Traveling is enjoyable, but travel planning can be complex to navigate and a hassle. Travelers must book accommodations, plan activities, and arrange local transportation. All these decisions can feel overwhelming. Although travel professionals have long helped manage these complexities, recent breakthroughs in generative AI have made something entirely new possible—intelligent assistants that can understand natural conversation, access real-time data, and directly interface with booking systems and travel tools. Agentic workflows, which use large language models (LLMs) with access to external tools, are particularly promising for simplifying dynamic, multi-step processes like travel planning.
In this post, we explore how to build a travel planning solution using AI agents. The agent uses Amazon Nova, which offers an optimal balance of performance and cost compared to other commercial LLMs. By combining accurate but cost-efficient Amazon Nova models with LangGraph orchestration capabilities, we create a practical travel assistant that can handle complex planning tasks while keeping operational costs manageable for production deployments.
Solution overview
Our solution is built on a serverless AWS Lambda architecture using Docker containers and implements a comprehensive three-layer approach: frontend interaction, core processing, and integration services. In the core processing layer, we use LangGraph, a stateful orchestration framework, to create a sophisticated yet flexible agent-based system that manages the complex interactions required for travel planning.
The core of our system is a graph architecture where components (nodes) handle distinct aspects of travel planning, with the router node orchestrating the flow of information between them. We use Amazon Nova, a new generation of state-of-the-art foundation models (FMs) available exclusively on Amazon Bedrock that delivers frontier intelligence with industry-leading price-performance. The router node uses an LLM to analyze each user query and, with access to the description of our 14 action nodes, decides which ones need to be executed. The action nodes, each with their own LLM chain, powered by either Amazon Nova Pro or Amazon Nova Lite models, manage various functions, including web research, personalized recommendations, weather lookups, product searches, and shopping cart management.
We use Amazon Nova Lite for the router and simpler action nodes. It can handle query analysis and basic content generation with its lightning-fast processing while maintaining strong accuracy at a low cost. Five complex nodes use Amazon Nova Pro for tasks requiring advanced instruction following and multi-step operations, such as detailed travel planning and recommendations. Both models support a 300,000-token context window and can process text, image, and video inputs. The models support text processing across more than 200 languages, helping our travel assistant serve a global audience.The integration layer unifies multiple data sources and services through an interface:
- Amazon Product Advertising API for travel-related product recommendations
- Google Custom Search API for real-time travel information
- OpenWeather API for accurate weather forecasts
- Amazon Bedrock Knowledge Bases for travel destination insights
- Amazon DynamoDB for persistent storage of user profiles and chat history
These integrations serve as examples, and the architecture is designed to be extensible, so organizations can quickly incorporate their own APIs and data sources based on specific requirements.
The agent keeps track of the conversation state using AgentState (TypedDict), a special Python dictionary that helps prevent data errors by enforcing specific data types. It stores the information we need to know about each user’s session: their conversation history, profile information, processing status, and final outputs. This makes sure the different action nodes can access and update information reliably.
The following diagram illustrates the solution architecture.
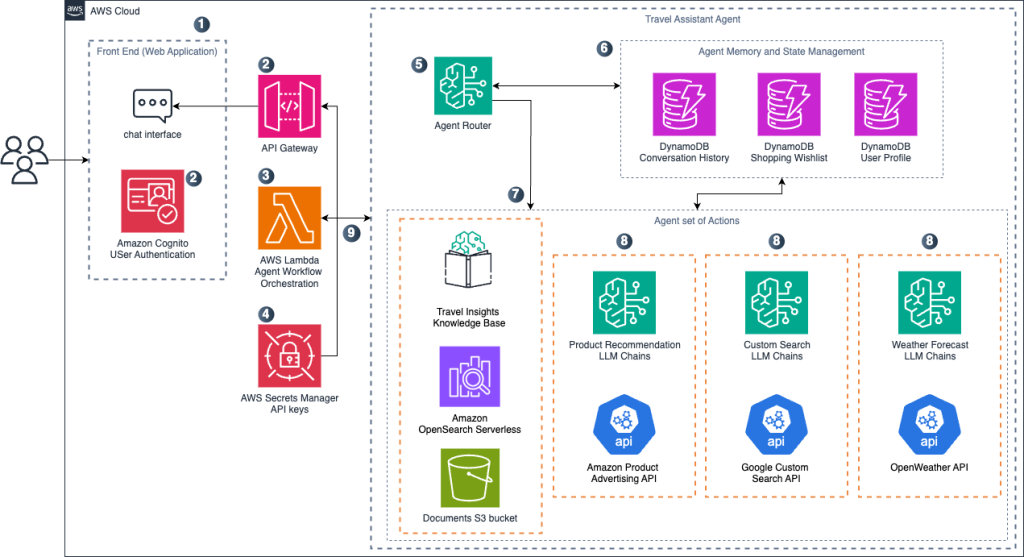
The travel assistant processes user interactions from end to end:
- Users interact with a React.js web application through a chat interface.
- Their requests are authenticated using Amazon Cognito and routed through Amazon API Gateway.
- Authenticated requests are sent to our backend Lambda functions, which host the core agent workflow.
- API credentials are securely stored using AWS Secrets Manager, following best practices to make sure these sensitive keys are never exposed in code or configuration files, with appropriate access controls and rotation policies implemented.
- The Travel Assistant Agent itself consists of several interconnected components. At the center, the agent router analyzes incoming queries and orchestrates the workflow.
- The agent maintains state through three DynamoDB tables that store conversation history, shopping wishlists, and user profiles, making sure context is preserved across interactions.
- For travel-specific knowledge, the system uses a combination of Amazon Bedrock Knowledge Bases, Amazon OpenSearch Serverless, and a document store in Amazon Simple Storage Service (Amazon S3). These components work together to provide accurate, relevant travel information when needed.
- The agent’s action nodes handle specialized tasks by combining LLM chains with external APIs. When users need product recommendations, the system connects to the Amazon Product Advertising API. For general travel information, it uses the Google Custom Search API, and for weather-related queries, it consults the OpenWeather API. API credentials are securely managed through Secrets Manager.
- The system formulates comprehensive responses based on collected information, and the final responses are returned to the user through the chat interface.
This architecture supports both simple queries that can be handled by a single node and complex multi-step interactions that require coordination across multiple components. The system can scale horizontally, and new capabilities can be added by introducing additional action nodes and API integrations.
You can deploy this solution using the AWS Cloud Development Kit (AWS CDK), which generates an AWS CloudFormation template that handles the necessary resources, including Lambda functions, DynamoDB tables, and API configurations. The deployment creates the required AWS resources and outputs the API endpoint URL for your frontend application.
Prerequisites
For this walkthrough, you must have the following prerequisites:
- An active AWS account and familiarity with FMs, Amazon Bedrock, and Amazon OpenSearch Service
- Access to the Amazon Nova FMs on Amazon Bedrock
- Node.js v16.x or later
- Python 3.9 or later
- Access to the Product Advertising API (PAAPI)
Clone the repository
Start by cloning the GitHub repository containing the solution files:
Obtain API keys
The solution requires API keys from three services to enable its core functionalities:
- OpenWeather API – Create a Free Access account at OpenWeather to obtain your API key. The free tier (60 calls per minute) is sufficient for testing and development.
- Google Custom Search API – Set up the search functionality through Google Cloud Console. Create or select a project and enable the Custom Search API. Then, generate an API key from the credentials section. Create a search engine at Programmable Search and note your Search Engine ID. The free tier includes 100 queries per day.
- (Optional) Amazon Product Advertising API (PAAPI) – If you want to enable product recommendations, access the PAAPI Documentation Portal to generate your API keys. You will receive both a public key and a secret key. You must have an Amazon Associates account to access these credentials. If you’re new to the Amazon Associates Program, complete the application process first. Skip this step if you don’t want to use PAAPI features.
Add API keys to Secrets Manager
Before deploying the solution, you must securely store your API keys in Secrets Manager. The following table lists the secrets to create and their JSON structure. For instructions to create a secret, refer to Create an AWS Secrets Manager secret.
| Secret Name | JSON Structure |
openweather_maps_keys |
{" openweather_key": "YOUR_API_KEY"} |
google_search_keys |
{"cse_id": "YOUR_SEARCH_ENGINE_ID", "google_api_key": "YOUR_API_KEY"} |
paapi_keys |
{"paapi_public": "YOUR_PUBLIC_KEY", "paapi_secret": "YOUR_SECRET_KEY"} |
Configure environment variables
Create a .env file in the project root with your configuration:
Deploy the stack
If this is your first time using the AWS CDK in your AWS account and AWS Region, bootstrap your environment:
Deploy the solution using the provided script, which creates the required AWS resources, including Lambda functions, DynamoDB tables, and API configurations:
Access your application
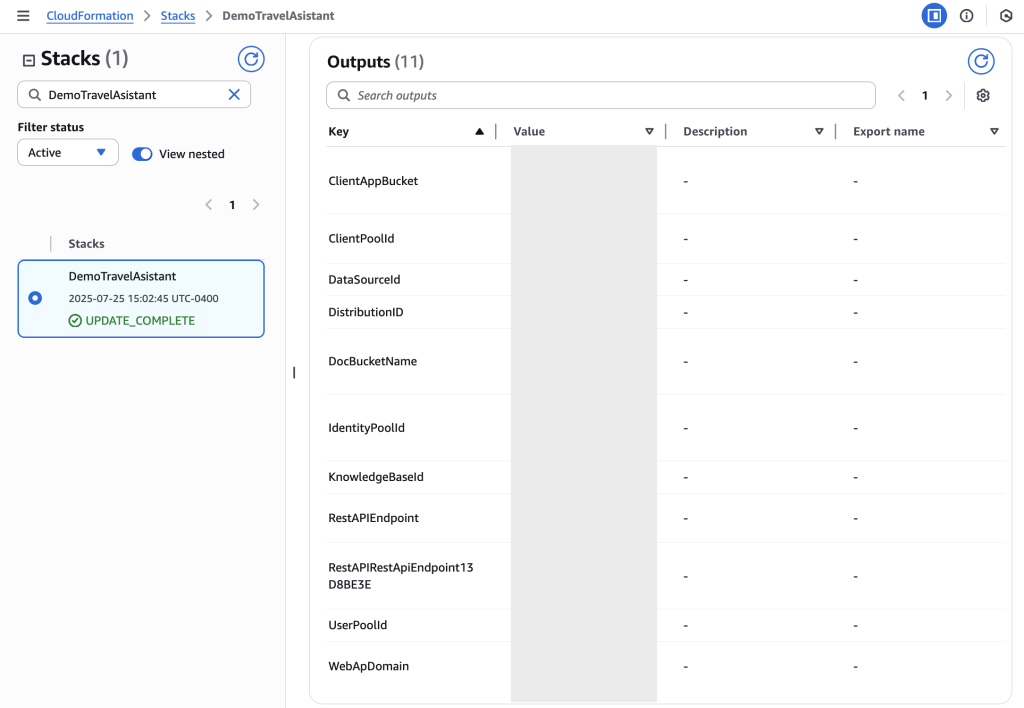
When the deployment is complete, open the AWS CloudFormation console and open your stack. On the Outputs tab, note the following values:
- WebAppDomain – Your application’s URL
- UserPoolId – Required for user management
- UserPoolClientId – Used for authentication
Create an Amazon Cognito user
Complete the following steps to create an Amazon Cognito user:
- On the Amazon Cognito console, choose User pools in the navigation pane.
- Choose your user pool.
- Choose Users in the navigation pane, then choose Create user.
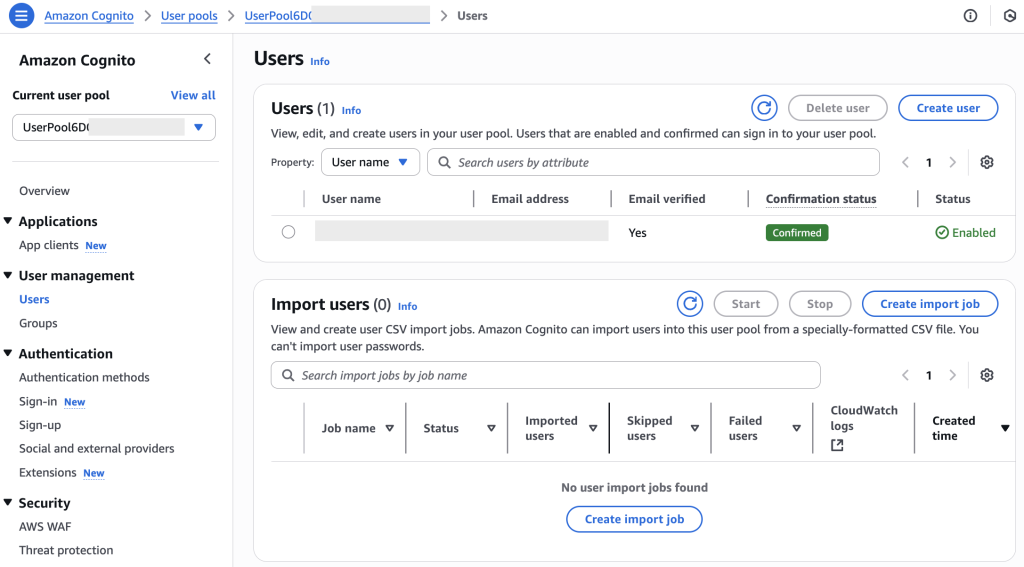
- For Email address, enter an email address, and select Mark email address as verified.
- For Password, enter a temporary password.
- Choose Create user.
You can use these credentials to access your application at the WebAppDomain URL.
Test the solution
To test the agent’s capabilities, we created a business traveler persona and simulated a typical travel planning conversation flow. We focused on routing, function calling accuracy, response quality, and latency metrics. The agent’s routing system directs the user questions to the appropriate specialized node (for example, searching for accommodations, checking weather conditions, or suggesting travel products). Throughout the conversation, the agent maintains the context of previously discussed details, so it can build upon earlier responses while providing relevant new information. For example, after discussing travel destination, the agent can naturally incorporate this into subsequent weather and packing list recommendations.
The following screenshots demonstrate the end-user experience, while the underlying API interactions are handled seamlessly on the backend. The complete implementation details, including Lambda function code and API integration patterns, are available in our GitHub repository.
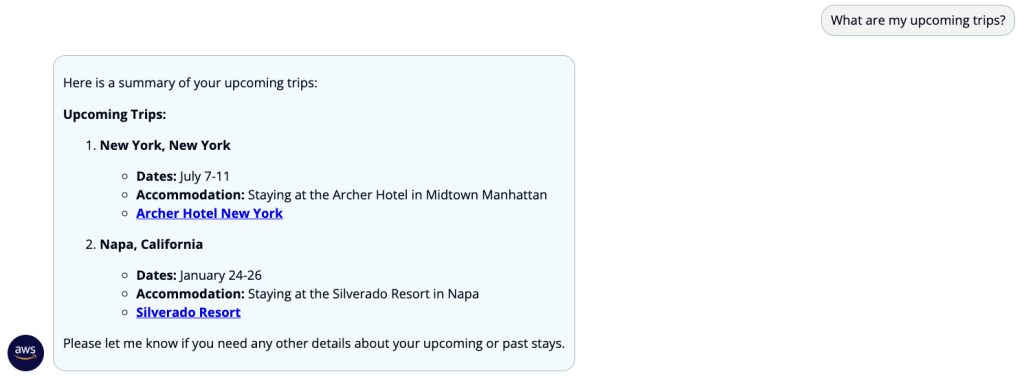
The solution demonstrates personalization capabilities using sample user profiles stored in DynamoDB, containing upcoming trips and travel preferences. In production deployments, these profiles can be integrated with existing customer databases and reservation systems to provide a personalized assistance.

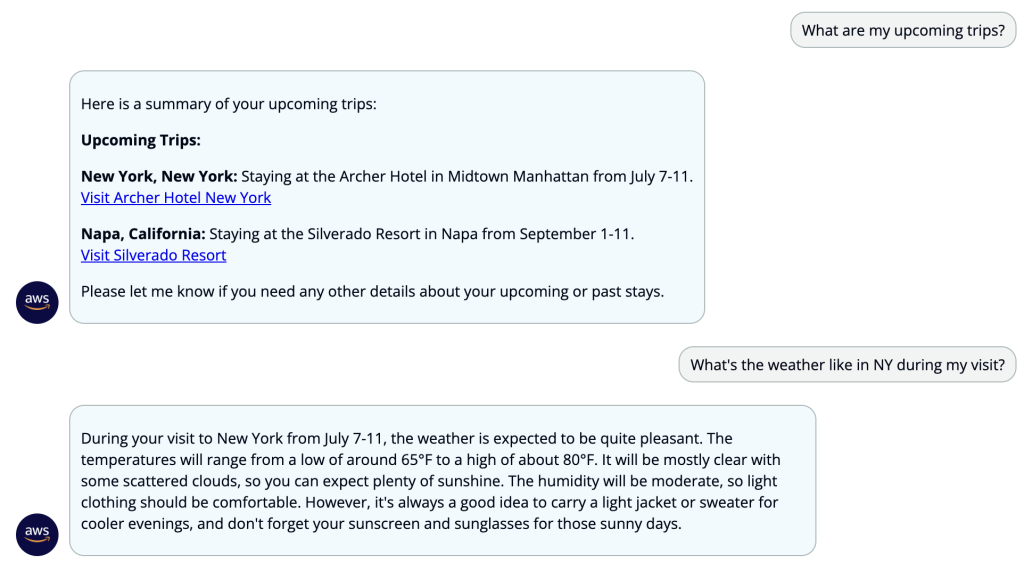
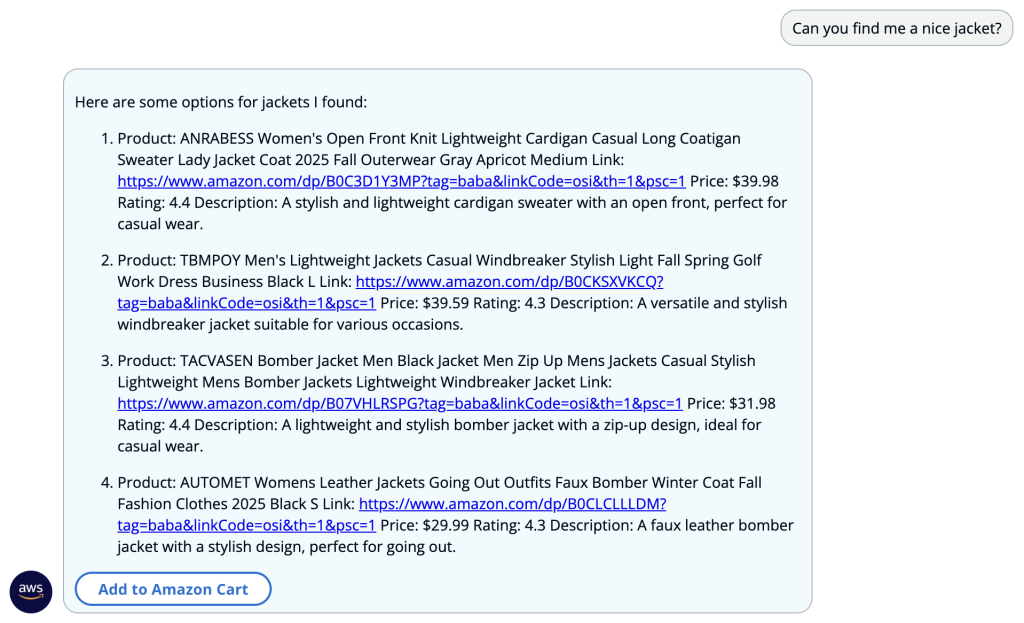
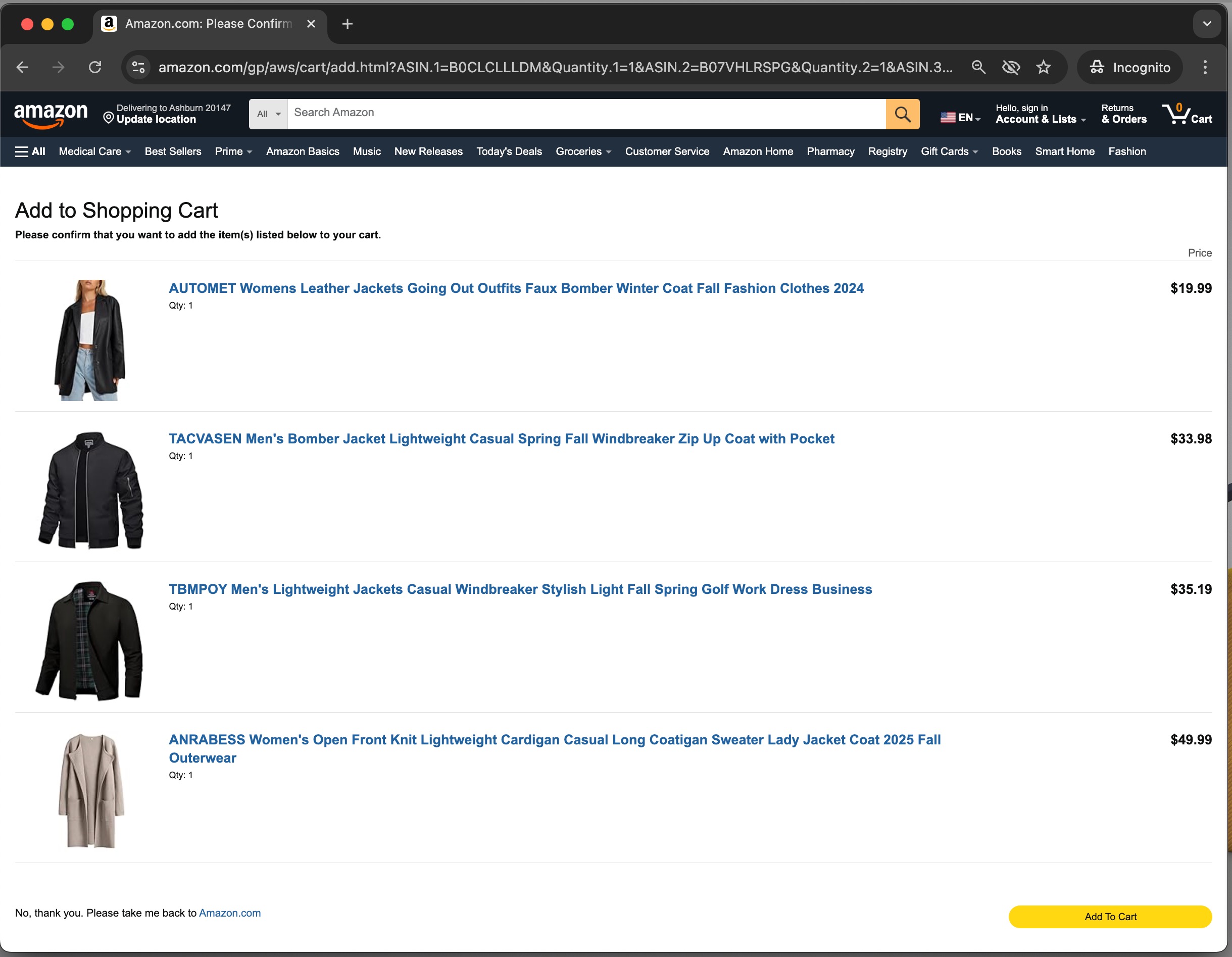
The product recommendations shown are live links to actual items available on Amazon.com, so the user can explore or purchase these products directly. The user can choose a link to check out the product, or choose Add to Amazon Cart to see the items in their shopping cart.
Clean up
After you are done experimenting with the travel assistant, you can locate the CloudFormation stack on the AWS CloudFormation console and delete it. This will delete the resources you created.
Conclusion
Our travel planning assistant agent demonstrates a practical application built by Amazon Nova and LangGraph for solving real-world business challenges. The system streamlines complex travel planning while naturally integrating product recommendations through specialized processing nodes and real-time data integration. Amazon Nova Lite models showed reasonable performance at task orchestration, and Amazon Nova Pro performed well for more complex function calling operations. Looking ahead, this framework could be implemented with more dynamic orchestration systems such as ReAct. To build your own implementation, explore our code samples in the GitHub repository.
For those looking to deepen their understanding of LLM-powered agents, AWS provides extensive resources on building intelligent systems. The Amazon Bedrock Agents documentation offers insights into automating multistep tasks with FMs, and the AWS Bedrock Agent Samples GitHub repo provides guidance for implementing multiple agent applications using Amazon Bedrock.
About the authors
 Isaac Privitera is a Principal Data Scientist with the AWS Generative AI Innovation Center, where he develops bespoke generative AI-based solutions to address customers’ business problems. His primary focus lies in building responsible AI systems, using techniques such as RAG, multi-agent systems, and model fine-tuning. When not immersed in the world of AI, Isaac can be found on the golf course, enjoying a football game, or hiking trails with his loyal canine companion, Barry.
Isaac Privitera is a Principal Data Scientist with the AWS Generative AI Innovation Center, where he develops bespoke generative AI-based solutions to address customers’ business problems. His primary focus lies in building responsible AI systems, using techniques such as RAG, multi-agent systems, and model fine-tuning. When not immersed in the world of AI, Isaac can be found on the golf course, enjoying a football game, or hiking trails with his loyal canine companion, Barry.
 Ryan Razkenari is a Deep Learning Architect at the AWS Generative AI Innovation Center, where he uses his expertise to create cutting-edge AI solutions. With a strong background in AI and analytics, he is passionate about building innovative technologies that address real-world challenges for AWS customers.
Ryan Razkenari is a Deep Learning Architect at the AWS Generative AI Innovation Center, where he uses his expertise to create cutting-edge AI solutions. With a strong background in AI and analytics, he is passionate about building innovative technologies that address real-world challenges for AWS customers.
 Sungmin Hong is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he helps expedite a variety of use cases for AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds a PhD in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading, and cooking.
Sungmin Hong is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he helps expedite a variety of use cases for AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds a PhD in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading, and cooking.