IBM has announced the release of Granite 4.0 3B Vision, a vision-language model (VLM) engineered specifically for enterprise-grade document data extraction. Departing from the monolithic approach of larger multimodal models, the 4.0 Vision release is architected as a specialized adapter designed to bring high-fidelity visual reasoning to the Granite 4.0 Micro language backbone.
This release represents a transition toward modular, extraction-focused AI that prioritizes structured data accuracy—such as converting complex charts to code or tables to HTML—over general-purpose image captioning.
Architecture: Modular LoRA and DeepStack Integration
The Granite 4.0 3B Vision model is delivered as a LoRA (Low-Rank Adaptation) adapter with approximately 0.5B parameters. This adapter is designed to be loaded on top of the Granite 4.0 Micro base model, a 3.5B parameter dense language model. This design allows for a ‘dual-mode’ deployment: the base model can handle text-only requests independently, while the vision adapter is activated only when multimodal processing is required.
Vision Encoder and Patch Tiling
The visual component utilizes the google/siglip2-so400m-patch16-384 encoder. To maintain high resolution across diverse document layouts, the model employs a tiling mechanism. Input images are decomposed into 384×384 patches, which are processed alongside a downscaled global view of the entire image. This approach ensures that fine details—such as subscripts in formulas or small data points in charts—are preserved before they reach the language backbone.
The DeepStack Backbone
To bridge the vision and language modalities, IBM utilizes a variant of the DeepStack architecture. This involves deeply stacking visual tokens into the language model across 8 specific injection points. By routing visual features into multiple layers of the transformer, the model achieves a tighter alignment between the ‘what’ (semantic content) and the ‘where’ (spatial layout), which is critical for maintaining structure during document parsing.
Training Curriculum: Focused on Chart and Table Extraction
The training of Granite 4.0 3B Vision reflects a strategic shift toward specialized extraction tasks. Rather than relying solely on general image-text datasets, IBM utilized a curated mixture of instruction-following data focused on complex document structures.
- ChartNet Dataset: The model was refined using ChartNet, a million-scale multimodal dataset designed for robust chart understanding.
- Code-Guided Pipeline: A key technical highlight of the training involves a “code-guided” approach for chart reasoning. This pipeline uses aligned data consisting of the original plotting code, the resulting rendered image, and the underlying data table, allowing the model to learn the structural relationship between visual representations and their source data.
- Extraction Tuning: The model was fine-tuned on a mixture of datasets focusing on Key-Value Pair (KVP) extraction, table structure recognition, and converting visual charts into machine-readable formats like CSV, JSON, and OTSL.
Performance and Evaluation Benchmarks
In technical evaluations, Granite 4.0 3B Vision has been benchmarked against several industry-standard suites for document understanding. It is important to note that datasets like PubTables-v2 and OmniDocBench are utilized as evaluation benchmarks to verify the model’s zero-shot performance in real-world scenarios.
| Task | Evaluation Benchmark | Metric |
| KVP Extraction | VAREX | 85.5% Exact Match (Zero-Shot) |
| Chart Reasoning | ChartNet (Human-Verified Test Set) | High Accuracy in Chart2Summary |
| Table Extraction | TableVQA-Bench & OmniDocBench | Evaluated via TEDS and HTML extraction |
The model currently ranks 3rd among models in the 2–4B parameter class on the VAREX leaderboard (as of March 2026), demonstrating its efficiency in structured extraction despite its compact size.
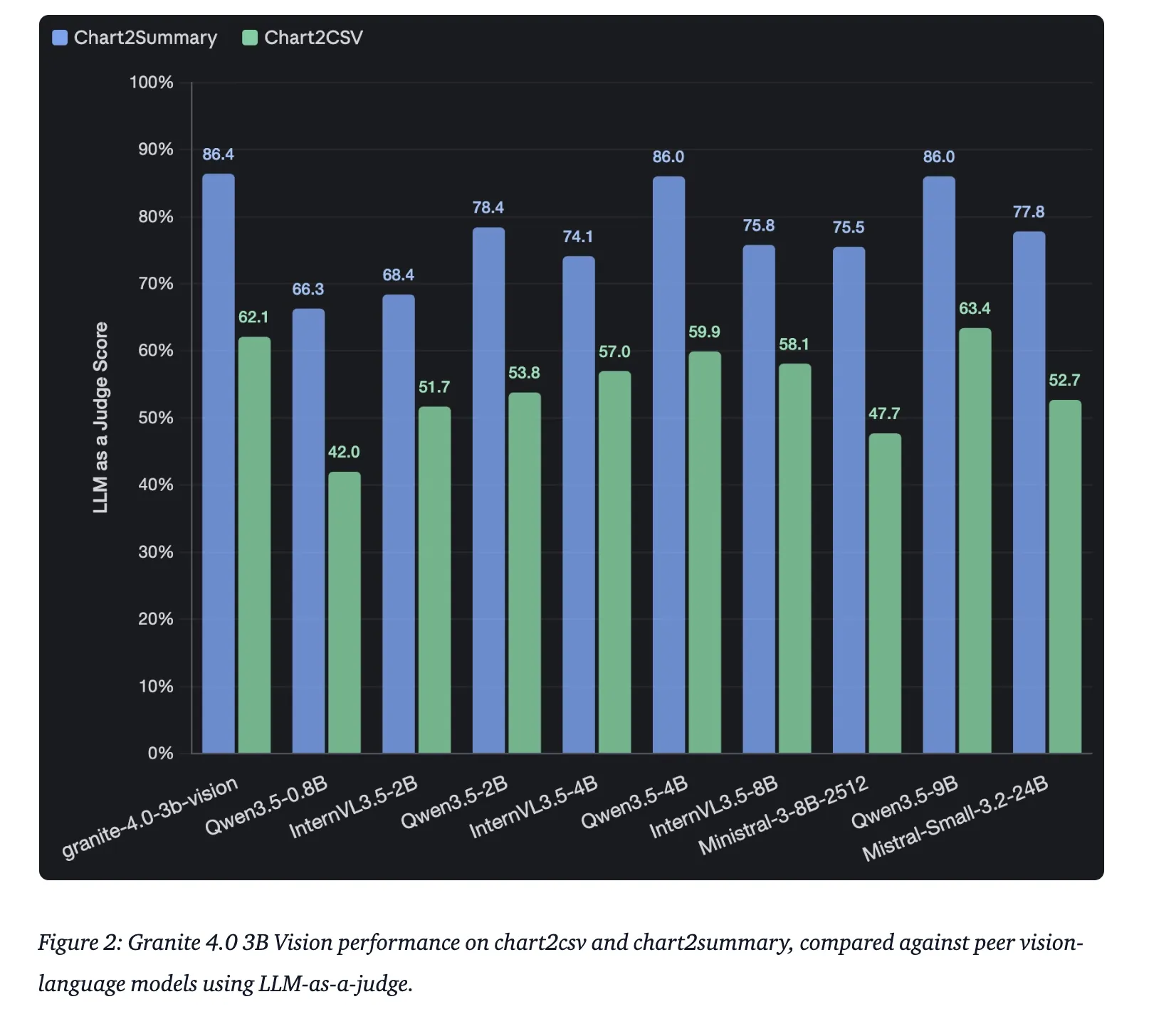
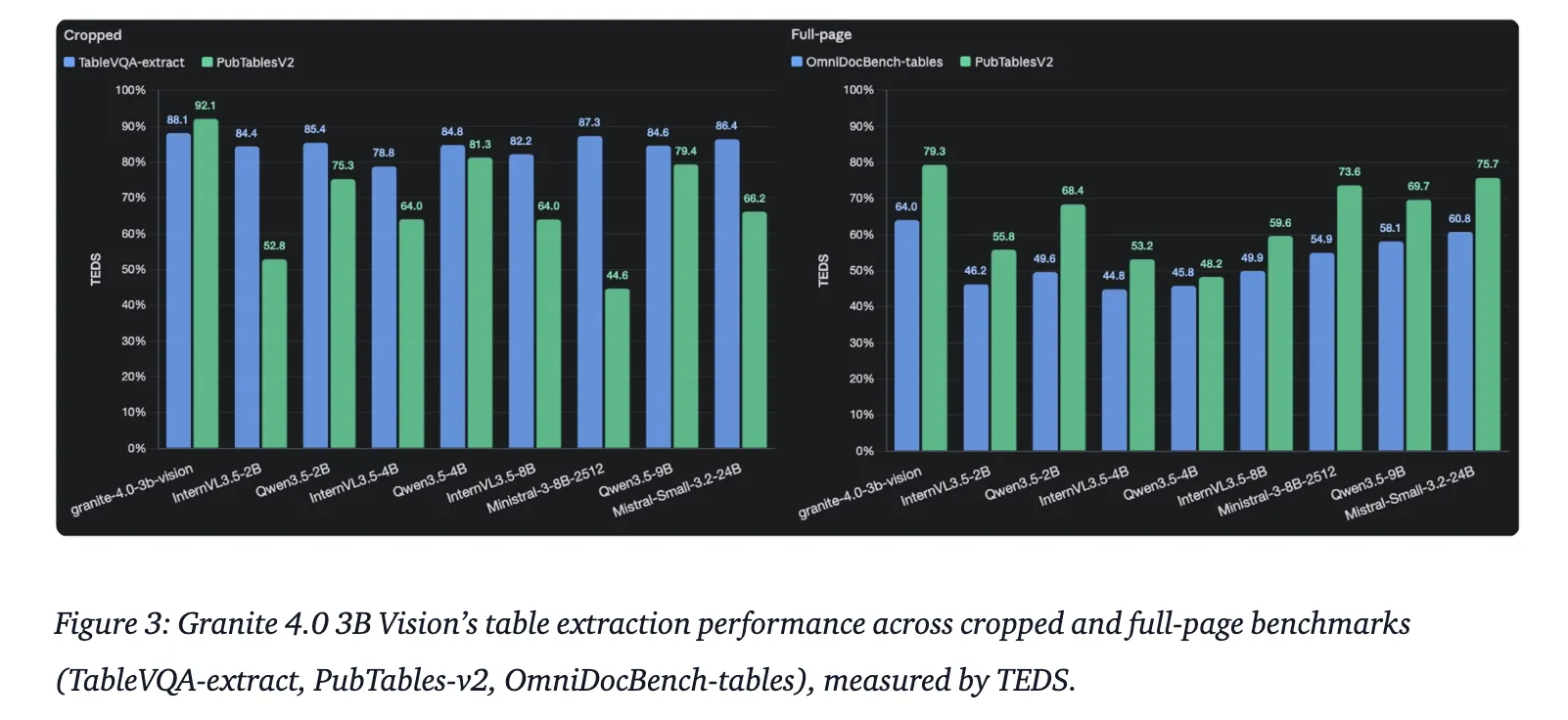
Key Takeaways
- Modular LoRA Architecture: The model is a 0.5B parameter LoRA adapter that operates on the Granite 4.0 Micro (3.5B) backbone. This design allows a single deployment to handle text-only workloads efficiently while activating vision capabilities only when needed.
- High-Resolution Tiling: Utilizing the google/siglip2-so400m-patch16-384 encoder, the model processes images by tiling them into 384×384 patches alongside a global downscaled view, ensuring that fine details in complex documents are preserved.
- DeepStack Injection: To improve layout awareness, the model uses a DeepStack approach with 8 injection points. This routes semantic features to earlier layers and spatial details to later layers, which is critical for accurate table and chart extraction.
- Specialized Extraction Training: Beyond general instruction following, the model was refined using ChartNet and a ‘code-guided’ pipeline that aligns plotting code, images, and data tables to help the model internalize the logic of visual data structures.
- Developer-Ready Integration: The release is Apache 2.0 licensed and features native support for vLLM (via a custom model implementation) and Docling, IBM’s tool for converting unstructured PDFs into machine-readable JSON or HTML.
Check out the Technical details and Model Weight. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post IBM Releases Granite 4.0 3B Vision: A New Vision Language Model for Enterprise Grade Document Data Extraction appeared first on MarkTechPost.