

This post was written with Martyna Shallenberg and Brode Mccrady from Myriad Genetics.
Healthcare organizations face challenges in processing and managing high volumes of complex medical documentation while maintaining quality in patient care. These organizations need solutions to process documents effectively to meet growing demands. Myriad Genetics, a provider of genetic testing and precision medicine solutions serving healthcare providers and patients worldwide, addresses this challenge.
Myriad’s Revenue Engineering Department processes thousands of healthcare documents daily across Women’s Health, Oncology, and Mental Health divisions. The company classifies incoming documents into classes such as Test Request Forms, Lab Results, Clinical Notes, and Insurance to automate Prior Authorization workflows. The system routes these documents to appropriate external vendors for processing based on their identified document class. They manually perform Key Information Extraction (KIE) including insurance details, patient information, and test results to determine Medicare eligibility and support downstream processes.
As document volumes increased, Myriad faced challenges with its existing system. The automated document classification solution worked but was costly and time-consuming. Information extraction remained manual due to complexity. To address high costs and slow processing, Myriad needed a better solution.
This post explores how Myriad Genetics partnered with the AWS Generative AI Innovation Center (GenAIIC) to transform their healthcare document processing pipeline using Amazon Bedrock and Amazon Nova foundation models. We detail the challenges with their existing solution, and how generative AI reduced costs and improved processing speed.
We examine the technical implementation using AWS’s open source GenAI Intelligent Document Processing (GenAI IDP) Accelerator solution, the optimization strategies used for document classification and key information extraction, and the measurable business impact on Myriad’s prior authorization workflows. We cover how we used prompt engineering techniques, model selection strategies, and architectural decisions to build a scalable solution that processes complex medical documents with high accuracy while reducing operational costs.
Document processing bottlenecks limiting healthcare operations
Myriad Genetics’ daily operations depend on efficiently processing complex medical documents containing critical information for patient care workflows and regulatory compliance. Their existing solution combined Amazon Textract for Optical Character Recognition (OCR) with Amazon Comprehend for document classification.
Despite 94% classification accuracy, this solution had operational challenges:
- Operational costs: 3 cents per page resulting in $15,000 monthly expenses per business unit
- Classification latency: 8.5 minutes per document, delaying downstream prior authorization workflows
Information extraction was entirely manual, requiring contextual understanding to differentiate critical clinical distinctions (like “is metastatic” versus “is not metastatic”) and to locate information like insurance numbers and patient information across varying document formats. This processing burden was substantial, with Women’s Health customer service requiring up to 10 full-time employees contributing 78 hours daily in the Women’s Health business unit alone.
Myriad needed a solution to:
- Reduce document classification costs while maintaining or improving accuracy
- Accelerate document processing to eliminate workflow bottlenecks
- Automate information extraction for medical documents
- Scale across multiple business units and document types
Amazon Bedrock and generative AI
Modern large language models (LLMs) process complex healthcare documents with high accuracy due to pre-training on massive text corpora. This pre-training enables LLMs to understand language patterns and document structures without feature engineering or large labeled datasets. Amazon Bedrock is a fully managed service that offers a broad range of high-performing LLMs from leading AI companies. It provides the security, privacy, and responsible AI capabilities that healthcare organizations require when processing sensitive medical information. For this solution, we used Amazon’s newest foundation models:
- Amazon Nova Pro: A cost-effective, low-latency model ideal for document classification
- Amazon Nova Premier: An advanced model with reasoning capabilities for information extraction
Solution overview
We implemented a solution with Myriad using AWS’s open source GenAI IDP Accelerator. The accelerator provides a scalable, serverless architecture that converts unstructured documents into structured data. The accelerator processes multiple documents in parallel through configurable concurrency limits without overwhelming downstream services. Its built-in evaluation framework lets users provide expected output through the user interface (UI) and evaluate generated results to iteratively customize configuration and improve accuracy.
The accelerator offers 1-click deployment with a choice of pre-built patterns optimized for different workloads with different configurability, cost, and accuracy requirements:
- Pattern 1 – Uses Amazon Bedrock Data Automation, a fully managed service that offers rich out-of-the-box features, ease of use, and straightforward per-page pricing. This pattern is recommended for most use cases.
- Pattern 2 – Uses Amazon Textract and Amazon Bedrock with Amazon Nova, Anthropic’s Claude, or custom fine-tuned Amazon Nova models. This pattern is ideal for complex documents requiring custom logic.
- Pattern 3 – Uses Amazon Textract, Amazon SageMaker with a fine-tuned model for classification, and Amazon Bedrock for extraction. This pattern is ideal for documents requiring specialized classification.
Pattern 2 proved most suitable for this project, meeting the critical requirement of low cost while offering flexibility to optimize accuracy through prompt engineering and LLM selection. This pattern offers a no-code configuration – customize document types, extraction fields, and processing logic through configuration, editable in the web UI.
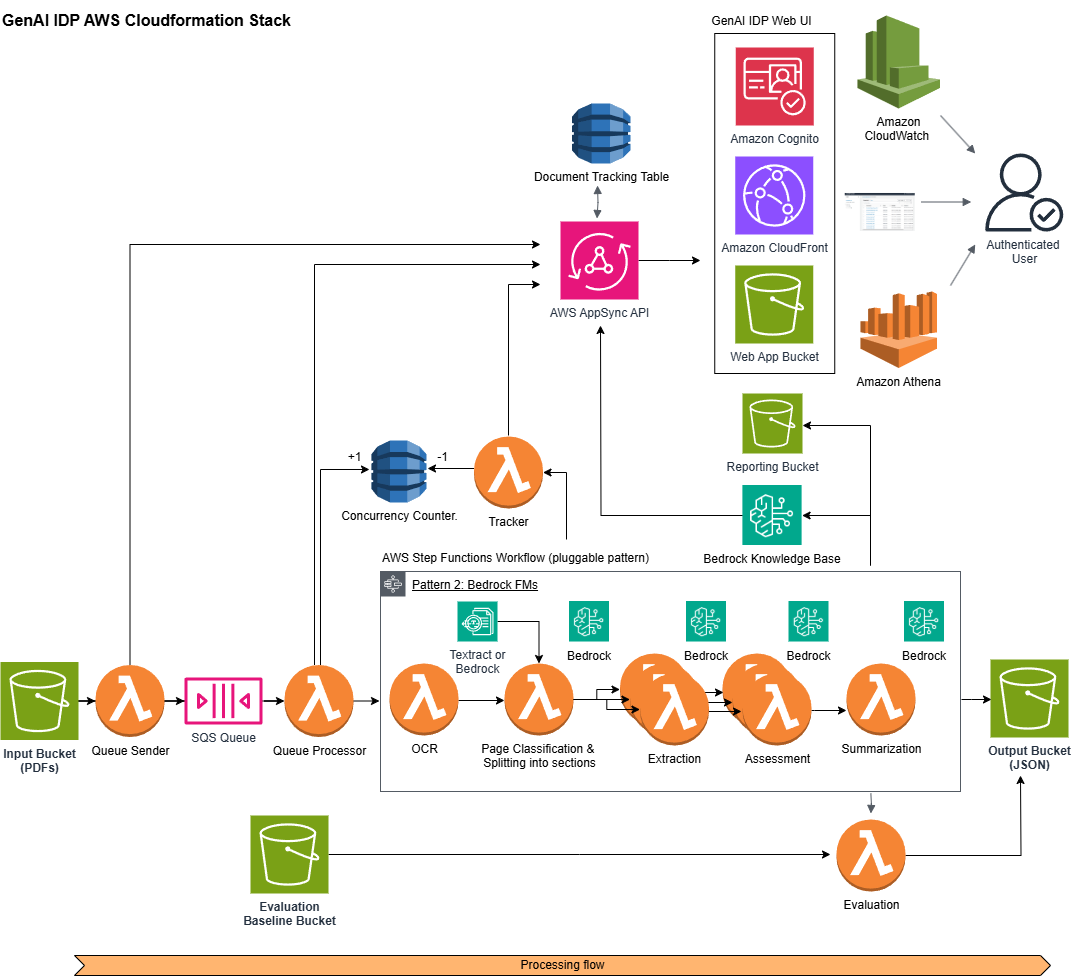
We customized the definitions of document classes, key attributes and their definitions per document class, LLM choice, LLM hyperparameters, and classification and extraction LLM prompts via Pattern 2’s config file. In production, Myriad integrated this solution into their existing event-driven architecture. The following diagram illustrates the production pipeline:

- Document Ingestion: Incoming order events trigger document retrieval from source document management systems, with cache optimization for previously processed documents.
- Concurrency Management: DynamoDB tracked concurrent AWS Step Function jobs while Amazon Simple Queue Service (SQS) queues files exceeding concurrency limits for document processing.
- Text Extraction: Amazon Textract extracted text, layout information, tables and forms from the normalized documents.
- Classification: The configured LLM analyzed the extracted content based on the customized document classification prompt provided in the config file and classifies documents into appropriate categories.
- Key Information Extraction: The configured LLM extracted medical information using extraction prompt provided in the config file.
- Structured Output: The pipeline formatted the results in a structured manner and delivered to Myriad’s Authorization System via RESTful operations.
Document classification with generative AI
While Myriad’s existing solution achieved 94% accuracy, misclassifications occurred due to structural similarities, overlapping content, and shared formatting patterns across document types. This semantic ambiguity made it difficult to distinguish between similar documents. We guided Myriad on prompt optimization techniques that used LLM’s contextual understanding capabilities. This approach moved beyond pattern matching to enable semantic analysis of document context and purpose, identifying distinguishing features that human experts recognize but previous automated systems missed.
AI-driven prompt engineering for document classification
We developed class definitions with distinguishing characteristics between similar document types. To identify these differentiators, we provided document samples from each class to Anthropic Claude Sonnet 3.7 on Amazon Bedrock with model reasoning enabled (a feature that allows the model to demonstrate its step-by-step analysis process). The model identified distinguishing features between similar document classes, which Myriad’s subject matter experts refined and incorporated into the GenAI IDP Accelerator’s Pattern 2 config file for document classification prompts.
Format-based classification strategies
We used document structure and formatting as key differentiators to distinguish between similar document types that shared comparable content but differed in structure. We enabled the classification models to recognize format-specific characteristics such as layout structures, field arrangements, and visual elements, allowing the system to differentiate between documents that textual content alone cannot distinguish. For example, lab reports and test results both contain patient information and medical data, but lab reports display numerical values in tabular format while test results follow a narrative format. We instructed the LLM: “Lab reports contain numerical results organized in tables with reference ranges and units. Test results present findings in paragraph format with clinical interpretations.”
Implementing negative prompting for enhanced accuracy
We implemented negative prompting techniques to resolve confusion between similar documents by explicitly instructing the model what classifications to avoid. This approach added exclusionary language to classification prompts, specifying characteristics that should not be associated with each document type. Initially, the system frequently misclassified Test Request Forms (TRFs) as Test Results due to confusion between patient medical history and lab measurements. Adding a negative prompt like “These forms contain patient medical history. DO NOT confuse them with test results which contain current/recent lab measurements” to the TRF definition improved the classification accuracy by 4%. By providing explicit guidance on common misclassification patterns, the system avoided typical errors and confusion between similar document types.
Model selection for cost and performance optimization
Model selection drives optimal cost-performance at scale, so we conducted comprehensive benchmarking using the GenAI IDP Accelerator’s evaluation framework. We tested four foundation models—Amazon Nova Lite, Amazon Nova Pro, Amazon Nova Premier, and Anthropic Claude Sonnet 3.7—using 1,200 healthcare documents across three document classes: Test Request Forms, Lab Results, and Insurance. We assessed each model using three critical metrics: classification accuracy, processing latency, and cost per document. The accelerator’s cost tracking enabled direct comparison of operational expenses across different model configurations, ensuring performance improvements translate into measurable business value at scale.
The evaluation results demonstrated that Amazon Nova Pro achieved optimal balance for Myriad’s use case. We transitioned from Myriad’s Amazon Comprehend implementation to Amazon Nova Pro with optimized prompts for document classification, achieving significant improvements: classification accuracy increased from 94% to 98%, processing costs decreased by 77%, and processing speed improved by 80%—reducing classification time from 8.5 minutes to 1.5 minutes per document.
Automating Key Information Extraction with generative AI
Myriad’s information extraction was manual, requiring up to 10 full-time employees contributing 78 hours daily in the Women’s Health unit alone, which created operational bottlenecks and scalability constraints. Automating healthcare KIE presented challenges: checkbox fields required distinguishing between marking styles (checkmarks, X’s, handwritten marks); documents contained ambiguous visual elements like overlapping marks or content spanning multiple fields; extraction needed contextual understanding to differentiate clinical distinctions and locate information across varying document formats. We worked with Myriad to develop an automated KIE solution, implementing the following optimization techniques to address extraction complexity.
Enhanced OCR configuration for checkbox recognition
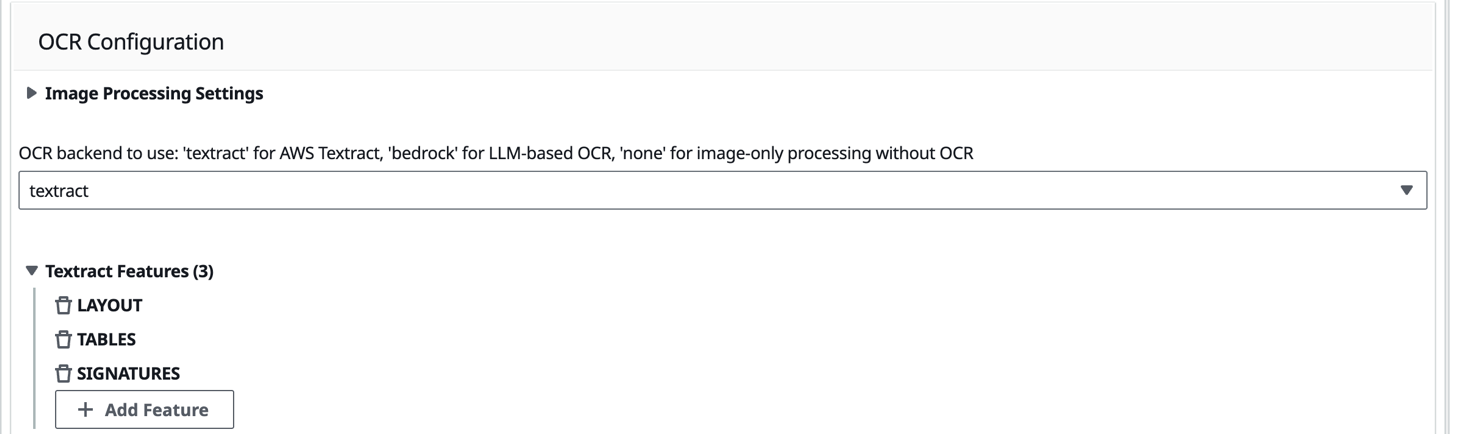
To address checkbox identification challenges, we enabled Amazon Textract’s specialized TABLES and FORMS features on the GenAI IDP Accelerator portal as shown in the following image, to improve OCR discrimination between selected and unselected checkbox elements. These features enhanced the system’s ability to detect and interpret marking styles found in medical forms.
We enhanced accuracy by incorporating visual cues into the extraction prompts. We updated the prompts with instructions such as “look for visible marks in or around the small square boxes (✓, x, or handwritten marks)” to guide the language model in identifying checkbox selections. This combination of enhanced OCR capabilities and targeted prompting improved checkbox extraction in medical forms.
Visual context learning through few-shot examples
Configuring Textract and improving prompts alone could not handle complex visual elements effectively. We implemented a multimodal approach that sent both document images and extracted text from Textract to the foundation model, enabling simultaneous analysis of visual layout and textual content for accurate extraction decisions. We implemented few-shot learning by providing example document images paired with their expected extraction outputs to guide the model’s understanding of various form layouts and marking styles. Multiple document image examples with their correct extraction patterns create lengthy LLM prompts. We leveraged the GenAI IDP Accelerator’s built-in integration with Amazon Bedrock’s prompt caching feature to reduce costs and latency. Prompt caching stores lengthy few-shot examples in memory for 5 minutes—when processing multiple similar documents within that timeframe, Bedrock reuses cached examples instead of reprocessing them, reducing both cost and processing time.
Chain of thought reasoning for complex extraction
While this multimodal approach improved extraction accuracy, we still faced challenges with overlapping and ambiguous tick marks in complex form layouts. To perform well in ambiguous and complex situations, we used Amazon Nova Premier and implemented Chain of Thought reasoning to have the model think through extraction decisions step-by-step using thinking tags. For example:
Additionally, we included reasoning explanations in the few-shot examples, demonstrating how we reached conclusions in ambiguous cases. This approach enabled the model to work through complex visual evidence and contextual clues before making final determinations, improving performance with ambiguous tick marks.
Testing across 32 document samples with varying complexity levels via the GenAI IDP Accelerator revealed that Amazon Textract with Layout, TABLES, and FORMS features enabled, paired with Amazon Nova Premier’s advanced reasoning capabilities and the inclusion of few-shot examples, delivered the best results. The solution achieved 90% accuracy (same as human evaluator baseline accuracy) while processing documents in approximately 1.3 minutes each.
Results and business impact
Through our new solution, we delivered measurable improvements that met the business goals established at the project outset:
Document classification performance:
- We increased accuracy from 94% to 98% through prompt optimization techniques for Amazon Nova Pro, including AI-driven prompt engineering, document-format based classification strategies, and negative prompting.
- We reduced classification costs by 77% (from 3.1 to 0.7 cents per page) by migrating from Amazon Comprehend to Amazon Nova Pro with optimized prompts.
- We reduced classification time by 80% (from 8.5 to 1.5 minutes per document) by choosing Amazon Nova Pro to provide a low-latency and cost-effective solution.
New automated Key Information Extraction performance:
- We achieved 90% extraction accuracy (same as the baseline manual process): Delivered through a combination of Amazon Textract’s document analysis capabilities, visual context learning through few-shot examples and Amazon Nova Premier’s reasoning for complex data interpretation.
- We achieved processing costs of 9 cents per page and processing time of 1.3 minutes per document compared to manual baseline requiring up to 10 full-time employees working 78 hours daily per business unit.
Business impact and rollout
Myriad has planned a phased rollout beginning with document classification. They plan to launch our new classification solution in the Women’s Health business unit, followed by Oncology and Mental Health divisions. As a result of our work, Myriad will realize up to $132K in annual savings in their document classification costs. The solution reduces each prior authorization submission time by 2 minutes—specialists now complete orders in four minutes instead of six minutes due to faster access to tagged documents. This improvement saves 300 hours monthly across 9,000 prior authorizations in Women’s Health alone, equivalent to 50 hours per prior authorization specialist.
These measurable improvements have transformed Myriad’s operations, as their engineering leadership confirms:
“Partnering with the GenAIIC to migrate our Intelligent Document Processing solution from AWS Comprehend to Bedrock has been a transformative step forward. By improving both performance and accuracy, the solution is projected to deliver savings of more than $10,000 per month. The team’s close collaboration with Myriad’s internal engineering team delivered a high-quality, scalable solution, while their deep expertise in advanced language models has elevated our capabilities. This has been an excellent example of how innovation and partnership can drive measurable business impact.”
– Martyna Shallenberg, Senior Director of Software Engineering, Myriad Genetics
Conclusion
The AWS GenAI IDP Accelerator enabled Myriad’s rapid implementation, providing a flexible framework that reduced development time. Healthcare organizations need tailored solutions—the accelerator delivers extensive customization capabilities that let users adapt solutions to specific document types and workflows without requiring extensive code changes or frequent redeployment during development. Our approach demonstrates the power of strategic prompt engineering and model selection. We achieved high accuracy in a specialized domain by focusing on prompt design, including negative prompting and visual cues. We optimized both cost and performance by selecting Amazon Nova Pro for classification and Nova Premier for complex extraction—matching the right model to each specific task.
Explore the solution for yourself
Organizations looking to improve their document processing workflows can experience these benefits firsthand. The open source GenAI IDP Accelerator that powered Myriad’s transformation is available to deploy and test in your environment. The accelerator’s straightforward setup process lets users quickly evaluate how generative AI can transform document processing challenges.
Once you’ve explored the accelerator and seen its potential impact on your workflows, reach out to the AWS GenAIIC team to explore how the GenAI IDP Accelerator can be customized and optimized for your specific use case. This hands-on approach ensures you can make informed decisions about implementing intelligent document processing in your organization.
About the authors
 Priyashree Roy is a Data Scientist II at the AWS Generative AI Innovation Center, where she applies her expertise in machine learning and generative AI to develop innovative solutions for strategic AWS customers. She brings a rigorous scientific approach to complex business challenges, informed by her PhD in experimental particle physics from Florida State University and postdoctoral research at the University of Michigan.
Priyashree Roy is a Data Scientist II at the AWS Generative AI Innovation Center, where she applies her expertise in machine learning and generative AI to develop innovative solutions for strategic AWS customers. She brings a rigorous scientific approach to complex business challenges, informed by her PhD in experimental particle physics from Florida State University and postdoctoral research at the University of Michigan.
 Mofijul Islam is an Applied Scientist II and Tech Lead at the AWS Generative AI Innovation Center, where he helps customers tackle customer-centric research and business challenges using generative AI, large language models (LLM), multi-agent learning, code generation, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual natural language processing (NLP), and multitask learning. His research has been published in top-tier conferences like NeurIPS, International Conference on Learning Representations (ICLR), Empirical Methods in Natural Language Processing (EMNLP), Society for Artificial Intelligence and Statistics (AISTATS), and Association for the Advancement of Artificial Intelligence (AAAI), as well as Institute of Electrical and Electronics Engineers (IEEE) and Association for Computing Machinery (ACM) Transactions.
Mofijul Islam is an Applied Scientist II and Tech Lead at the AWS Generative AI Innovation Center, where he helps customers tackle customer-centric research and business challenges using generative AI, large language models (LLM), multi-agent learning, code generation, and multimodal learning. He holds a PhD in machine learning from the University of Virginia, where his work focused on multimodal machine learning, multilingual natural language processing (NLP), and multitask learning. His research has been published in top-tier conferences like NeurIPS, International Conference on Learning Representations (ICLR), Empirical Methods in Natural Language Processing (EMNLP), Society for Artificial Intelligence and Statistics (AISTATS), and Association for the Advancement of Artificial Intelligence (AAAI), as well as Institute of Electrical and Electronics Engineers (IEEE) and Association for Computing Machinery (ACM) Transactions.
 Nivedha Balakrishnan is a Deep Learning Architect II at the AWS Generative AI Innovation Center, where she helps customers design and deploy generative AI applications to solve complex business challenges. Her expertise spans large language models (LLMs), multimodal learning, and AI-driven automation. She holds a Master’s in Applied Data Science from San Jose State University and a Master’s in Biomedical Engineering from Linköping University, Sweden. Her previous research focused on AI for drug discovery and healthcare applications, bridging life sciences with machine learning.
Nivedha Balakrishnan is a Deep Learning Architect II at the AWS Generative AI Innovation Center, where she helps customers design and deploy generative AI applications to solve complex business challenges. Her expertise spans large language models (LLMs), multimodal learning, and AI-driven automation. She holds a Master’s in Applied Data Science from San Jose State University and a Master’s in Biomedical Engineering from Linköping University, Sweden. Her previous research focused on AI for drug discovery and healthcare applications, bridging life sciences with machine learning.
 Martyna Shallenberg is a Senior Director of Software Engineering at Myriad Genetics, where she leads cross-functional teams in building AI-driven enterprise solutions that transform revenue cycle operations and healthcare delivery. With a unique background spanning genomics, molecular diagnostics, and software engineering, she has scaled innovative platforms ranging from Intelligent Document Processing (IDP) to modular LIMS solutions. Martyna is also the Founder & President of BioHive’s HealthTech Hub, fostering cross-domain collaboration to accelerate precision medicine and healthcare innovation.
Martyna Shallenberg is a Senior Director of Software Engineering at Myriad Genetics, where she leads cross-functional teams in building AI-driven enterprise solutions that transform revenue cycle operations and healthcare delivery. With a unique background spanning genomics, molecular diagnostics, and software engineering, she has scaled innovative platforms ranging from Intelligent Document Processing (IDP) to modular LIMS solutions. Martyna is also the Founder & President of BioHive’s HealthTech Hub, fostering cross-domain collaboration to accelerate precision medicine and healthcare innovation.
 Brode Mccrady is a Software Engineering Manager at Myriad Genetics, where he leads initiatives in AI, revenue systems, and intelligent document processing. With over a decade of experience in business intelligence and strategic analytics, Brode brings deep expertise in translating complex business needs into scalable technical solutions. He holds a degree in Economics, which informs his data-driven approach to problem-solving and business strategy.
Brode Mccrady is a Software Engineering Manager at Myriad Genetics, where he leads initiatives in AI, revenue systems, and intelligent document processing. With over a decade of experience in business intelligence and strategic analytics, Brode brings deep expertise in translating complex business needs into scalable technical solutions. He holds a degree in Economics, which informs his data-driven approach to problem-solving and business strategy.
 Randheer Gehlot is a Principal Customer Solutions Manager at AWS who specializes in healthcare and life sciences transformation. With a deep focus on AI/ML applications in healthcare, he helps enterprises design and implement efficient cloud solutions that address real business challenges. His work involves partnering with organizations to modernize their infrastructure, enable innovation, and accelerate their cloud adoption journey while ensuring practical, sustainable outcomes.
Randheer Gehlot is a Principal Customer Solutions Manager at AWS who specializes in healthcare and life sciences transformation. With a deep focus on AI/ML applications in healthcare, he helps enterprises design and implement efficient cloud solutions that address real business challenges. His work involves partnering with organizations to modernize their infrastructure, enable innovation, and accelerate their cloud adoption journey while ensuring practical, sustainable outcomes.
Acknowledgements
We would like to thank Bob Strahan, Kurt Mason, Akhil Nooney and Taylor Jensen for their significant contributions, strategic decisions and guidance throughout.


