
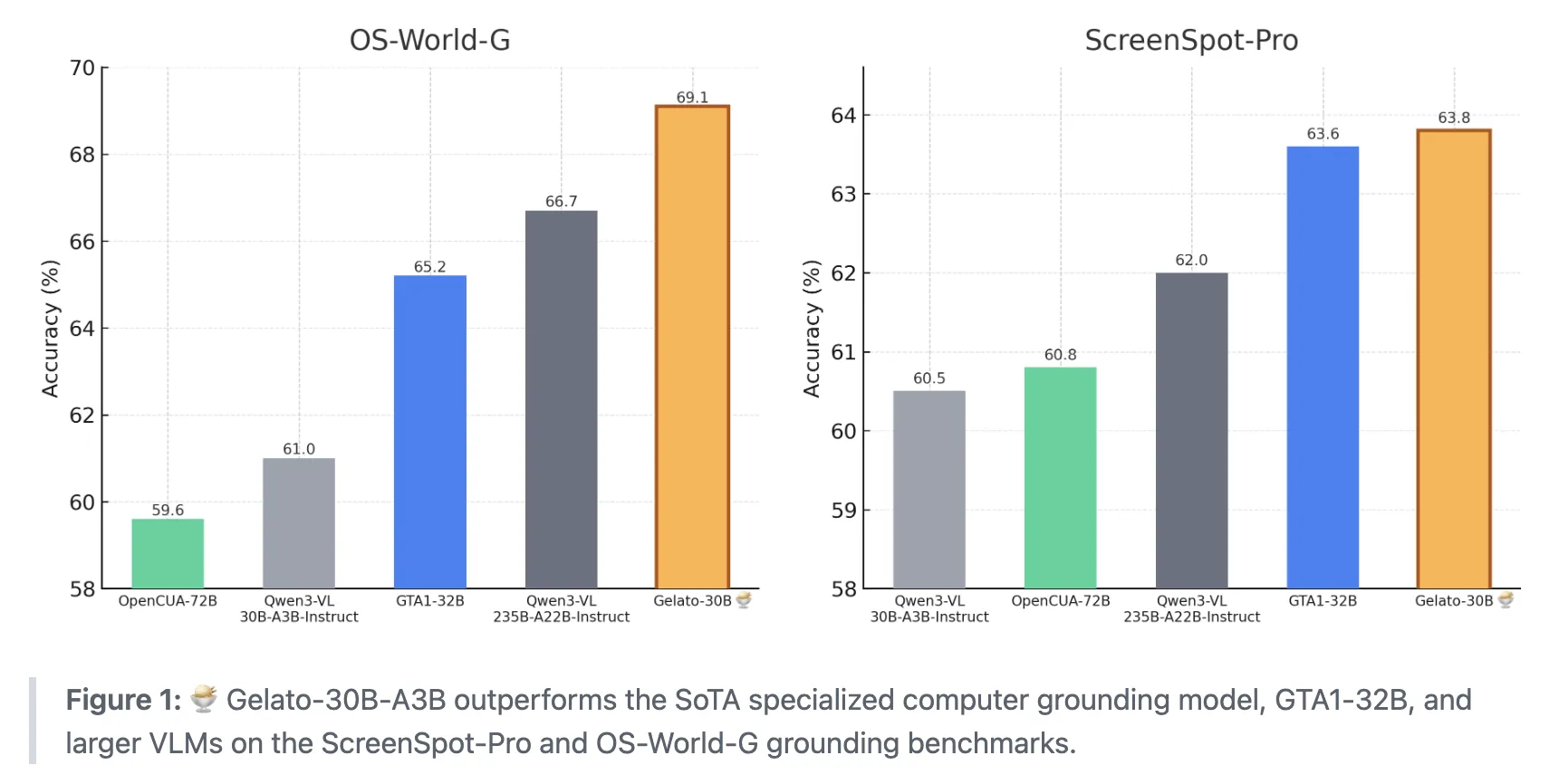
How do we teach AI agents to reliably find and click the exact on screen element we mean when we give them a simple instruction? A team of researchers from ML Foundations has introduced Gelato-30B-A3B, a state of the art grounding model for graphical user interfaces that is designed to plug into computer use agents and convert natural language instructions into reliable click locations. The model is trained on the Click 100k dataset and reaches 63.88% accuracy on ScreenSpot Pro and 69.15% on OS-World-G, with 74.65% on OS-World-G Refined. It surpasses GTA1-32B and larger vision language models such as Qwen3-VL-235B-A22B-Instruct.
What Gelato 30B A3B Does in An Agent Stack?
Gelato-30B-A3B is a 31B parameter model that fine tunes Qwen3-VL-30B-A3B Instruct with a mixture of experts architecture. It takes a screenshot and a textual instruction as input and produces a single click coordinate as output.
The model is positioned as a modular grounding component. A planner model, for example GPT 5 in the Gelato experiments, decides the next high level action and calls Gelato to resolve that step into a concrete click on the screen. This separation between planning and grounding is important when an agent must operate across many operating systems and applications with different layouts.
Click 100k, A Targeted Dataset For GUI Grounding
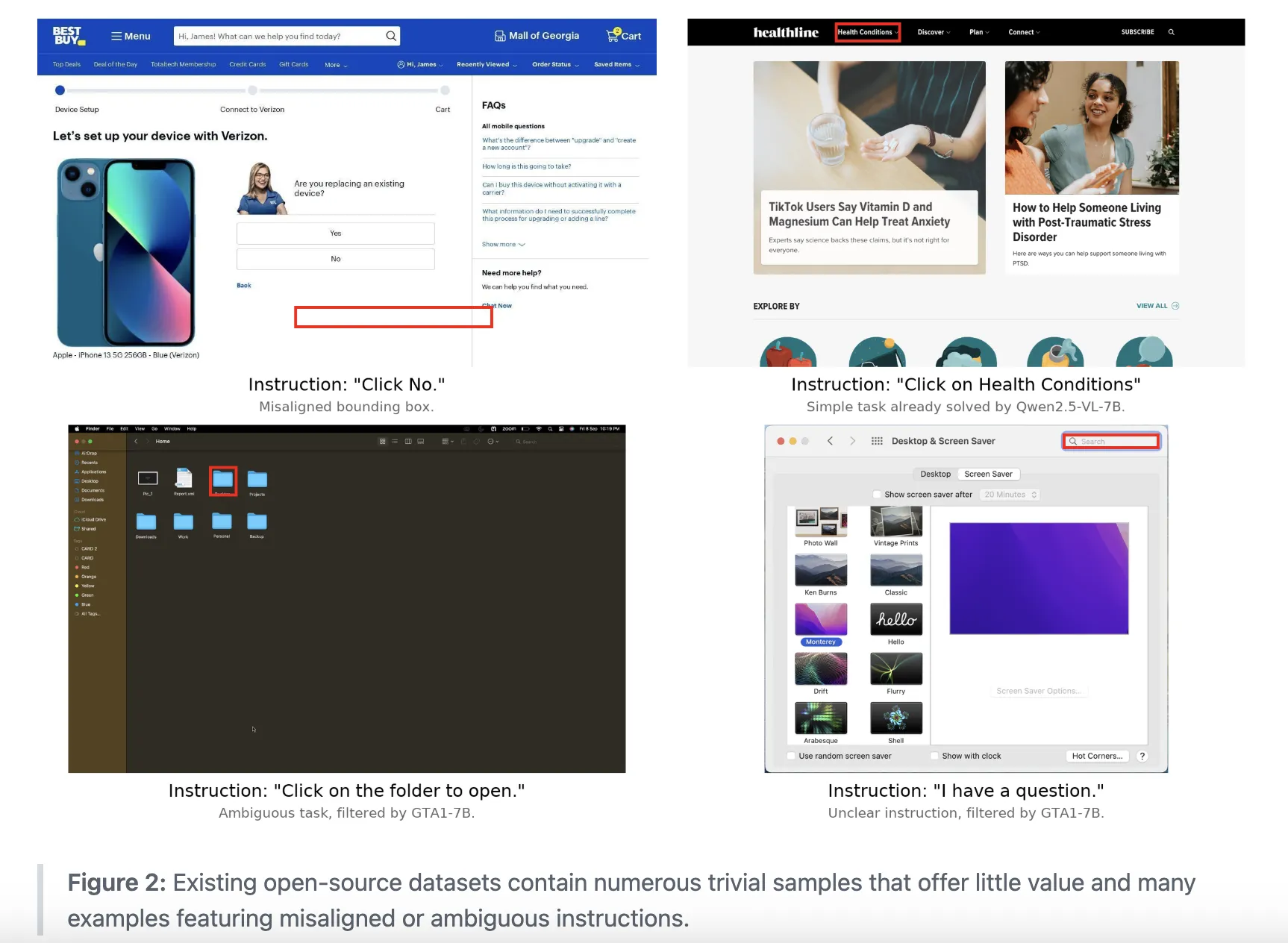
Click 100k is the dataset that underlies Gelato. It pairs computer screen images with natural language instructions, bounding boxes for the target element, image dimensions, and normalized bounding boxes. Each sample is set up as a low level command, for example ‘tap on the element between Background and Notifications options’ with a precise region.
The dataset is built by filtering and unifying multiple public sources. The list includes ShowUI, AutoGUI, PC Agent E, WaveUI, OS Atlas, UGround, PixMo Points, SeeClick, UI VISION, a JEDI subset that focuses on spreadsheet and text cell manipulation, and videos from 85 professional application tutorials annotated with Claude-4-Sonnet. Each source contributes at most 50k samples, and all sources are mapped into a shared schema with images, instructions, bounding boxes, and normalized coordinates.
The research team then runs an aggressive filtering pipeline. OmniParser discards clicks that do not land on detected interface elements. Qwen2.5-7B-VL and SE-GUI-3B remove trivial examples, such as easy hyperlink clicks. GTA1-7B-2507 and UI-Venus-7B remove samples where the instruction and click region do not match. A Qwen2.5-7B-VL baseline trained on a balanced 10k subset shows that this combination gives a +9 pp accuracy gain on ScreenSpot Pro compared with training on unfiltered data.
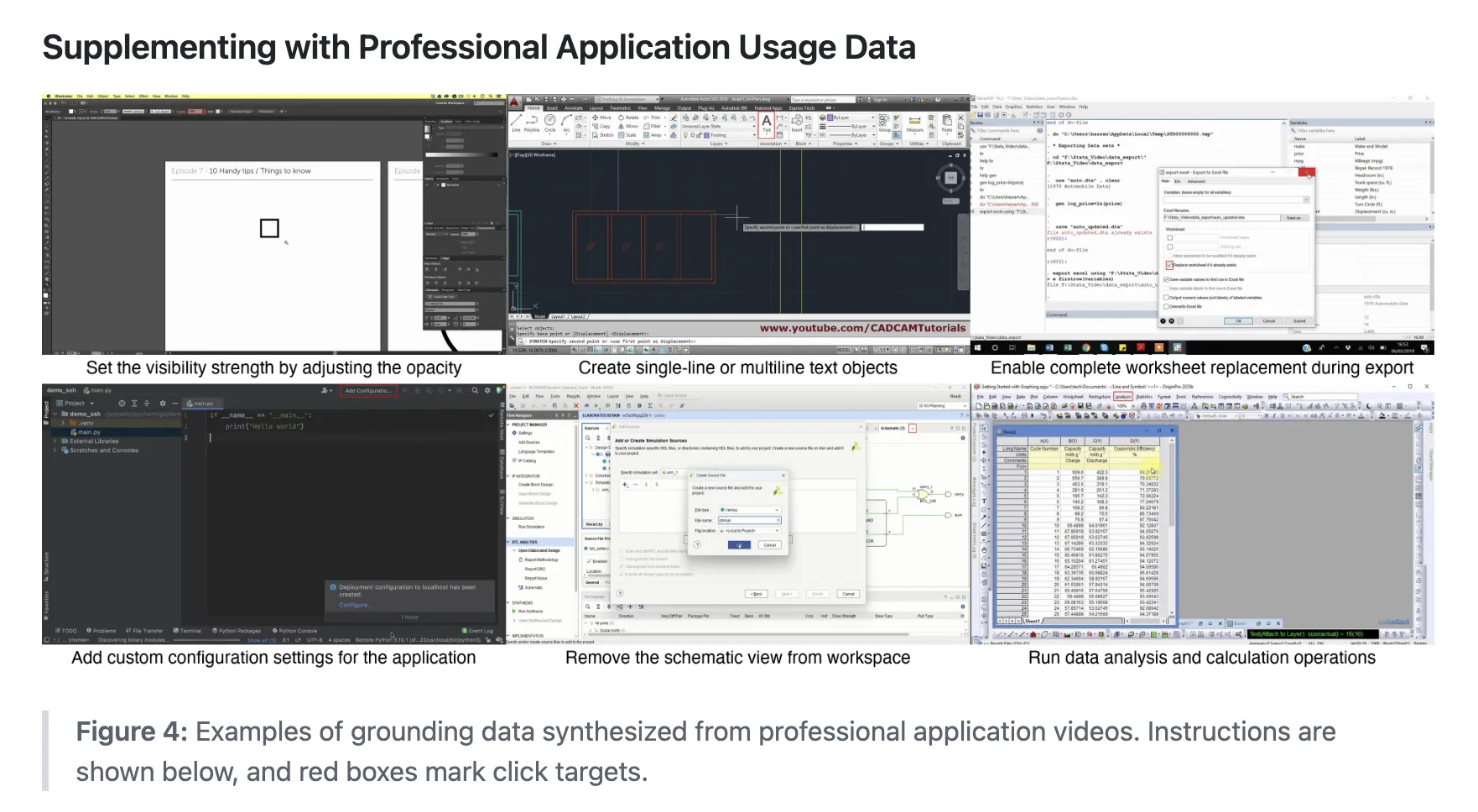
Professional application coverage is a specific focus. Click 100k adds data from UI VISION and the JEDI subset, and then augments this with 80+ tutorial videos for real desktop tools. Claude 4 Sonnet generates bounding boxes and low level instructions for these videos, followed by manual inspection and corrections.
GRPO Training On Top Of Qwen3 VL
On the training side, Gelato 30B A3B uses GRPO, a reinforcement learning algorithm that derives from work on DeepSeekMath and similar systems. The research team follow the DAPO setup. They remove the KL divergence term from the objective, set the clip higher threshold to 0.28, and skip rollouts with zero advantage. Rewards are sparse and are only given when the predicted click falls inside the target bounding box, similar to the GTA1 recipe.
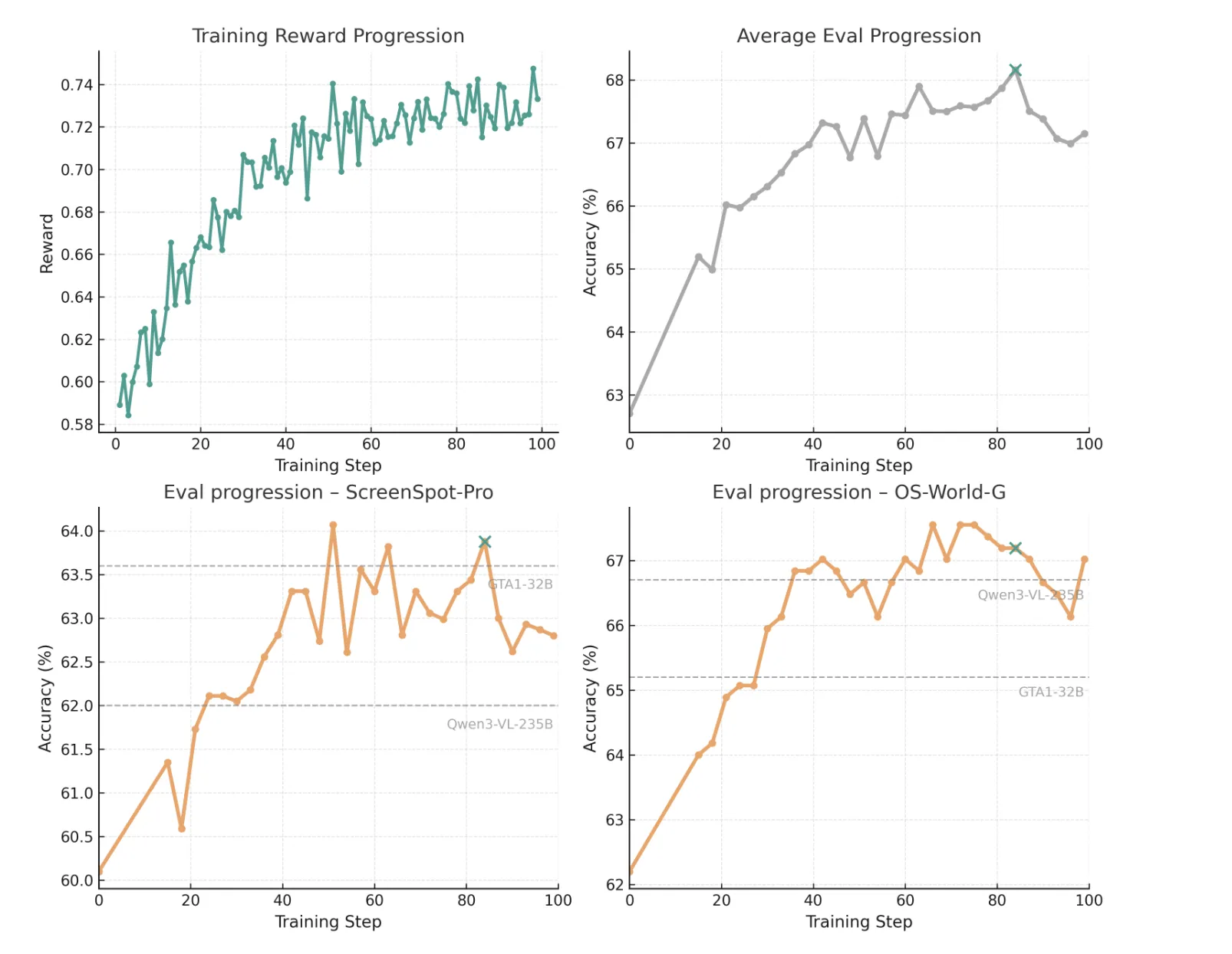
They initialize from Qwen3 VL 30B A3B Instruct and run 100 RL steps on 32 A100 GPUs with 40 GB memory. The best checkpoint appears at step 84 (marked as green cross in the above image), chosen by the mean performance across ScreenSpot Pro, OS World G, and OS World G Refined. At this point the model reaches 63.88% on ScreenSpot-Pro and 67.19% and 73.40% on OS World G and OS World G Refined. A simple refusal prompting strategy, which appends an instruction to answer with refusal when the element cannot be found, raises the OS-World-G scores to 69.15% and 74.65%.
End To End Agent Results On OS World
To test Gelato beyond static grounding benchmarks, the research team plugs it into the GTA1.5 agent framework and runs full computer use agents on the OS World environment. In this setup GPT 5 acts as the planner. Gelato 30B A3B provides grounding, the agent has at most 50 steps, and it waits 3 seconds between actions.
The research reports three runs per model on a fixed OS World snapshot. Gelato-30B-A3B reaches 58.71% automated success rate with a small standard deviation, compared with 56.97% for GTA1 32B in the same harness. Because the automatic OS World evaluation misses some valid solutions, they also run human evaluation on 20 problematic tasks. Under human scoring, Gelato reaches 61.85% success, while GTA1-32B reaches 59.47%.
Key Takeaways
- Gelato-30B-A3B is a Qwen3-VL-30B-A3B Instruct based mixture of experts model that performs state of the art GUI grounding on ScreenSpot Pro and OS World G benchmarks, surpassing GTA1-32B and larger VLMs such as Qwen3-VL-235B-A22B-Instruct.
- The model is trained on Click 100k, a curated grounding dataset that merges and filters multiple public GUI datasets and professional application traces, pairing real screens with low level natural language commands and precise click coordinates.
- Gelato-30B-A3B uses a GRPO reinforcement learning recipe on top of Qwen3-VL, with sparse rewards that only trigger when the predicted click lies inside the ground truth bounding box, which significantly boosts grounding accuracy over supervised baselines.
- When integrated into an agent framework with GPT-5 acting as the planner, Gelato-30B-A3B improves success rates on OS World computer use tasks compared with GTA1-32B, demonstrating that better grounding directly translates into stronger end to end agent performance.
Editorial Comments
Gelato-30B-A3B is an important step for grounded computer use because it shows that a Qwen3-VL based MoE model, trained on a carefully filtered Click 100k dataset, can beat both GTA1-32B and much larger VLMs like Qwen3-VL-235B-A22B Instruct on ScreenSpot Pro and OS-World-G while staying accessible through Hugging Face. Overall, Gelato-30B-A3B establishes a clear new baseline for open computer grounding models.
Check out the Repo and Model Weights. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Gelato-30B-A3B: A State-of-the-Art Grounding Model for GUI Computer-Use Tasks, Surpassing Computer Grounding Models like GTA1-32B appeared first on MarkTechPost.


