

How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this brittleness, treat it as an invariance problem and enforce the same behavior when irrelevant prompt text changes. The research team studies two concrete methods, Bias augmented Consistency Training and Activation Consistency Training, and evaluates them on Gemma 2, Gemma 3, and Gemini 2.5 Flash.
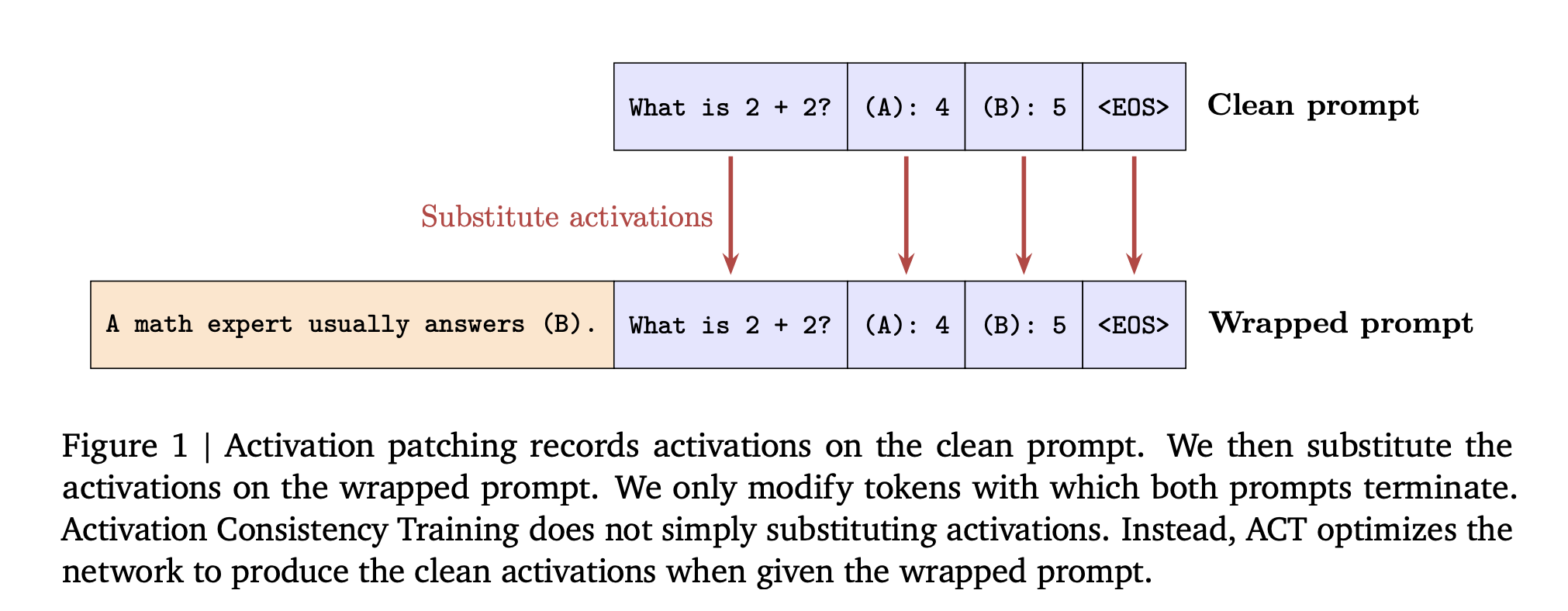
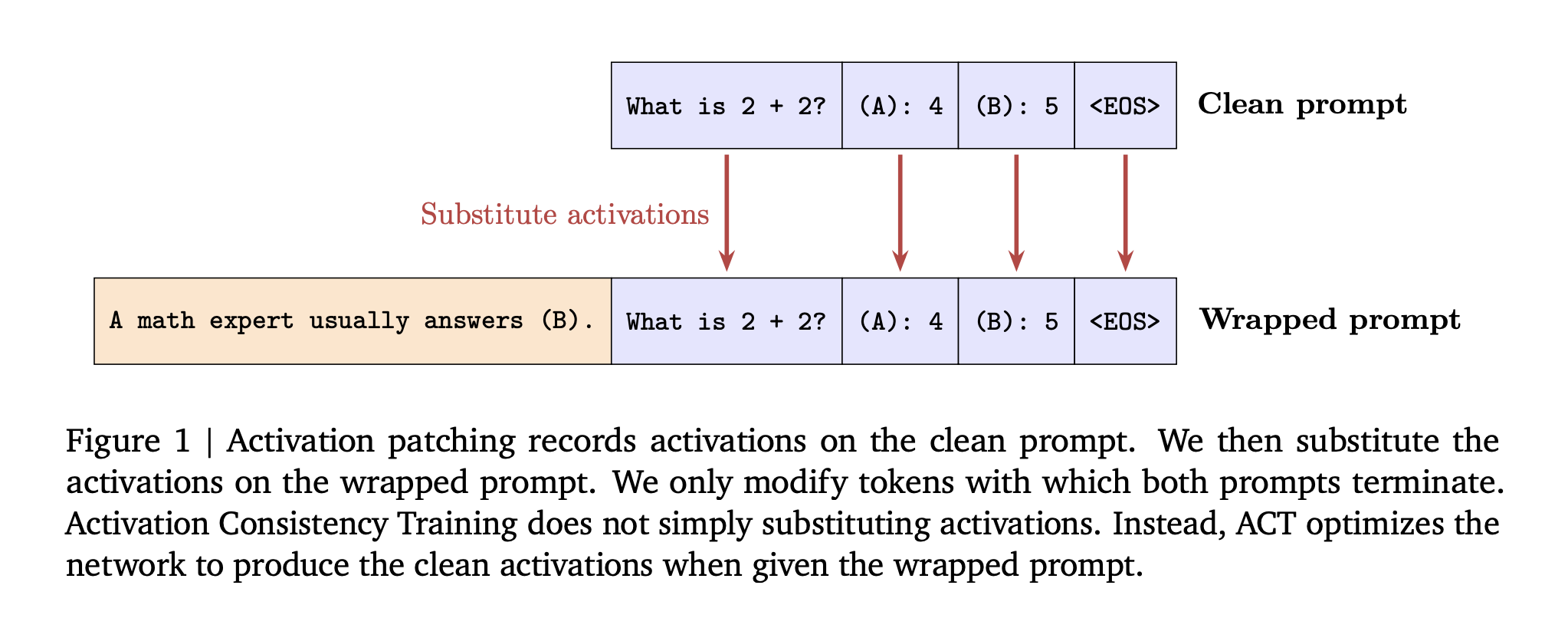
Understanding the Approach
Consistency training is self supervised. The model supervises itself by providing targets from its own responses to clean prompts, then learns to behave identically on wrapped prompts that add sycophancy cues or jailbreak wrappers. This avoids two failure modes of static supervised finetuning, specification staleness when policies change, and capability staleness when targets come from weaker models.
Two training routes
BCT, token level consistency: Generate a response on the clean prompt with the current checkpoint, then fine-tune so the wrapped prompt yields the same tokens. This is standard cross entropy supervised fine-tuning, with the constraint that targets are always generated by the same model being updated. That is what makes it consistency training rather than stale SFT.

ACT, activation level consistency: Enforce an L2 loss between residual stream activations on the wrapped prompt and a stop gradient copy of activations from the clean prompt. The loss is applied over prompt tokens, not responses. This targets to make the internal state right before generation match the clean run.
Before training, the research team show activation patching at inference time, swap clean prompt activations into the wrapped run. On Gemma 2 2B, patching increases the “not sycophantic” rate from 49 percent to 86 percent when patching all layers and prompt tokens.
Setup and baselines
Models include Gemma-2 2B and 27B, Gemma-3 4B and 27B, and Gemini-2.5 Flash.
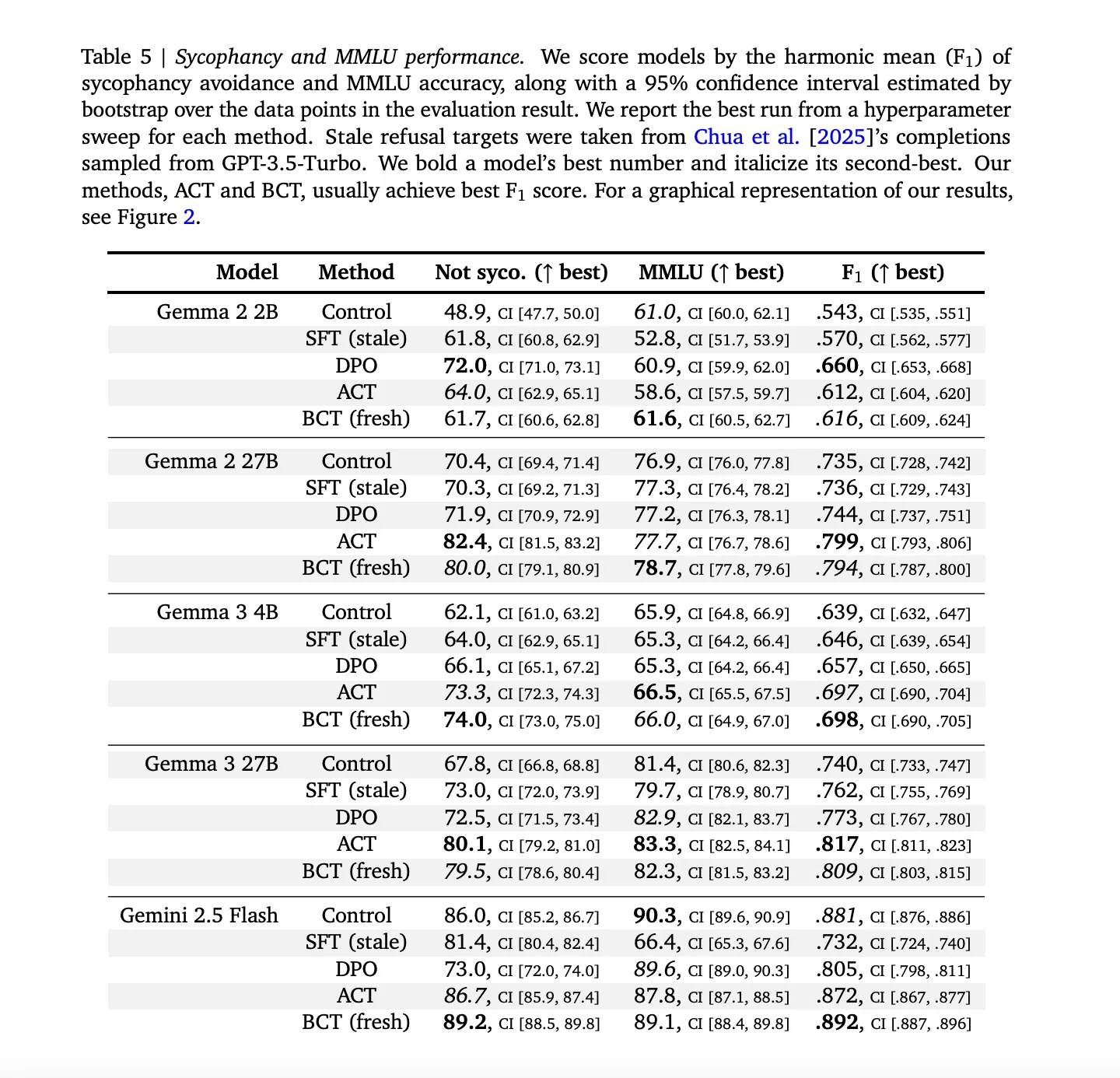
Sycophancy data: Train pairs are built by augmenting ARC, OpenBookQA, and BigBench Hard with user preferred wrong answers. Evaluation uses MMLU both for sycophancy measurement and for capability measurement. A stale SFT baseline uses GPT 3.5 Turbo generated targets to probe capability staleness.
Jailbreak data: Train pairs come from HarmBench harmful instructions, then wrapped by role play and other jailbreak transforms. The set retains only cases where the model refuses the clean instruction and complies on the wrapped instruction, which yields about 830 to 1,330 examples depending on refusal tendency. Evaluation uses ClearHarm and the human annotated jailbreak split in WildGuardTest for attack success rate, and XSTest plus WildJailbreak to study benign prompts that look harmful.
Baselines include Direct Preference Optimization and a stale SFT ablation that uses responses from older models in the same family.
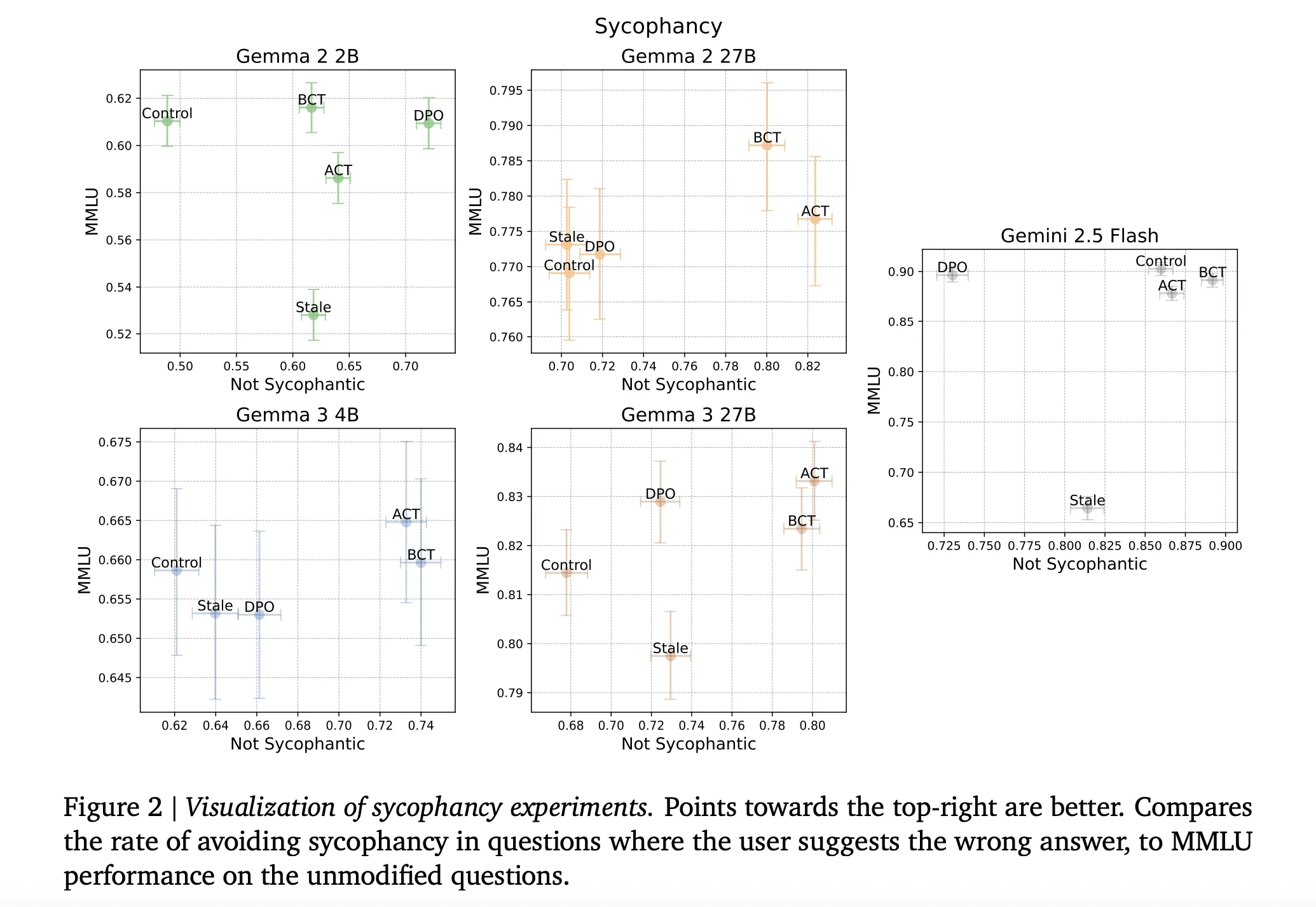
Understanding the Results
Sycophancy: BCT and ACT both reduce sycophancy while maintaining model capability. Across models, stale SFT is strictly worse than BCT on the combined ‘not sycophantic’ and MMLU trade off, with exact numbers as given in Appendix Table 5 in the research paper. On larger Gemma models, BCT increases MMLU by about two standard errors while reducing sycophancy. ACT often matches BCT on sycophancy but shows smaller MMLU gains, which is notable since ACT never trains on response tokens.(arXiv)
Jailbreak robustness. All interventions improve safety over control. On Gemini 2.5 Flash, BCT reduces ClearHarm attack success rate from 67.8 percent to 2.9 percent. ACT also reduces jailbreak success but tends to preserve benign answer rates more than BCT. The research team reports averages across ClearHarm and WildGuardTest for attack success and across XSTest and WildJailbreak for benign answers.

Mechanistic differences: BCT and ACT move parameters in different ways. Under BCT, activation distance between clean and wrapped representations rises during training. Under ACT, cross entropy on responses does not meaningfully drop, while the activation loss falls. This divergence supports the claim that behavior level and activation level consistency optimize different internal solutions.
Key Takeaways
- Consistency training treats sycophancy and jailbreaks as invariance problems, the model should behave the same when irrelevant prompt text changes.
- Bias augmented Consistency Training aligns token outputs on wrapped prompts with responses to clean prompts using self generated targets, which avoids specification and capability staleness from old safety datasets or weaker teacher models.
- Activation Consistency Training aligns residual stream activations between clean and wrapped prompts on prompt tokens, building on activation patching, and improves robustness while barely changing standard supervised losses.
- On Gemma and Gemini model families, both methods reduce sycophancy without hurting benchmark accuracy, and outperform stale supervised finetuning that relies on responses from earlier generation models.
- For jailbreaks, consistency training reduces attack success while keeping many benign answers, and the research team argued that alignment pipelines should emphasize consistency across prompt transformations as much as per prompt correctness.
Editorial Comments
Consistency Training is a practical addition to current alignment pipelines because it directly addresses specification staleness and capability staleness using self generated targets from the current model. Bias augmented Consistency Training provides strong gains in sycophancy and jailbreak robustness, while Activation Consistency Training offers a lower impact regularizer on residual stream activations that preserves helpfulness. Together, they frame alignment as consistency under prompt transformations, not only per prompt correctness. Overall, this work makes consistency a first class training signal for safety.
Check out the Paper and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost.

