance across diverse benchmarks with fewer redundancies and higher scalability.
- Open-Source Release including data processing, training scripts, benchmarks, and pretrained weights under Apache 2.0.
Conclusion
MapAnything establishes a new benchmark in 3D vision by unifying multiple reconstruction tasks—SfM, stereo, depth estimation, and calibration—under a single transformer model with a factored scene representation. It not only outperforms specialist methods across benchmarks but also adapts seamlessly to heterogeneous inputs, including intrinsics, poses, and depth. With open-source code, pretrained models, and support for over 12 tasks, MapAnything lays the groundwork for a truly general-purpose 3D reconstruction backbone.
Check out the Paper, Codes and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Meta AI Researchers Release MapAnything: An End-to-End Transformer Architecture that Directly Regresses Factored, Metric 3D Scene Geometry appeared first on MarkTechPost.


