

Large language models (LLMs) perform well on general tasks but struggle with specialized work that requires understanding proprietary data, internal processes, and industry-specific terminology. Supervised fine-tuning (SFT) adapts LLMs to these organizational contexts. SFT can be implemented through two distinct methodologies: Parameter-Efficient Fine-Tuning (PEFT), which updates only a subset of model parameters, offering faster training and lower computational costs while maintaining reasonable performance improvements; Full-rank SFT, which updates all model parameters rather than a subset and incorporates more domain knowledge than PEFT.
Full-rank SFT often faces a challenge: catastrophic forgetting. As models learn domain-specific patterns, they lose general capabilities including instruction-following, reasoning, and broad knowledge. Organizations must choose between domain expertise and general intelligence, which limits model utility across enterprise use cases.
Amazon Nova Forge addresses the problem. Nova Forge is a new service that you can use to build your own frontier models using Nova. Nova Forge customers can start their development from early model checkpoints, blend proprietary data with Amazon Nova-curated training data, and host their custom models securely on AWS.
In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models. Working with over 16,000 customer comment samples across a complex four-level label hierarchy containing 1,420 leaf categories, we demonstrate how Nova Forge’s data mixing approach provides two advantages:
- In-domain task performance gains: achieving 17% F1 score improvements
- Preserved general capabilities: maintaining near-baseline MMLU (Massive Multitask Language Understanding) scores and instruction-following abilities post-finetuning
The challenge: real-world customer feedback classification
Consider a typical scenario at a large ecommerce company. The customer experience team receives thousands of customer comments daily with detailed feedback spanning product quality, delivery experiences, payment issues, website usability, and customer service interactions. To operate efficiently, they need an LLM that can automatically classify each comment into actionable categories with high precision. Each classification must be specific enough to route the issue to the right team: logistics, finance, development, or customer service, and trigger the appropriate workflow. This requires domain specialization.
However, this same LLM doesn’t operate in isolation. Across your organization, teams need the model to:
- Generate customer-facing responses that require general communication skills
- Perform data analysis requiring mathematical and logical reasoning
- Draft documentation following specific formatting guidelines
This requires broad general capabilities—instruction-following, reasoning, knowledge across domains, and conversational fluency.
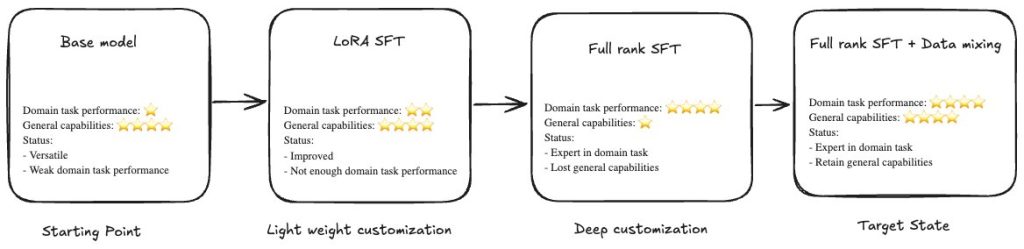
Evaluation methodology
Test overview
To test whether Nova Forge can deliver both domain specialization and general capabilities, we designed a dual-evaluation framework measuring performance across two dimensions.
For domain-specific performance, we use a real-world Voice of Customer (VOC) dataset derived from actual customer reviews. The dataset contains 14,511 training samples and 861 test samples, reflecting production-scale enterprise data. The dataset employs a four-level taxonomy where Level 4 represents the leaf categories (final classification targets). Each category includes a descriptive explanation of its scope. Example categories:
| Level 1 | Level 2 | Level 3 | Level 4 (leaf category) |
| Installation – app configuration | Initial setup guidance | Setup process | Easy setup experience: Installation process characteristics and complexity level |
| Usage – hardware experience | Night vision performance | Low-light Image quality | Night vision clarity: Night vision mode produces images in low-light or dark conditions |
| Usage – hardware experience | Pan-tilt-zoom functionality | Rotation capability | 360-degree rotation: The camera can rotate a full 360 degrees, providing complete panoramic coverage |
| After-sales policy and cost | Return and exchange policy | Return process execution | Product return completed: Customer initiated and completed product return due to functionality issues |
The dataset exhibits extreme class imbalance typical of real-world customer feedback environments. The following image displays the class distribution:
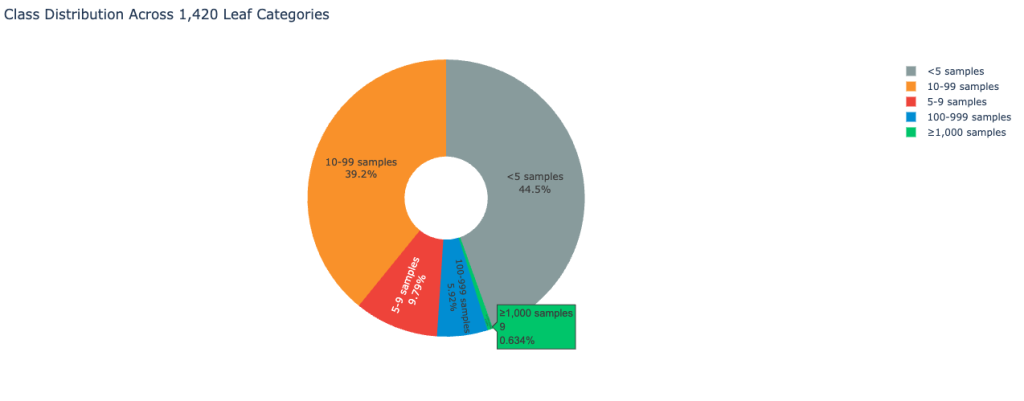
As a result, the dataset places a significant challenge on classification accuracy.
For evaluating general-purpose capabilities, we use the public test set split of the MMLU (Massive Multitask Language Understanding) benchmark (all subsets). The test spans subjects in the humanities, social sciences, hard sciences, and other areas that are important for some people to learn. In this post, MMLU serves as a proxy for general capability retention. We use it to measure whether supervised fine-tuning improves domain performance at the cost of degrading foundational model behaviors, and to assess the effectiveness of Nova data mixing in mitigating catastrophic forgetting.
| Item | Description |
| Total samples | 15,372 customer reviews |
| Label hierarchy | 4-level classification, 1,420 categories in total |
| Training set | 14,511 samples |
| Test set | 861 samples |
| MMLU Benchmark all (test split) | 14,000 samples |
In-domain task evaluation: voice of customer classification
To understand how Nova Forge performs in real enterprise scenarios, we first evaluate model accuracy on the VOC classification task before and after supervised fine-tuning. With this approach, we can quantify domain adaptation gains while establishing a baseline for subsequent robustness analysis.
Base model evaluation
We begin with a base model evaluation to assess out-of-the-box performance on the VOC classification task without any task-specific fine-tuning. This setup establishes each model’s inherent capability to handle highly granular classification under strict output format constraints. The following prompt is used for the VOC classification task:
# Role Definition
You are a rigorous customer experience classification system. Your sole responsibility is to map user feedback to the existing label taxonomy at Level 1 through Level 4 (L1–L4). You must strictly follow the predefined taxonomy structure and must not create, modify, or infer any new labels.
## Operating Principles
### 1. Strict taxonomy alignment
All classifications must be fully grounded in the provided label taxonomy and strictly adhere to its hierarchical structure.
### 2. Feedback decomposition using MECE principles
A single piece of user feedback may contain one or multiple issues. You must carefully analyze all issues described and decompose the feedback into multiple non-overlapping segments, following the MECE (Mutually Exclusive, Collectively Exhaustive) principle:
- **Semantic singularity**: Each segment describes only one issue, function, service, or touchpoint (for example, pricing, performance, or UI).
- **Independence**: Segments must not overlap in meaning.
- **Complete coverage**: All information in the original feedback must be preserved without omission.
### 3. No taxonomy expansion
You must not invent, infer, or modify any labels or taxonomy levels.
## Label Taxonomy
The following section provides the label taxonomy: {tag category}. Use this taxonomy to perform L1–L4 classification for the original VOC feedback. No taxonomy expansion is allowed.
## Task Instructions
You will be given a piece of user feedback: {user comment}. Users may come from different regions and use different languages. You must accurately understand the user's language and intent before assigning labels.
Refer to the provided examples for the expected labeling format.
## Output Format
Return the classification results in JSON format only. For each feedback segment, output the original text along with the corresponding L1–L4 labels and sentiment. Do not generate or rewrite content.
```json
[
{
"content": "<comment_text>",
"L1": "<L1>",
"L2": "<L2>",
"L3": "<L3>",
"L4": "<L4>",
"emotion": "<emotion>"
}
]
```
For base model evaluation, we selected:
- Amazon Nova 2 Lite: Evaluated on Amazon Bedrock
- Qwen3-30B-A3B: Open source model deployed on Amazon Elastic Compute Cloud (Amazon EC2) with vLLM
| Model | Precision | Recall | F1-Score |
| Nova 2 Lite | 0.4596 | 0.3627 | 0.387 |
| Qwen3-30B-A3B | 0.4567 | 0.3864 | 0.394 |
The F1-scores reveal that Nova 2 Lite and Qwen3-30B-A3B demonstrate comparable performance on this domain-specific task, with both models achieving F1-scores near 0.39. These results also highlight the inherent difficulty of the task: even strong foundation models struggle with fine-grained label classification when no domain-specific data is provided.
Supervised fine-tuning
We then apply full-parameter supervised fine-tuning (SFT) using customer VOC data. All models are fine-tuned using the same dataset and comparable training configurations for a fair comparison.
Training infrastructure:
- Nova 2 Lite: Fine-tuned on Amazon SageMaker HyperPod cluster using four p5.48xlarge instances (as specified in the Nova customization SageMaker hyperpod topic in the Amazon SageMaker AI Developer Guide)
- Qwen3-30B-A3B: Fine-tuned on Amazon EC2 using p6-b200.48xlarge instances
In domain task performance comparison
| Model | Training Data | Precision | Recall | F1-Score |
| Nova 2 Lite | None (baseline) | 0.4596 | 0.3627 | 0.387 |
| Nova 2 Lite | Customer data only | 0.6048 | 0.5266 | 0.5537 |
| Qwen3-30B | Customer data only | 0.5933 | 0.5333 | 0.5552 |
After fine-tuning on customer data alone, Nova 2 Lite achieves a substantial performance improvement, with F1 increasing from 0.387 to 0.5537—an absolute gain of 17 points. This result places the Nova model in the top tier for this task and makes its performance comparable to that of the fine-tuned Qwen3-30B open-source model. These results confirm the effectiveness of Nova full-parameter SFT for complex enterprise classification workloads.
General capabilities evaluation: MMLU benchmark
Models fine-tuned for VOC classification are often deployed beyond a single task and integrated into broader enterprise workflows. Preserving general-purpose capabilities is important. Industry-standard benchmarks such as MMLU provide an effective mechanism for evaluating general-purpose capabilities and detecting catastrophic forgetting in fine-tuned models.
For the fine-tuned Nova model, Amazon SageMaker HyperPod offers out-of-the-box evaluation recipes that streamline MMLU evaluation with minimal configuration.
| Model | Training data | VOC F1-Score | MMLU accuracy |
| Nova 2 Lite | None (baseline) | 0.38 | 0.75 |
| Nova 2 Lite | Customer data only | 0.55 | 0.47 |
| Nova 2 Lite | 75% customer + 25% Nova data | 0.5 | 0.74 |
| Qwen3-30B | Customer data only | 0.55 | 0.0038 |
When Nova 2 Lite is fine-tuned using customer data only, we observe a significant drop in MMLU accuracy from 0.75 to 0.47, indicating the loss of general-purpose capabilities. The degradation is even more pronounced for the Qwen model, which largely loses instruction-following ability after fine-tuning. An example of Qwen model degraded output:
{
"prediction": "[n {n "content": "x^5 + 3x^3 + x^2 + 2x in Z_5",n "A": "0",n "B": "1",n "C": "0,1",n "D": "0,4",n "emotion": "neutral"n }n]"
}This behavior is also related to the VOC prompt design, where category knowledge is internalized through supervised fine-tuning—a common approach in large-scale classification systems.
Notably, when Nova data mixing is applied during fine-tuning, Nova 2 Lite retains near-baseline general performance. MMLU accuracy remains at 0.74, only 0.01 below the original baseline, while VOC F1 still improves by 12 points (0.38 → 0.50). This validates that Nova data mixing is a practical and effective mechanism for mitigating catastrophic forgetting while preserving domain performance.
Key findings and practical recommendations
This evaluation shows that when the base model provides a strong foundation, full-parameter supervised fine-tuning on Amazon Nova Forge can deliver substantial gains for complex enterprise classification tasks. At the same time, the results confirm that catastrophic forgetting is a real concern in production fine-tuning workflows. Fine-tuning on customer data alone can degrade general-purpose capabilities such as instruction following and reasoning, limiting a model’s usability across broader business scenarios.
The data mixing capability of Nova Forge provides an effective mitigation strategy. By blending customer data with Nova-curated datasets during fine-tuning, teams can preserve near-baseline general capabilities while continuing to achieve strong domain-specific performance.
Based on these findings, we recommend the following practices when using Nova Forge:
- Use supervised fine-tuning to maximize in-domain performance for complex or highly customized tasks.
- Apply Nova data mixing when models are expected to support multiple general-purpose workflows in production, to reduce the risk of catastrophic forgetting.
Together, these practices help balance model customization with production robustness, enabling more reliable deployment of fine-tuned models in enterprise environments.

Conclusion
In this post, we demonstrated how organizations can build specialized AI models without sacrificing general intelligence with Nova Forge data mixing capabilities. Depending on your use cases and business objectives, Nova Forge can deliver other benefits, including access checkpoints across all phases of model development and performing reinforcement learning with reward functions in your environment. To get started with your experiments, see the Nova Forge Developer Guide for detailed documentation.
About the authors
 Yuan Wei is an Applied Scientist at Amazon Web Services, working with enterprise customers on proof-of-concepts and technical advisory. She specializes in large language models and vision-language models, with a focus on evaluating emerging techniques under real-world data, cost, and system constraints.
Yuan Wei is an Applied Scientist at Amazon Web Services, working with enterprise customers on proof-of-concepts and technical advisory. She specializes in large language models and vision-language models, with a focus on evaluating emerging techniques under real-world data, cost, and system constraints.
 Xin Hao is a Senior AI/ML Go-to-Market Specialist at AWS, helping customers achieve success with Amazon Nova models and related Generative AI solutions. He has extensive hands-on experience in cloud computing, AI/ML, and Generative AI. Prior to joining AWS, Xin spent over 10 years in the industrial manufacturing sector, including industrial automation and CNC machining.
Xin Hao is a Senior AI/ML Go-to-Market Specialist at AWS, helping customers achieve success with Amazon Nova models and related Generative AI solutions. He has extensive hands-on experience in cloud computing, AI/ML, and Generative AI. Prior to joining AWS, Xin spent over 10 years in the industrial manufacturing sector, including industrial automation and CNC machining.
 Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.

