

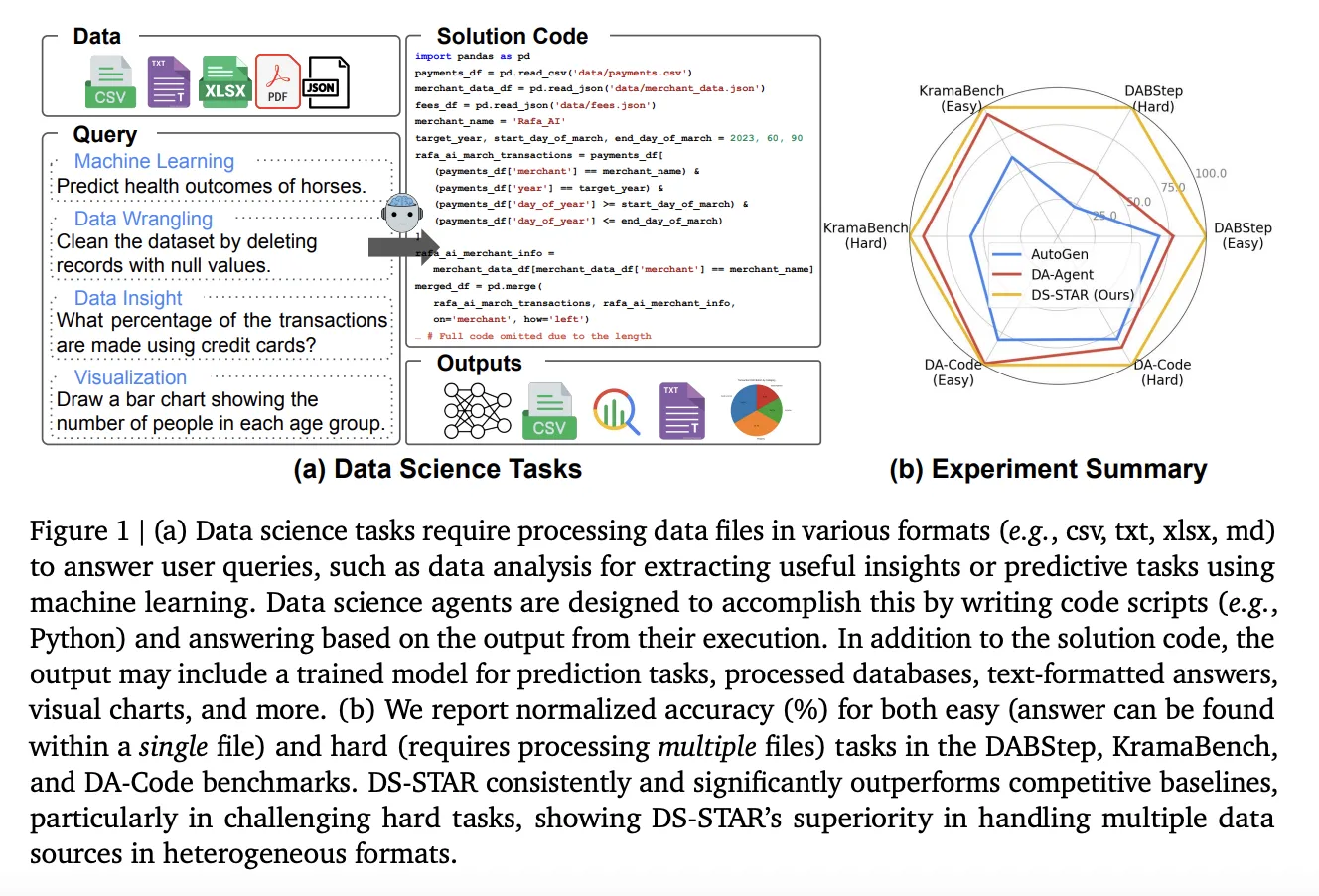
How do you turn a vague business style question over messy folders of CSV, JSON and text into reliable Python code without a human analyst in the loop? Google researchers introduce DS STAR (Data Science Agent via Iterative Planning and Verification), a multi agent framework that turns open ended data science questions into executable Python scripts over heterogeneous files. Instead of assuming a clean SQL database and a single query, DS STAR treats the problem as Text to Python and operates directly on mixed formats such as CSV, JSON, Markdown and unstructured text.
From Text To Python Over Heterogeneous Data
Existing data science agents often rely on Text to SQL over relational databases. This constraint limits them to structured tables and simple schema, which does not match many enterprise environments where data sits across documents, spreadsheets and logs.
DS STAR changes the abstraction. It generates Python code that loads and combines whatever files the benchmark provides. The system first summarizes every file, then uses that context to plan, implement and verify a multi step solution. This design allows DS STAR to work on benchmarks such as DABStep, KramaBench and DA Code, which expect multi step analysis over mixed file types and require answers in strict formats.

Stage 1: Data File Analysis With Aanalyzer
The first stage builds a structured view of the data lake. For each file (Dᵢ), the Aanalyzer agent generates a Python script (sᵢ_desc) that parses the file and prints essential information such as column names, data types, metadata and text summaries. DS STAR executes this script and captures the output as a concise description (dᵢ).
This process works for both structured and unstructured data. CSV files yield column level statistics and samples, while JSON or text files produce structural summaries and key snippets. The collection {dᵢ} becomes shared context for all later agents.

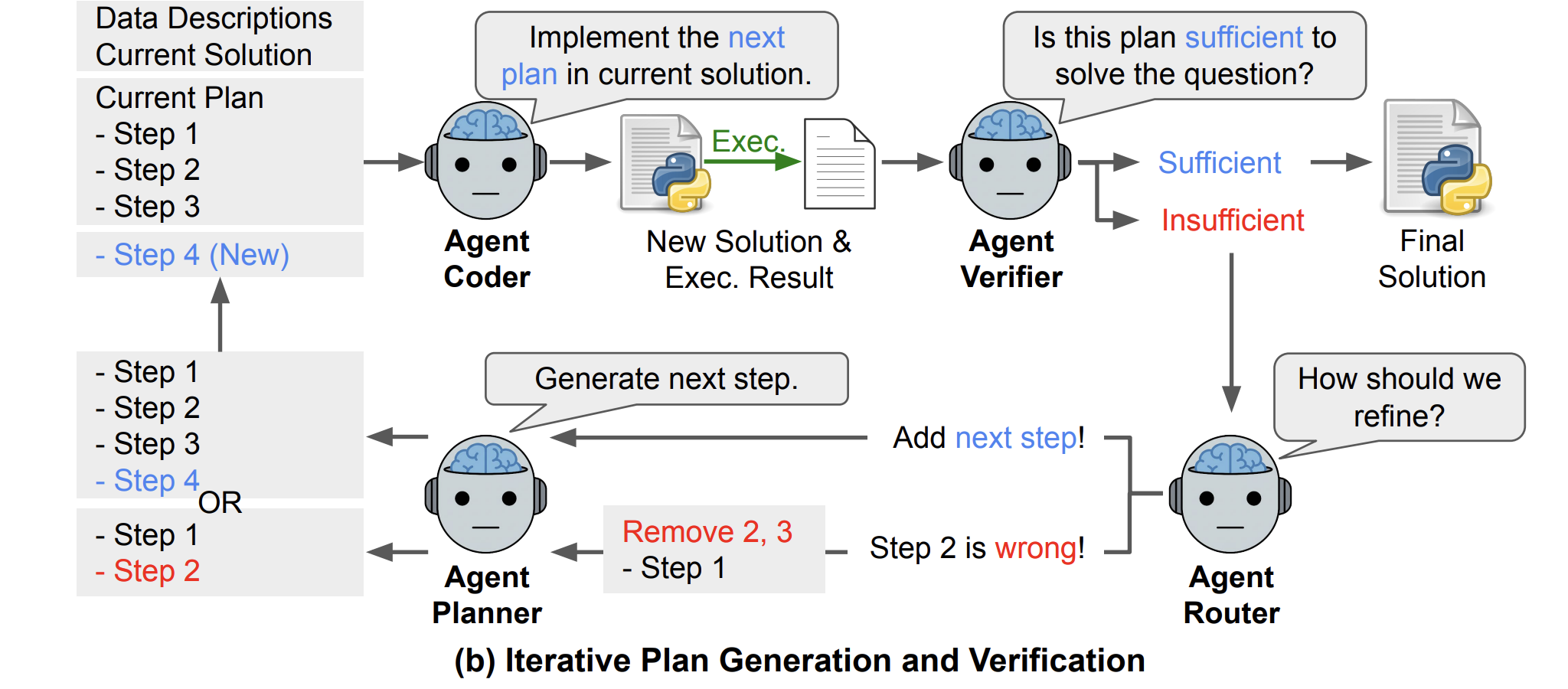
Stage 2: Iterative Planning, Coding And Verification
After file analysis, DS STAR runs an iterative loop that mirrors how a human uses a notebook.
- Aplanner creates an initial executable step (p₀) using the query and the file descriptions, for example loading a relevant table.
- Acoder turns the current plan (p) into Python code (s). DS STAR executes this code to obtain an observation (r).
- Averifier is an LLM based judge. It receives the cumulative plan, the query, the current code and its execution result and returns a binary decision, sufficient or insufficient.
- If the plan is insufficient, Arouter decides how to refine it. It either outputs the token Add Step, which appends a new step, or an index of an erroneous step to truncate and regenerate from.
Aplanner is conditioned on the latest execution result (rₖ), so each new step explicitly responds to what went wrong in the previous attempt. The loop of routing, planning, coding, executing and verifying continues until Averifier marks the plan sufficient or the system hits a maximum of 20 refinement rounds.
To satisfy strict benchmark formats, a separate Afinalyzer agent converts the final plan into solution code that enforces rules such as rounding and CSV output.
Robustness Modules, Adebugger And Retriever
Realistic pipelines fail on schema drift and missing columns. DS STAR adds Adebugger to repair broken scripts. When code fails, Adebugger receives the script, the traceback and the analyzer descriptions {dᵢ}. It generates a corrected script by conditioning on all three signals, which is important because many data centric bugs require knowledge of column headers, sheet names or schema, not only the stack trace.
KramaBench introduces another challenge, thousands of candidate files per domain. DS STAR handles this with a Retriever. The system embeds the user query and each description (dᵢ) using a pre trained embedding model and selects the top 100 most similar files for the agent context, or all files if there are fewer than 100. In the implementation, the research team used Gemini Embedding 001 for similarity search.
Benchmark Results On DABStep, KramaBench And DA Code
All main experiments run DS STAR with Gemini 2.5 Pro as the base LLM and allow up to 20 refinement rounds per task.
On DABStep, model only Gemini 2.5 Pro achieves 12.70 percent hard level accuracy. DS STAR with the same model reaches 45.24 percent on hard tasks and 87.50 percent on easy tasks. This is an absolute gain of more than 32 percentage points on the hard split and it outperforms other agents such as ReAct, AutoGen, Data Interpreter, DA Agent and several commercial systems recorded on the public leaderboard.

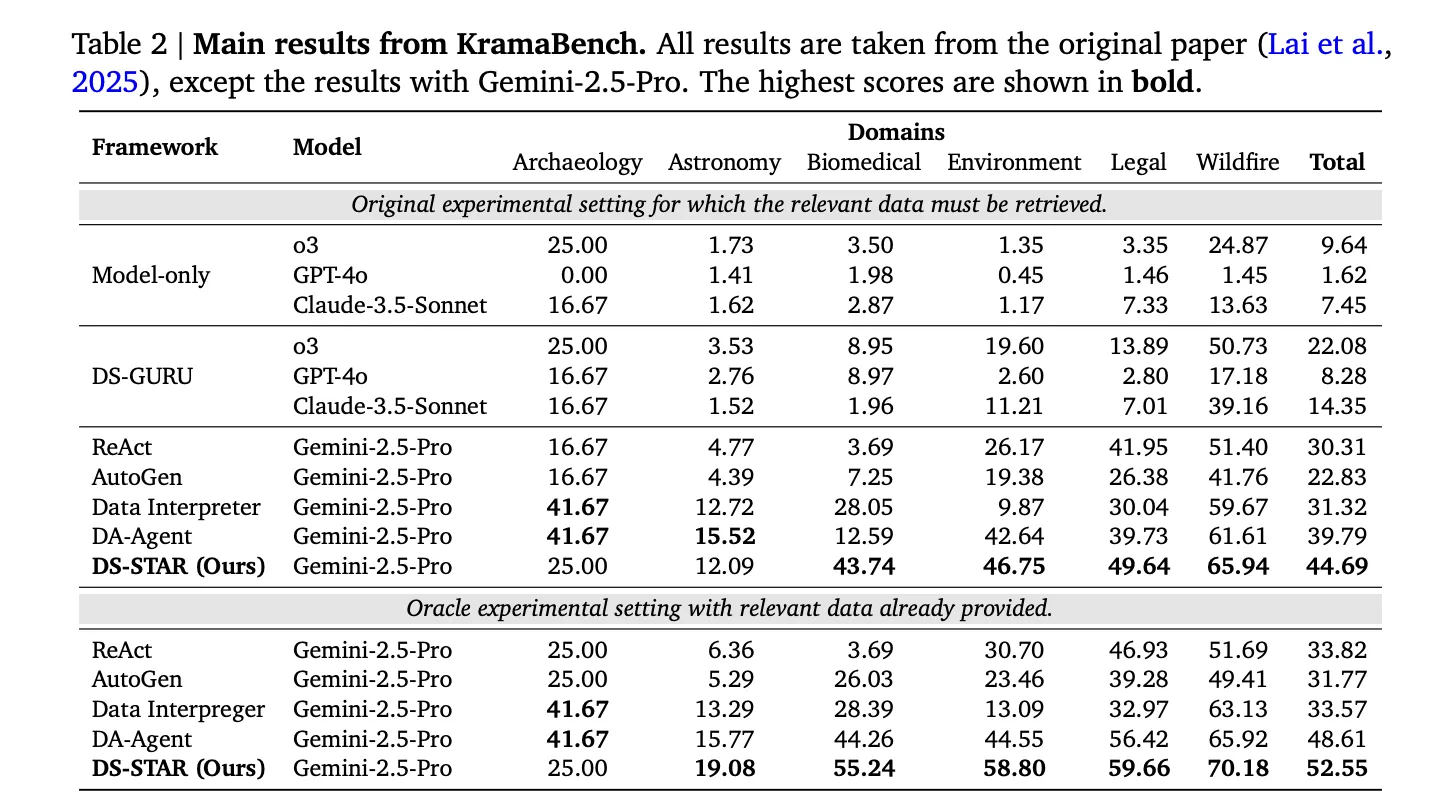
The Google research team reports that, compared to the best alternative system on each benchmark, DS STAR improves overall accuracy from 41.0 percent to 45.2 percent on DABStep, from 39.8 percent to 44.7 percent on KramaBench and from 37.0 percent to 38.5 percent on DA Code.

For KramaBench, which requires retrieving relevant files from large domain specific data lakes, DS STAR with retrieval and Gemini 2.5 Pro achieves a total normalized score of 44.69. The strongest baseline, DA Agent with the same model, reaches 39.79.
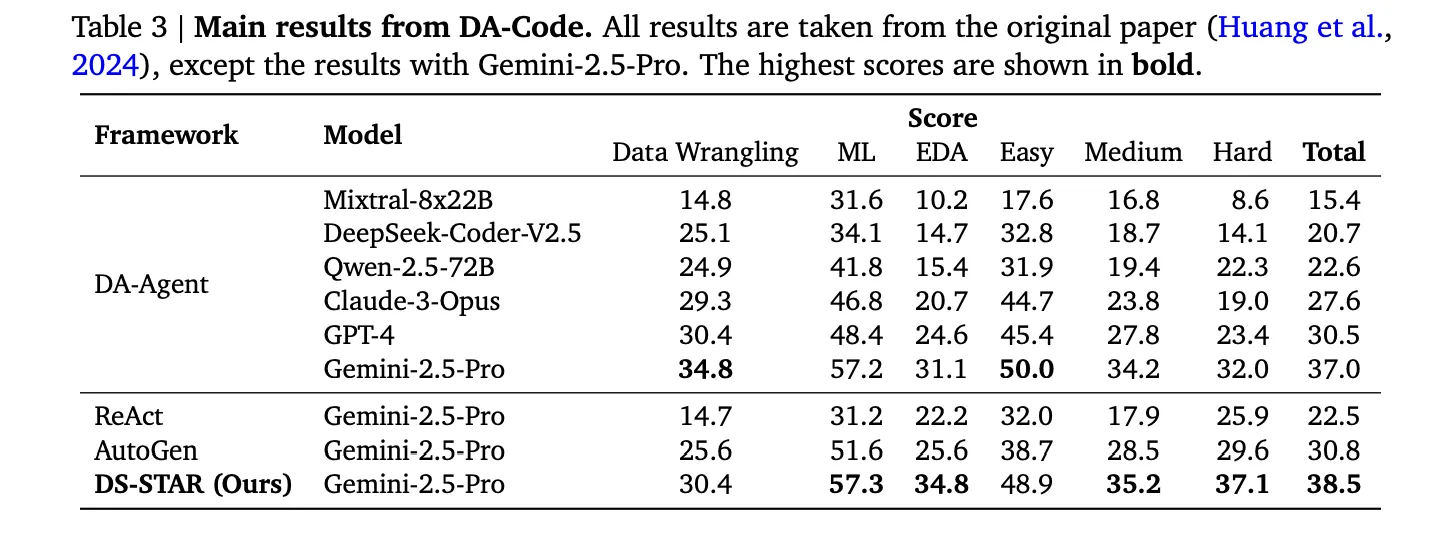
On DA Code, DS STAR again beats DA Agent. On hard tasks, DS STAR reaches 37.1 percent accuracy versus 32.0 percent for DA Agent when both use Gemini 2.5 Pro.
Key Takeaways
- DS STAR reframes data science agents as Text to Python over heterogeneous files such as CSV, JSON, Markdown and text, instead of only Text to SQL over clean relational tables.
- The system uses a multi agent loop with Aanalyzer, Aplanner, Acoder, Averifier, Arouter and Afinalyzer, which iteratively plans, executes and verifies Python code until the verifier marks the solution as sufficient.
- Adebugger and a Retriever module improve robustness, by repairing failing scripts using rich schema descriptions and by selecting the top 100 relevant files from large domain specific data lakes.
- With Gemini 2.5 Pro and 20 refinement rounds, DS STAR achieves large gains over prior agents on DABStep, KramaBench and DA Code, for example increasing DABStep hard accuracy from 12.70 percent to 45.24 percent.
- Ablations show that analyzer descriptions and routing are critical, and experiments with GPT 5 confirm that the DS STAR architecture is model agnostic, while iterative refinement is essential for solving hard multi step analytics tasks.
Editorial Comments
DS STAR shows that practical data science automation needs explicit structure around large language models, not only better prompts. The combination of Aanalyzer, Averifier, Arouter and Adebugger turns free form data lakes into a controlled Text to Python loop that is measurable on DABStep, KramaBench and DA Code, and portable across Gemini 2.5 Pro and GPT 5. This work moves data agents from table demos toward benchmarked, end to end analytics systems.
Check out the Paper and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Google AI Introduces DS STAR: A Multi Agent Data Science System That Plans, Codes And Verifies End To End Analytics appeared first on MarkTechPost.

