This post is co-written with Julieta Rappan, Macarena Blasi, and María Candela Blanco from the Government of the City of Buenos Aires.
The Government of the City of Buenos Aires continuously works to improve citizen services. In February 2019, it introduced an AI assistant named Boti available through WhatsApp, the most widely used messaging service in Argentina. With Boti, citizens can conveniently and quickly access a wide variety of information about the city, such as renewing a driver’s license, accessing healthcare services, and learning about cultural events. This AI assistant has become a preferred communication channel and facilitates more than 3 million conversations each month.
As Boti grows in popularity, the Government of the City of Buenos Aires seeks to provide new conversational experiences that harness the latest developments in generative AI. One challenge that citizens often face is navigating the city’s complex bureaucratic landscape. The City Government’s website includes over 1,300 government procedures, each of which has its own logic, nuances, and exceptions. The City Government recognized that Boti could improve access to this information by directly answering citizens’ questions and connecting them to the right procedure.
To pilot this new solution, the Government of the City of Buenos Aires partnered with the AWS Generative AI Innovation Center (GenAIIC). The teams worked together to develop an agentic AI assistant using LangGraph and Amazon Bedrock. The solution includes two main components: an input guardrail system and a government procedures agent. The input guardrail uses a custom LLM classifier to analyze incoming user queries, determining whether to approve or block requests based on their content. Approved requests are handled by the government procedures agent, which retrieves relevant procedural information and generates responses. Since most user queries focus on a single procedure, we developed a novel reasoning retrieval system to improve retrieval accuracy. This system initially retrieves comparative summaries that disambiguate similar procedures and then applies a large language model (LLM) to select the most relevant results. The agent uses this information to craft responses in Boti’s characteristic style, delivering short, helpful, and expressive messages in Argentina’s Rioplatense Spanish dialect. We focused on distinctive linguistic features of this dialect including the voseo (using “vos” instead of “tú”) and periphrastic future (using “ir a” before verbs).
In this post, we dive into the implementation of the agentic AI system. We begin with an overview of the solution, explaining its design and main features. Then, we discuss the guardrail and agent subcomponents and assess their performance. Our evaluation shows that the guardrails effectively block harmful content, including offensive language, harmful opinions, prompt injection attempts, and unethical behaviors. The agent achieves up to 98.9% top-1 retrieval accuracy using the reasoning retriever, which marks a 12.5–17.5% improvement over standard retrieval-augmented generation (RAG) methods. Subject matter experts found that Boti’s responses were 98% accurate in voseo usage and 92% accurate in periphrastic future usage. The promising results of this solution establish a new era of citizen-government interaction.
Solution overview
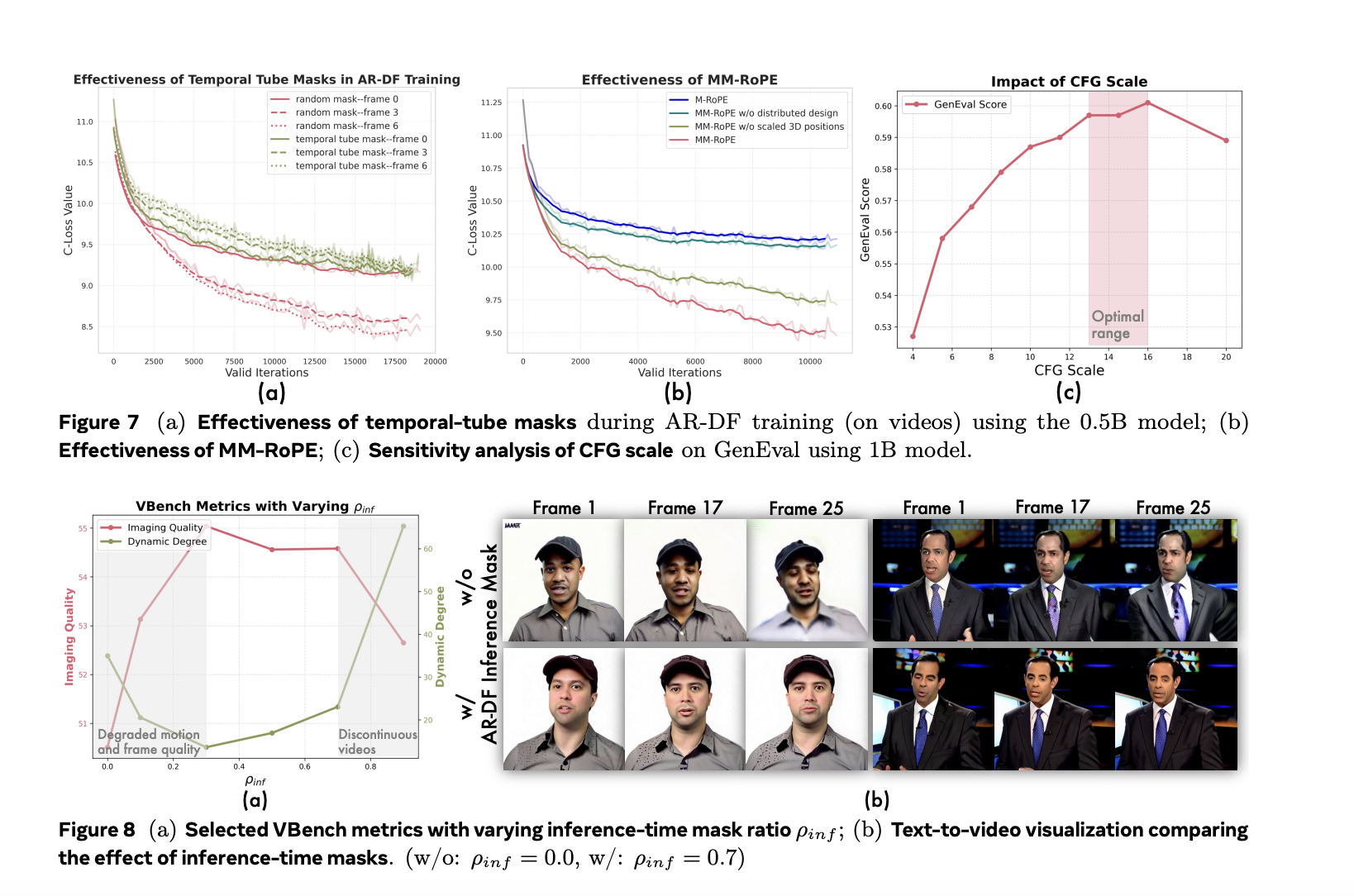
The Government of the City of Buenos Aires and the GenAIIC built an agentic AI assistant using Amazon Bedrock and LangGraph that includes an input guardrail system to enable safe interactions and a government procedures agent to respond to user questions. The workflow is shown in the following diagram.
The process begins when a user submits a question. In parallel, the question is passed to the input guardrail system and government procedures agent. The input guardrail system determines whether the question contains harmful content. If triggered, it stops graph execution and redirects the user to ask questions about government procedures. Otherwise, the agent continues to formulate its response. The agent either calls a retrieval tool, which allows it to obtain relevant context and metadata from government procedures stored in Amazon Bedrock Knowledge Bases, or responds to the user. Both the input guardrail and government procedures agent use the Amazon Bedrock Converse API for LLM inference. This API provides access to a wide selection of LLMs, helping us optimize performance and latency across different subtasks.
Input guardrail system
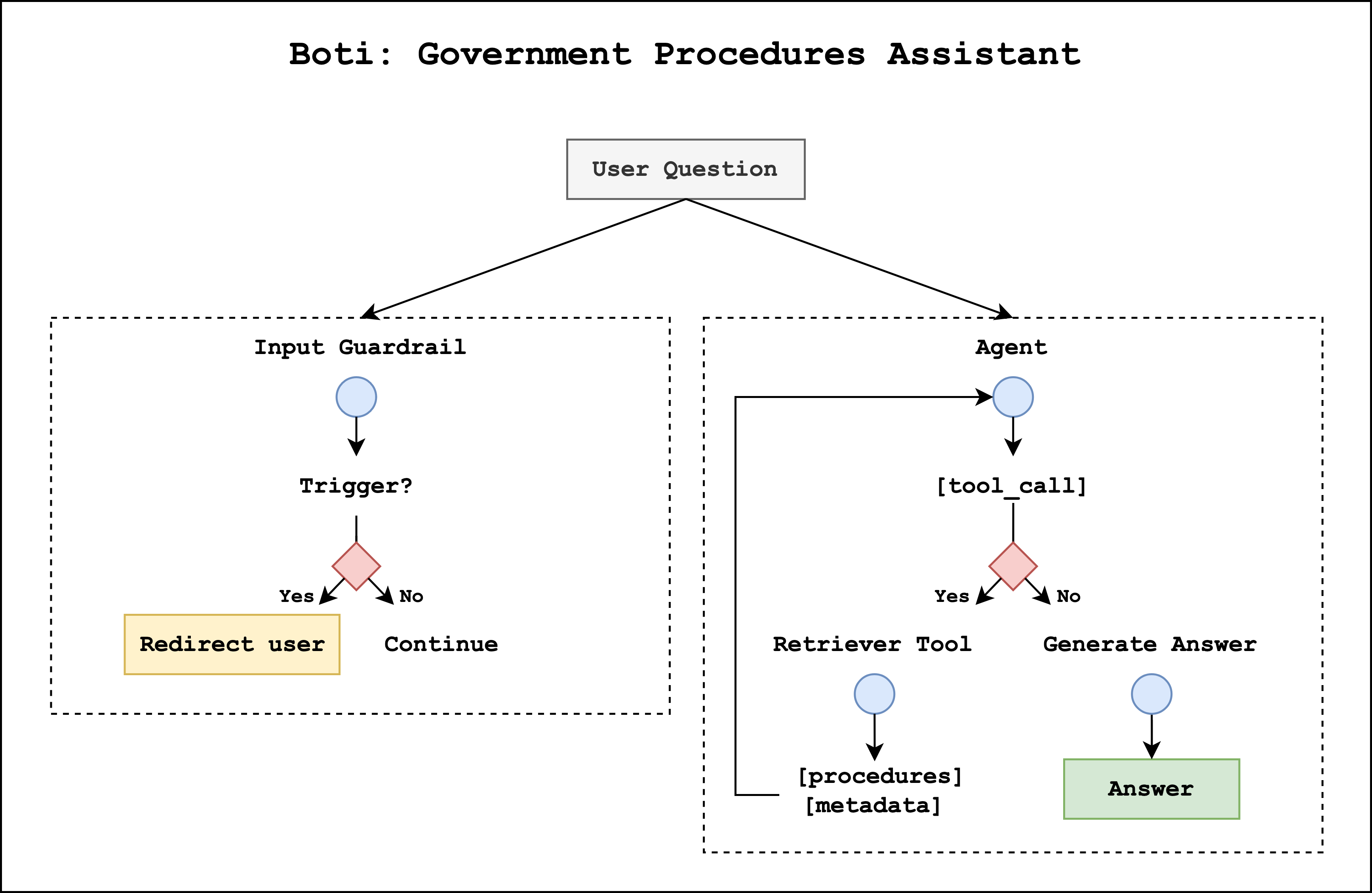
Input guardrails help prevent the LLM system from processing harmful content. Although Amazon Bedrock Guardrails offers one implementation approach with filters for specific words, content, or sensitive information, we developed a custom solution. This provided us greater flexibility to optimize performance for Rioplatense Spanish and monitor specific types of content. The following diagram illustrates our approach, in which an LLM classifier assigns a primary category (“approved” or “blocked”) as well as a more detailed subcategory.
Approved queries are within the scope of the government procedures agent. They consist of on-topic requests, which focus on government procedures, and off-topic requests, which are low-risk conversation questions that the agent responds to directly. Blocked queries contain high-risk content that Boti should avoid, including offensive language, harmful opinions, prompt injection attacks, or unethical behaviors.
We evaluated the input guardrail system on a dataset consisting of both normal and harmful user queries. The system successfully blocked 100% of harmful queries, while occasionally flagging normal queries as harmful. This performance balance makes sure that Boti can provide helpful information while maintaining safe and appropriate interactions for users.
Agent system
The government procedures agent is responsible for answering user questions. It determines when to retrieve relevant procedural information using its retrieval tool and generates responses in Boti’s characteristic style. In the following sections, we examine both processes.
Reasoning retriever
The agent can use a retrieval tool to provide accurate and up-to-date information about government procedures. Retrieval tools typically employ a RAG framework to perform semantic similarity searches between user queries and a knowledge base containing document chunks stored as embeddings, and then provide the most relevant samples as context to the LLM. Government procedures, however, present challenges to this standard approach. Related procedures, such as renewing and reprinting drivers’ licenses, can be difficult to disambiguate. Additionally, each user question typically requires information from one specific procedure. The mixture of chunks returned from standard RAG approaches increases the likelihood of generating incorrect responses.
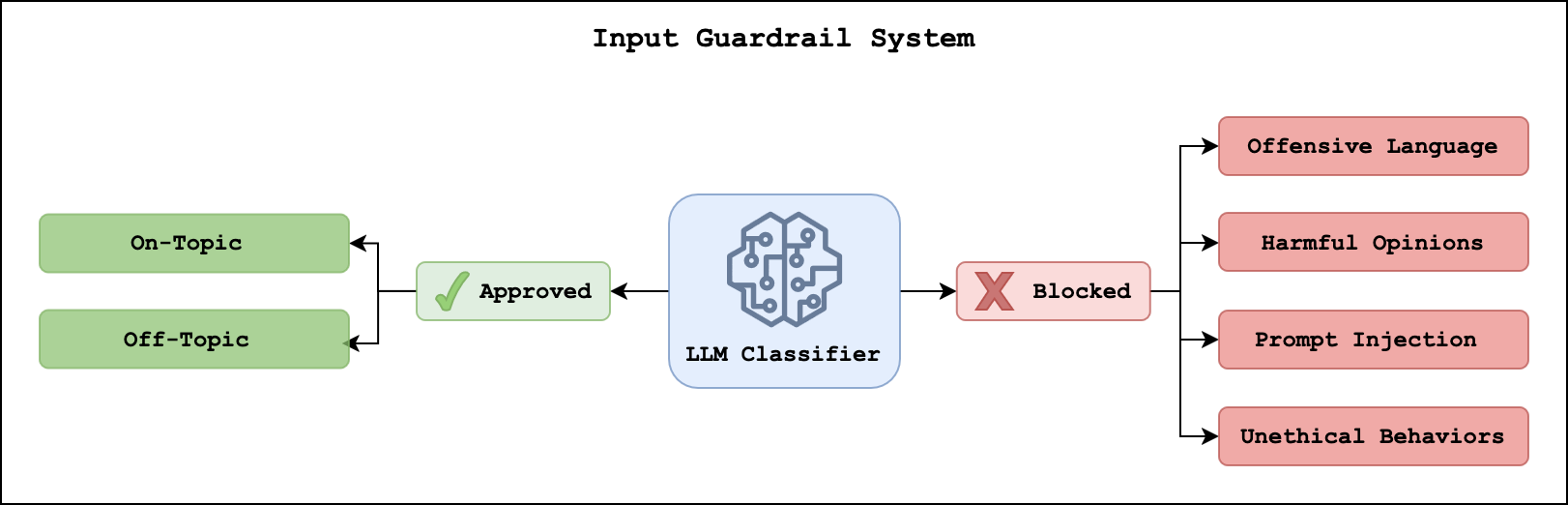
To better disambiguate government procedures, the Buenos Aires and GenAIIC teams developed a reasoning retrieval method that uses comparative summaries and LLM selection. An overview of this approach is shown in the following diagram.
A necessary preprocessing step before retrieval is the creation of a government procedures knowledge base. To capture both the key information contained in procedures and how they related to each other, we created comparative summaries. Each summary contains basic information, such as the procedure’s purpose, intended audience, and content, such as costs, steps, and requirements. We clustered the base summaries into small groups, with an average cluster size of 5, and used an LLM to generate descriptions about what made each procedure different from its neighbors. We appended the distinguishing descriptions to the base information to create the final summary. We note that this approach shares similarities to Anthropic’s Contextual Retrieval, which prepends explanatory context to document chunk.
With the knowledge base in place, we are able to retrieve relevant government procedures based on the user query. The reasoning retriever completes three steps:
- Retrieve M Summaries: We retrieve between 1 and M comparative summaries using semantic search.
- Optional Reasoning: In some cases, the initial retrieval surfaces similar procedures. To make sure that the most relevant procedures are returned to the agent, we apply an optional LLM reasoning step. The condition for this step occurs when the ratio of the first and second retrieval scores falls below a threshold value. An LLM follows a chain-of-thought (CoT) process in which it compares the user query to the retrieved summaries. It discards irrelevant procedures and reorders the remaining ones based on relevance. If the user query is specific enough, this process typically returns one result. By applying this reasoning step selectively, we minimize latency and token usage while maintaining high retrieval accuracy.
- Retrieve N Full-Text Procedures: After the most relevant procedures are identified, we fetch their complete documents and metadata from an Amazon DynamoDB table. The metadata contains information like the source URL and the sentiment of the procedure. The agent typically receives between 1 and N results, where N ≤ M.
The agent receives the retrieved full text procedures in its context window. It follows its own CoT process to determine the relevant content and URL source attributions when generating its answer.
We evaluated our reasoning retriever against standard RAG techniques using a synthetic dataset of 1,908 questions derived from known source procedures. The performance was measured by determining whether the correct procedure appeared in the top-k retrieved results for each question. The following plot compares the top-k retrieval accuracy for each approach across different models, arranged in order of ascending performance from left to right. The metrics are proportionally weighted based on each procedure’s webpage visit frequency, making sure that our evaluation reflects real-world usage patterns.
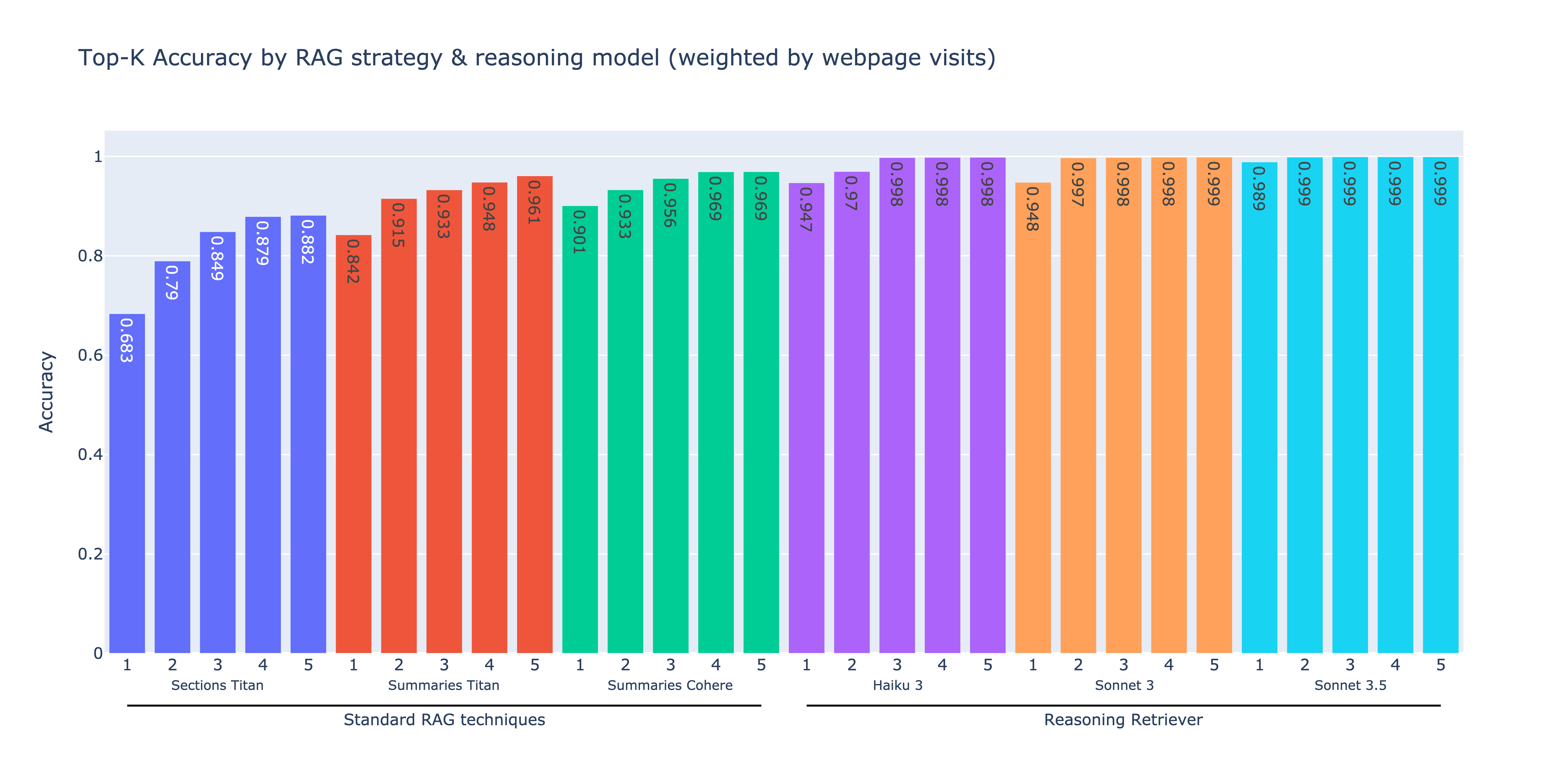
The first three approaches represent standard vector-based retrieval methods. The first method, Section Titan, involved chunking procedures by document sections, targeting approximately 250 words per chunk, and then embedding the chunks using Amazon Titan Text Embeddings v2. The second method, Summaries Titan, consisted of embedding the procedure summaries using the same embedding model. By embedding summaries rather than document text, the retrieval accuracy improved by 7.8–15.8%. The third method, Summaries Cohere, involved embedding procedure summaries using Cohere Multilingual v3 on Amazon Bedrock. The Cohere Multilingual embedding model provided a noticeable improvement in retrieval accuracy compared to the Amazon Titan embedding models, with all top-k values above 90%.
The next three approaches use the reasoning retriever. We embedded the procedure summaries using the Cohere Multilingual model, retrieved 10 summaries during the initial retrieval step, and optionally applied the LLM-based reasoning step using either Anthropic’s Haiku 3, Claude 3 Sonnet, or Claude 3.5 Sonnet on Amazon Bedrock. All three reasoning retrievers consistently outperform standard RAG techniques, achieving 12.5–17.5% higher top-k accuracies. Anthropic’s Claude 3.5 Sonnet delivered the highest performance with 98.9% top-1 accuracy. These results demonstrate how combining embedding-based retrieval with LLM-powered reasoning can improve RAG performance.
Answer generation
After collecting the necessary information, the agent responds using Boti’s distinctive communication style: concise, helpful messages in Rioplatense Spanish. We maintained this voice through prompt engineering that specified the following:
- Personality – Convey a warm and friendly tone, providing quick solutions to everyday problems
- Response length – Limit responses to a few sentences
- Structure – Organize content using lists and highlights key information using bold text
- Expression – Use emojis to mark important requirements and add visual cues
- Dialect – Incorporate Rioplatense linguistic features, including voseo, periphrastic future, and regional vocabulary (for example, “acordate,” “entrar,” “acá,” and “allá”).
Government procedures often address sensitive topics, like accidents, health, or security. To facilitate appropriate responses, we incorporated sentiment analysis into our knowledge base as metadata. This allows our system to route to different prompt templates. Sensitive topics are directed to prompts with reduced emoji usage and more empathetic language, whereas neutral topics receive standard templates.
The following figure shows a sample response to a question about borrowing library books. It has been translated to English for convenience.

To validate our prompt engineering approach, subject matter experts at the Government of the City of Buenos Aires reviewed a sample of Boti’s responses. Their analysis confirmed high fidelity to Rioplatense Spanish, with 98% accuracy in voseo usage and 92% in periphrastic future usage.
Conclusion
This post described the agentic AI assistant built by the Government of the City of Buenos Aires and the GenAIIC to respond to citizens’ questions about government procedures. The solution consists of two primary components: an input guardrail system that helps prevent the system from responding to harmful user queries and a government procedures agent that retrieves relevant information and generates responses. The input guardrails effectively block harmful content, including queries with offensive language, harmful opinions, prompt injection, and unethical behaviors. The government procedures agent employs a novel reasoning retrieval method that disambiguates similar government procedures, achieving up to 98.9% top-1 retrieval accuracy and a 12.5–17.5% improvement over standard RAG methods. Through prompt engineering, responses are delivered in Rioplatense Spanish using Boti’s voice. Subject matter experts rated Boti’s linguistic performance highly, with 98% accuracy in voseo usage and 92% in periphrastic future usage.
As generative AI advances, we expect to continuously improve our solution. The expanding catalog of LLMs available in Amazon Bedrock makes it possible to experiment with newer, more powerful models. This includes models that process text, as explored in the solution in this post, as well as models that process speech, allowing for direct speech-to-speech interactions. We might also explore the fine-tuning capabilities of Amazon Bedrock to customize models so that they better capture the linguistic features of Rioplatense Spanish. Beyond model improvements, we can iterate on our agent framework. The agent’s tool set can be expanded to support other tasks associated with government procedures like account creation, form completion, and appointment scheduling. As the City Government develops new experiences for citizens, we can consider implementing multi-agent frameworks in which specialist agents, like the government procedures agent, handle specific tasks.
To learn more about Boti and AWS’s generative AI capabilities, check out the following resources:
- Boti: The City Chatbot
- Government of the City of Buenos Aires: Procedures
- Amazon Bedrock
- Amazon Bedrock Knowledge Bases
About the authors
Julieta Rappan is Director of the Digital Channels Department of the Buenos Aires City Government, where she coordinates the landscape of digital and conversational interfaces. She has extensive experience in the comprehensive management of strategic and technological projects, as well as in leading high-performance teams focused on the development of digital products and services. Her leadership drives the implementation of technological solutions with a focus on scalability, coherence, public value, and innovation—where generative technologies are beginning to play a central role.
Macarena Blasi is Chief of Staff at the Digital Channels Department of the Buenos Aires City Government, working across the city’s main digital services, including Boti—the WhatsApp-based virtual assistant—and the official Buenos Aires website. She began her journey working in conversational experience design, later serving as product owner and Operations Manager and then as Head of Experience and Content, leading multidisciplinary teams focused on improving the quality, accessibility, and usability of public digital services. Her work is driven by a commitment to building clear, inclusive, and human-centered experiences in the public sector.
María Candela Blanco is Operations Manager for Quality Assurance, Usability, and Continuous Improvement at the Buenos Aires Government, where she leads the content, research, and conversational strategy across the city’s main digital channels, including the Boti AI assistant and the official Buenos Aires website. Outside of tech, Candela studies literature at UNSAM and is deeply passionate about language, storytelling, and the ways they shape our interactions with technology.
Leandro Micchele is a Software Developer focused on applying AI to real-world use cases, with expertise in AI assistants, voice, and vision solutions. He serves as the technical lead and consultant for the Boti AI assistant at the Buenos Aires Government and works as a Software Developer at Telecom Argentina. Beyond tech, his discipline extends to martial arts: he has over 20 years of experience and currently teaches Aikido.
Hugo Albuquerque is a Deep Learning Architect at the AWS Generative AI Innovation Center. Before joining AWS, Hugo had extensive experience working as a data scientist in the media and entertainment and marketing sectors. In his free time, he enjoys learning other languages like German and practicing social dancing, such as Brazilian Zouk.
Enrique Balp is a Senior Data Scientist at the AWS Generative AI Innovation Center working on cutting-edge AI solutions. With a background in the physics of complex systems focused on neuroscience, he has applied data science and machine learning across healthcare, energy, and finance for over a decade. He enjoys hikes in nature, meditation retreats, and deep friendships.
Diego Galaviz is a Deep Learning Architect at the AWS Generative AI Innovation Center. Before joining AWS, he had over 8 years of expertise as a data scientist across diverse sectors, including financial services, energy, big tech, and cybersecurity. He holds a master’s degree in artificial intelligence, which complements his practical industry experience.
Laura Kulowski is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where she works with customers to build generative AI solutions. Before joining Amazon, Laura completed her PhD at Harvard’s Department of Earth and Planetary Sciences and investigated Jupiter’s deep zonal flows and magnetic field using Juno data.
Rafael Fernandes is the LATAM leader of the AWS Generative AI Innovation Center, whose mission is to accelerate the development and implementation of generative AI in the region. Before joining Amazon, Rafael was a co-founder in the financial services industry space and a data science leader with over 12 years of experience in Europe and LATAM.