

AI-powered apps and AI-powered service delivery are key differentiators in the enterprise space today. A generative AI-based resource can greatly reduce the onboarding time for new employees, enhance enterprise search, assist in drafting content, check for compliance, understand the legal language of data, and more.
Generative AI applications are an emerging and sought-after solution in the enterprise world for customer care centers, customer relationship management centers, and help desks.
Infosys Topaz, an AI-first offering that accelerates business value for enterprises using generative AI, is integrating AWS generative AI capabilities to future proof enterprise AI solutions including Infosys Cortex, Infosys Personalized Smart Video (PSV), Infosys Conversational AI Suite, Infosys Live Enterprise Automation Platform (LEAP), and Infosys Cyber Next.
In this post, we examine the use case of a large energy supplier whose technical help desk support agents answer customer calls and support meter technicians in the field. We use Amazon Bedrock, along with capabilities from Infosys Topaz, to build a generative AI application that can reduce call handling times, automate tasks, and improve the overall quality of technical support.
Business challenges
Meter technicians go to customer locations to install, exchange, service, and repair meters. Sometimes they call support agents from the technical help desk to get guidance and support to fix issues that they can’t fix by themselves. The approximate volume of these calls is 5,000 per week, approximately 20,000 per month.
Some of the challenges faced by support agents and meter technicians include:
- Locating the appropriate information or resources to address inquiries or concerns effectively.
- The average handling time for these calls varies based on the issue category, but calls in the top 10 categories, which represent over 60% of calls, are over 5 minutes.
- 60–70% issues are repetitive, and the rest are new issues.
Maintaining an adequate workforce to provide prompt responses can be costly. It’s expensive and not scalable to hire more support agents and train them with the knowledge needed to provide support. We built an AI-powered technical help desk that can ingest past call transcripts and new call transcripts in near real time. This will help support agents provide resolutions based on past calls, thereby reducing manual search time so they can attend to other priorities.
Solution overview
The solution involves creating a knowledge base by ingesting and processing call transcripts, so that the AI assistant can provide resolutions based on history. The benefits of an AI-powered technical help desk include:
- Providing all-day availability
- Saving effort for the help desk agents
- Allowing businesses to focus on new issues
- Reducing wait time and shortening call duration
- Automating actions that the help desk agents take on the backend based on their analysis of the issue
- Improving the quality of technical help desk responses, and thereby communication and outcomes
This post showcases the implementation details, including user-based access controls, caching mechanisms for efficient FAQ retrieval and updates, user metrics tracking, and response generation with time-tracking capabilities.
The following diagram shows the flow of data and processes from left to right, starting with call transcripts, going through preprocessing, storage, and retrieval, and ending with user interaction and response generation. It emphasizes the role-based access control throughout the system.
We used Amazon Bedrock because it integrates seamlessly with other AWS services shown in the diagram, such as AWS Step Functions, Amazon DynamoDB, and Amazon OpenSearch Service. This integration improves data flow and management within a single cloud system.
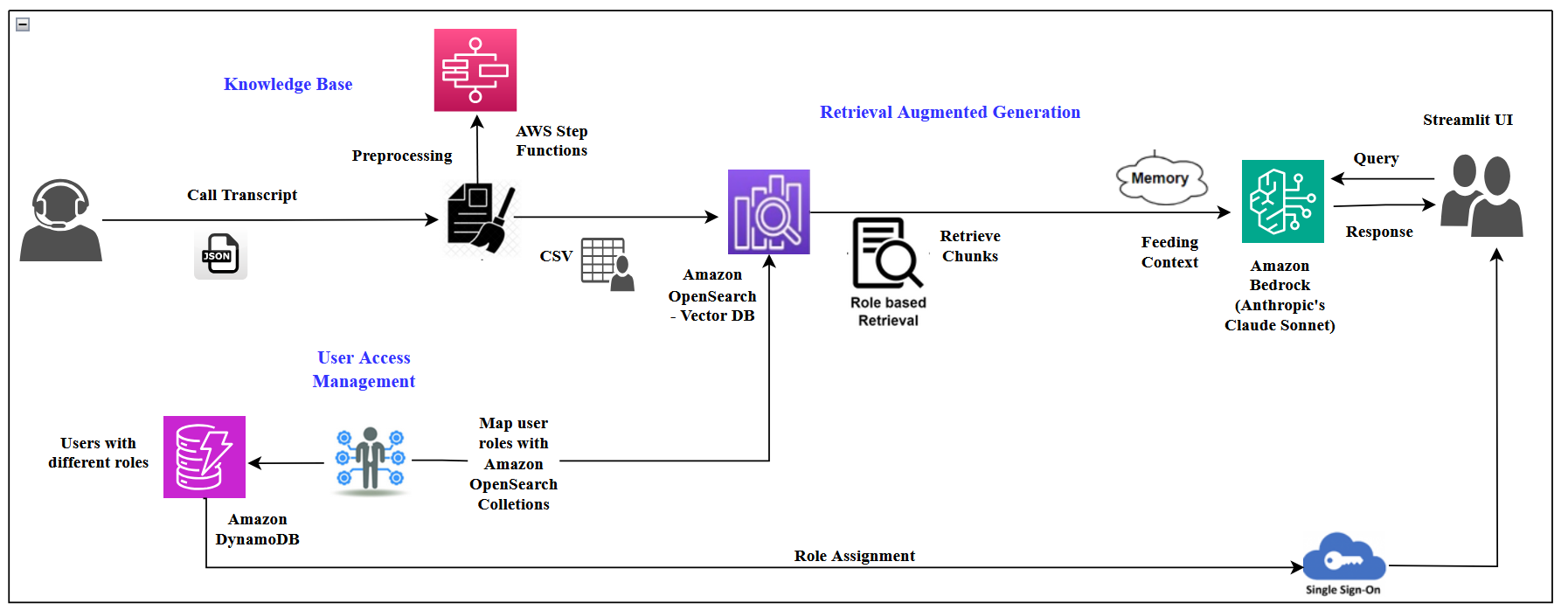
Building the knowledge base: Data flow
Calls to the technical help desk are recorded for quality and analysis purposes, and the transcripts are stored in JSON format in an AWS Simple Storage Service (Amazon S3) bucket.
The conversations are parsed into a CSV file for sorting and a large language model (LLM), such as Anthropic’s Claude Sonnet on Amazon Bedrock, is used to summarize the conversation and determine if the context has useful information, based on the length of the call, key words that indicate relevant context, and so on.
The shortlisted conversations are chunked, and embeddings are generated and stored in an Amazon OpenSearch Serverless vector store. The conversations determined to be irrelevant go into another S3 bucket for future reference. This process is automated, as shown in the following figure.
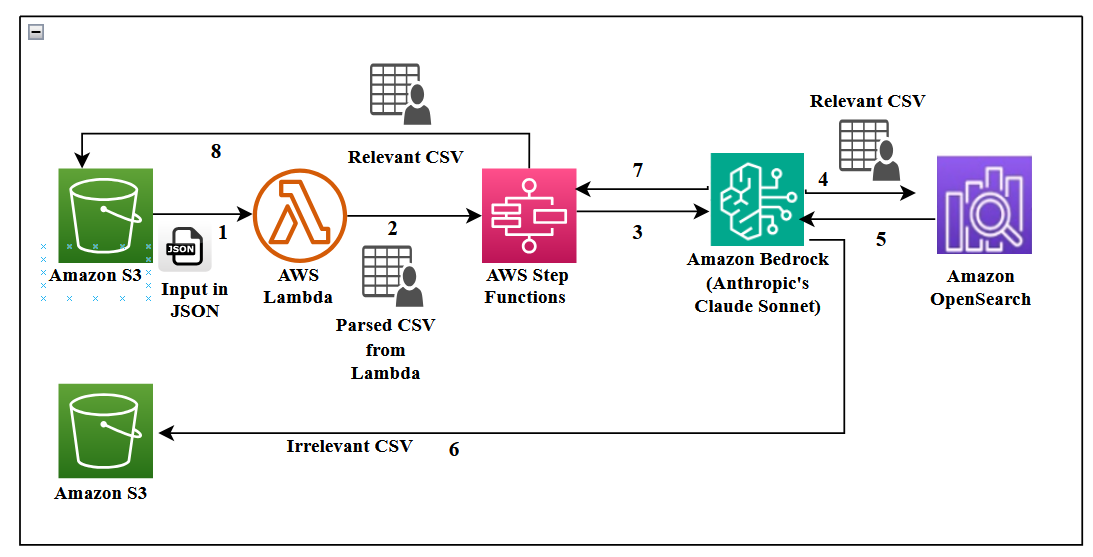
A virtual assistant is then built on top of the knowledge base that will assist the support agent.
The conversations are parsed into a CSV file for simple sorting and an LLM such as Anthropic’s Claude Sonnet on Amazon Bedrock is used to summarize the conversation and determine if the context has useful information, based on the length of the call, key words that indicate relevant context, and so on.
An event-driven AWS Lambda function is triggered when new call transcripts are loaded into the S3 bucket. This will trigger a Step Functions workflow.
From the raw CSV file of call transcripts, only a few fields are extracted: a contact ID that is unique for a particular call session between a customer and a support agent, the participant column indicating the speaker (who can be either a support agent or a customer) and the content column, which is the conversation.
To build the knowledge base, we used Step Functions to ingest the raw CSV files, as shown in the following workflow.
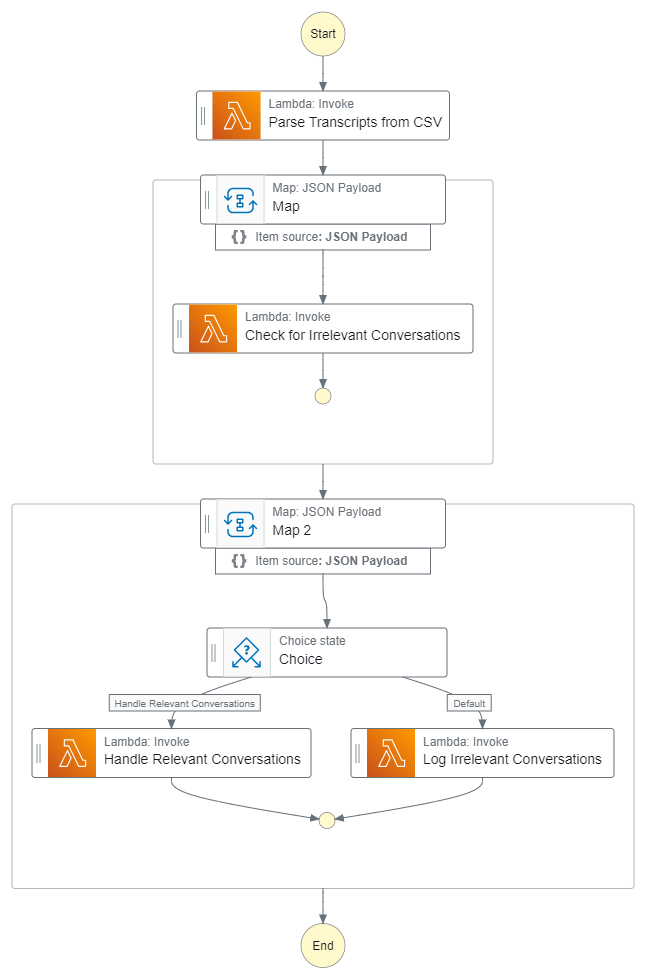
The automated workflow begins when a user uploads the JSON file to an S3 bucket.
- The Step Functions workflow receives the Amazon S3 URL of the CSV transcripts from a Lambda function. The
contactidis unique for a particular call session between the customer and the agent, who are the participants, and thecontentis the actual conversation. - The Lambda function (Parse Transcripts from CSV) uses this Amazon S3 URL to download the CSV files and uses Pandas to preprocess the CSV in a format with the contact ID and transcript only. Conversations with the same contact ID are concatenated into a single row.
- The second step is a classification task that ingests, classifies, and keeps or discards conversions. The conversations are passed to the map state. In map state, conversations are handled concurrently. For each conversation row, this state triggers concurrent execution of another Lambda function (Check for Irrelevant Conversations) that will classify each conversation as relevant or irrelevant.
- For this classification task, the Lambda function uses Anthropic’s Claude Sonnet model on Amazon Bedrock. It uses zero-shot chain-of-thought prompting, to first summarize the conversation and then to determine the relevance. If the conversation is disconnected or disjointed (because of signal disturbances or other reasons), or has no meaningful context (when the agent is unable to provide resolution), it’s classified as irrelevant.
- Finally, the map state takes each instance of the conversation (classified as relevant or irrelevant) and passes to the choice state, which will log the irrelevant conversations into an S3 bucket and relevant conversations are passed to another Lambda function (Handle Relevant Conversations) for further processing.
- The final Lambda function (Log Irrelevant Conversations) reads the relevant conversations and generates the summary, problem, and resolution steps using Anthropic’s Claude Sonnet. The summary generated is used for creating the summary embeddings.
The following is an example of an irrelevant conversation that is discarded.
| Contactid | Participant | Content |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Help the school speaking |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Your morning call it said Chris Simpson near me, TX 75 is, uh, locked out spinning disc |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | No problem. What’s your carry, please? |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Thanks to see 27492. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Thank you. Right, you’ll be kicked off. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | Single noise. Anything anyway, mate. When you look back in, you’ll be fine |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Yep. |
66da378c-8d74-467b-86ca-7534158b63c2 |
CUSTOMER | Alright, Right. Thank you. Choose them. |
66da378c-8d74-467b-86ca-7534158b63c2 |
AGENT | I think she’s made a bit Right bye. |
The following is an example of a relevant conversation.
| Contactid | Participant | Content |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Hello. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Help those gathers Reagan. Yes. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Get up, and then I’ll speak to someone about clearing the cash on my T C 75. So, can do. Off job certainly things because you won’t let me sorry minutes, just saying Could not establish network connection. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Yeah, I’ve got a signal. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yeah, it’s not trying to do is connected. We got three D 14. It’s up, right? |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | What should happen because I’m in the four G area. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yeah, dragged down the screen twice from the top for me. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Yep. He? Yeah. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yep. And check that survey is eight hasn’t turned itself off. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | Need. Okay, try again. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | There you go, right showing us connected. We can |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
CUSTOMER | All right. Can you clear the cat 12 can signal is day to see this message. Contact the T. H. D. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | Yep. |
079a57bf-9700-45d3-bbd9-11d2d41370c7 |
AGENT | There you go. That should take you out any second, okay? |
The following table shows the final knowledge base schema.
| k_id | conversation_history | Summary | Problem | resolution_steps | summary_embeddings |
| 1 | AGENT: Hi, how can I help you CUSTOMER: Hi, I am facing a black screen issue.… | Customer is facing with a issue … | Black Screen issue |
… |
[0.5078125,-0.071777344,0.15722656,0.46679688,0.56640625,-0.037353516,-0.08544922,0.00012588501, …] |
Building an effective RAG pipeline
The success of retrieval systems relies on an effective embedding model. The Amazon Titan Text Embeddings model is optimized for text retrieval to enable Retrieval Augmented Generation (RAG). Instead of processing massive documents at the same time, we used chunking strategies to improve retrieval. We used a chunk size of 1,000 with an overlapping window of 150–200 for best results. Chunking combined with page boundaries is a simple yet highly effective approach. Sentence window retrieval also returns accurate results.
Prompting techniques play a crucial role in obtaining effective results. For example, instead of “guidelines for smart meter installation,” an expanded prompt such as “instructions, procedures, regulations, and best practices along with agent experiences for installation of a smart meter” yields better results.
Building production-ready RAG applications requires a performant vector database as well. The vector engine for OpenSearch Serverless provides a scalable and high-performing vector storage and search capability; key features include adding, updating, and deleting vector embeddings in near real time without impacting query performance. See Build a contextual chatbot application using Amazon Bedrock Knowledge Bases for more information.
Security considerations
This architecture implements comprehensive security measures across the components. We use AWS Secrets Manager to securely store and manage sensitive credentials, API keys, and database passwords, with automatic rotation policies in place. S3 buckets are encrypted using AWS Key Management Service (AWS KMS) with AES-256 encryption, and versioning is enabled for audit purposes. Personally identifiable information (PII) is handled with extreme care— PII data is encrypted and access is strictly controlled through AWS Identity and Access Management (IAM) policies and AWS KMS. For OpenSearch Serverless implementation, we make sure data is encrypted both at rest using AWS KMS and in transit using TLS 1.2. Session management includes timeout for inactive sessions, requiring re-authentication for continued access. The system interacts with access control list (ACL) data stored in DynamoDB through a secure middleware layer, where the DynamoDB table is encrypted at rest using AWS managed KMS keys. Data transmissions between services are encrypted in transit using TLS 1.2, and we maintain end-to-end encryption across our entire infrastructure. Access controls are granularly defined and regularly audited through AWS CloudTrail.
Implementing role-based access control
We used three different personas to implement role-based access control: an administrator with full access, a technical desk analyst with a medium level of access, and a technical agent with minimal access. We used OpenSearch Serverless collections to manage different access levels. Different call transcripts are ingested into different collections; this is to enable user access to the content they are authorized to based on their roles. A list of user IDs and their roles and allowed access are stored in a DynamoDB table along with the OpenSearch collection and index name.
We used the authenticate.login method in a Streamlit authenticator to retrieve the user ID.
User interface and agent experience
We used Streamlit as a frontend framework to build the TECHNICAL HELP DESK, with access to the content controlled by the user’s role. The UI features an FAQ section displayed at the top of the main page and a search metrics insights section in the sidebar, as shown in the following screenshot.
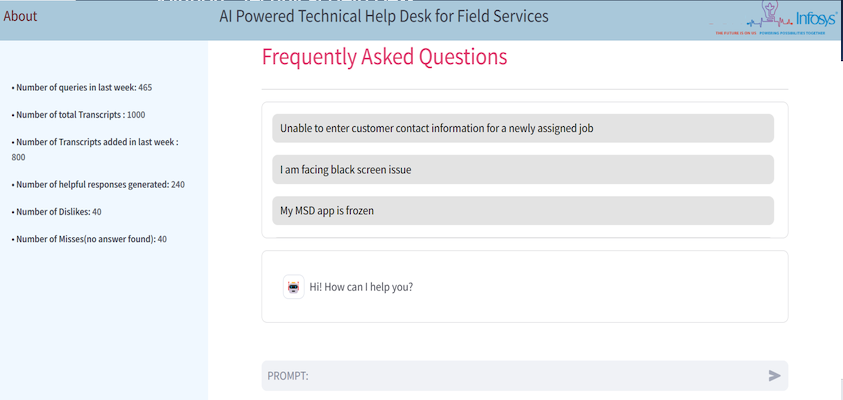
The UI includes the following components:
- Conversation section – The conversation section contains interactions between the user and the help desk assistant. Users can provide feedback by choosing either the like or dislike button for each response received, as shown in the following screenshot. This feedback is persisted in a DynamoDB table.
- User metrics insights – As shown in the following screenshot, the sidebar contains metrics information, including:
- Number of queries in the last week
- Number of total transcripts
- Number of transcripts added in the last week
- Number of helpful responses generated
- Number of dislikes
- Number of misses (no answer found)

These fields are updated asynchronously after each user query. Additional metrics are also stored, such as sentiment, tone of the speakers, nature of responses generated, and satisfaction percentage.
- FAQ – The queries are stored in a DynamoDB table along with a query count column. When the help desk agent signs in, the queries with the most counts are displayed in this section, as shown in the following table.
| Partition key | Sort key | Global secondary index |
| Document name | Questions | Counter |
| Microsoft Authenticator | Overview of MFA | 1 |
| What is TAP in MFA | 2 | |
| Common issues in MFA | 1 |
The Counter column is created as the global secondary index to retrieve the top five FAQs.
After the user submits a query, the technical help desk fetches the top similar items from the knowledge base. This is compared with the user’s query and, when a match is found, the Counter column is incremented.
Cache management
We used the st.cache_data() function in Streamlit to store the valid results in memory. The results are persisted across the user sessions.
The caching function employs an internal hashing mechanism that can be overridden if required. The cached data can be stored either in memory or on disk. Additionally, we can set the data persistence duration as needed for the use case. Cache invalidation or updates can be done when the data changes or after every hour. This, along with the FAQ section, has significantly enhanced performance of the technical help desk, creating faster response times and improving the user experience for customers and support agents.
Conclusion
In this post, we showed you how we built a generative AI application to significantly reduce call handling times, automate repetitive tasks, and improve the overall quality of technical support.
The enterprise AI assistant from the Infosys Agentic Foundry, part of Infosys Topaz, now handles 70% of the previously human-managed calls. For the top 10 issue categories, average handling time has decreased from over 5 minutes to under 2 minutes, a 60% improvement. The continuous expansion of the knowledge base has reduced the percentage of issues requiring human intervention from 30–40% to 20% within the first 6 months after deployment.
Post-implementation surveys show a 30% increase in customer satisfaction scores related to technical support interactions.
To learn more about other solutions built with Amazon Bedrock and Infosys Topaz, see Create a multimodal assistant with advanced RAG and Amazon Bedrock and Infosys Topaz Unlocks Insights with Advanced RAG Processing for Oil & Gas Drilling Data.
About the authors
 Meenakshi Venkatesan is a Principal Consultant at Infosys and a part of the AWS Centre Of Excellence at Infosys Topaz. She helps design, develop, and deploy solutions in AWS environments and has interests in exploring the new offerings and services.
Meenakshi Venkatesan is a Principal Consultant at Infosys and a part of the AWS Centre Of Excellence at Infosys Topaz. She helps design, develop, and deploy solutions in AWS environments and has interests in exploring the new offerings and services.
 Karthikeyan Senthilkumar is a Senior Systems Engineer at Infosys and a part of the AWS COE at iCETS. He specializes in AWS generative AI and database services.
Karthikeyan Senthilkumar is a Senior Systems Engineer at Infosys and a part of the AWS COE at iCETS. He specializes in AWS generative AI and database services.
 Aninda Chakraborty is a Senior Systems Engineer at Infosys and a part of the AWS COE at iCETS. He specializes in generative AI and is passionate about leveraging technology to create innovative solutions that drive progress in this field.
Aninda Chakraborty is a Senior Systems Engineer at Infosys and a part of the AWS COE at iCETS. He specializes in generative AI and is passionate about leveraging technology to create innovative solutions that drive progress in this field.
 Ashutosh Dubey is an accomplished software technologist and Technical Leader at Amazon Web Services, where he specializes in Generative AI solutions architecture. With a rich background in software development and data engineering, he architects enterprise-scale AI solutions that bridge innovation with practical implementation. A respected voice in the tech community, he regularly contributes to industry discourse through speaking engagements and thought leadership on Generative AI applications, Data engineering, and ethical AI practices.
Ashutosh Dubey is an accomplished software technologist and Technical Leader at Amazon Web Services, where he specializes in Generative AI solutions architecture. With a rich background in software development and data engineering, he architects enterprise-scale AI solutions that bridge innovation with practical implementation. A respected voice in the tech community, he regularly contributes to industry discourse through speaking engagements and thought leadership on Generative AI applications, Data engineering, and ethical AI practices.
 Vishal Srivastava is a Senior Solutions Architect with a deep specialization in Generative AI. In his current role, he collaborates closely with NAMER System Integrator (SI) partners, providing expert guidance to architect enterprise-scale AI solutions. Vishal’s expertise lies in navigating the complex landscape of AI technologies and translating them into practical, high-impact implementations for businesses. As a thought leader in the AI space, Vishal is actively engaged in shaping industry conversations and sharing knowledge. He is a frequent speaker at public events, webinars, and conferences, where he offers insights into the latest trends and best practices in Generative AI.
Vishal Srivastava is a Senior Solutions Architect with a deep specialization in Generative AI. In his current role, he collaborates closely with NAMER System Integrator (SI) partners, providing expert guidance to architect enterprise-scale AI solutions. Vishal’s expertise lies in navigating the complex landscape of AI technologies and translating them into practical, high-impact implementations for businesses. As a thought leader in the AI space, Vishal is actively engaged in shaping industry conversations and sharing knowledge. He is a frequent speaker at public events, webinars, and conferences, where he offers insights into the latest trends and best practices in Generative AI.
 Dhiraj Thakur is a Solutions Architect with Amazon Web Services, specializing in Generative AI and data analytics domains. He works with AWS customers and partners to architect and implement scalable analytics platforms and AI-driven solutions. With deep expertise in Generative AI services and implementation, end-to-end machine learning implementation, and cloud-native data architectures, he helps organizations harness the power of GenAI and analytics to drive business transformation. He can be reached via LinkedIn.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services, specializing in Generative AI and data analytics domains. He works with AWS customers and partners to architect and implement scalable analytics platforms and AI-driven solutions. With deep expertise in Generative AI services and implementation, end-to-end machine learning implementation, and cloud-native data architectures, he helps organizations harness the power of GenAI and analytics to drive business transformation. He can be reached via LinkedIn.


