

Enterprises in regulated industries often need mathematical certainty that every AI response complies with established policies and domain knowledge. Regulated industries can’t use traditional quality assurance methods that test only a statistical sample of AI outputs and make probabilistic assertions about compliance. When we launched Automated Reasoning checks in Amazon Bedrock Guardrails in preview at AWS re:Invent 2024, it offered a novel solution by applying formal verification techniques to systematically validate AI outputs against encoded business rules and domain knowledge. These techniques make the validation output transparent and explainable.
Automated Reasoning checks are being used in workflows across industries. Financial institutions verify AI-generated investment advice meets regulatory requirements with mathematical certainty. Healthcare organizations make sure patient guidance aligns with clinical protocols. Pharmaceutical companies confirm marketing claims are supported by FDA-approved evidence. Utility companies validate emergency response protocols during disasters, while legal departments verify AI tools capture mandatory contract clauses.
With the general availability of Automated Reasoning, we have increased document handling and added new features like scenario generation, which automatically creates examples that demonstrate your policy rules in action. With the enhanced test management system, domain experts can build, save, and automatically execute comprehensive test suites to maintain consistent policy enforcement across model and application versions.
In the first part of this two-part technical deep dive, we’ll explore the technical foundations of Automated Reasoning checks in Amazon Bedrock Guardrails and demonstrate how to implement this capability to establish mathematically rigorous guardrails for generative AI applications.
In this post, you will learn how to:
- Understand the formal verification techniques that enable mathematical validation of AI outputs
- Create and refine an Automated Reasoning policy from natural language documents
- Design and implement effective test cases to validate AI responses against business rules
- Apply policy refinement through annotations to improve policy accuracy
- Integrate Automated Reasoning checks into your AI application workflow using Bedrock Guardrails, following AWS best practices to maintain high confidence in generated content
By following this implementation guide, you can systematically help prevent factual inaccuracies and policy violations before they reach end users, a critical capability for enterprises in regulated industries that require high assurance and mathematical certainty in their AI systems.
Core capabilities of Automated Reasoning checks
In this section, we explore the capabilities of Automated Reasoning checks, including the console experience for policy development, document processing architecture, logical validation mechanisms, test management framework, and integration patterns. Understanding these core components will provide the foundation for implementing effective verification systems for your generative AI applications.
Console experience
The Amazon Bedrock Automated Reasoning checks console organizes policy development into logical sections, guiding you through the creation, refinement, and testing process. The interface includes clear rule identification with unique IDs and direct use of variable names within the rules, making complex policy structures understandable and manageable.
Document processing capacity
Document processing supports up to 120K tokens (approximately 100 pages), so you can encode substantial knowledge bases and complex policy documents into your Automated Reasoning policies. Organizations can incorporate comprehensive policy manuals, detailed procedural documentation, and extensive regulatory guidelines. With this capacity you can work with complete documents within a single policy.
Validation capabilities
The validation API includes ambiguity detection that identifies statements requiring clarification, counterexamples for invalid findings that demonstrate why validation failed, and satisfiable findings with both valid and invalid examples to help understand boundary conditions. These features provide context around validation results, to help you understand why specific responses were flagged and how they can be improved. The system can also express its confidence in translations between natural language and logical structures to set appropriate thresholds for specific use cases.
Iterative feedback and refinement process
Automated Reasoning checks provide detailed, auditable findings that explain why a response failed validation, to support an iterative refinement process instead of simply blocking non-compliant content. This information can be fed back to your foundation model, allowing it to adjust responses based on specific feedback until they comply with policy rules. This approach is particularly valuable in regulated industries where factual accuracy and compliance must be mathematically verified rather than estimated.
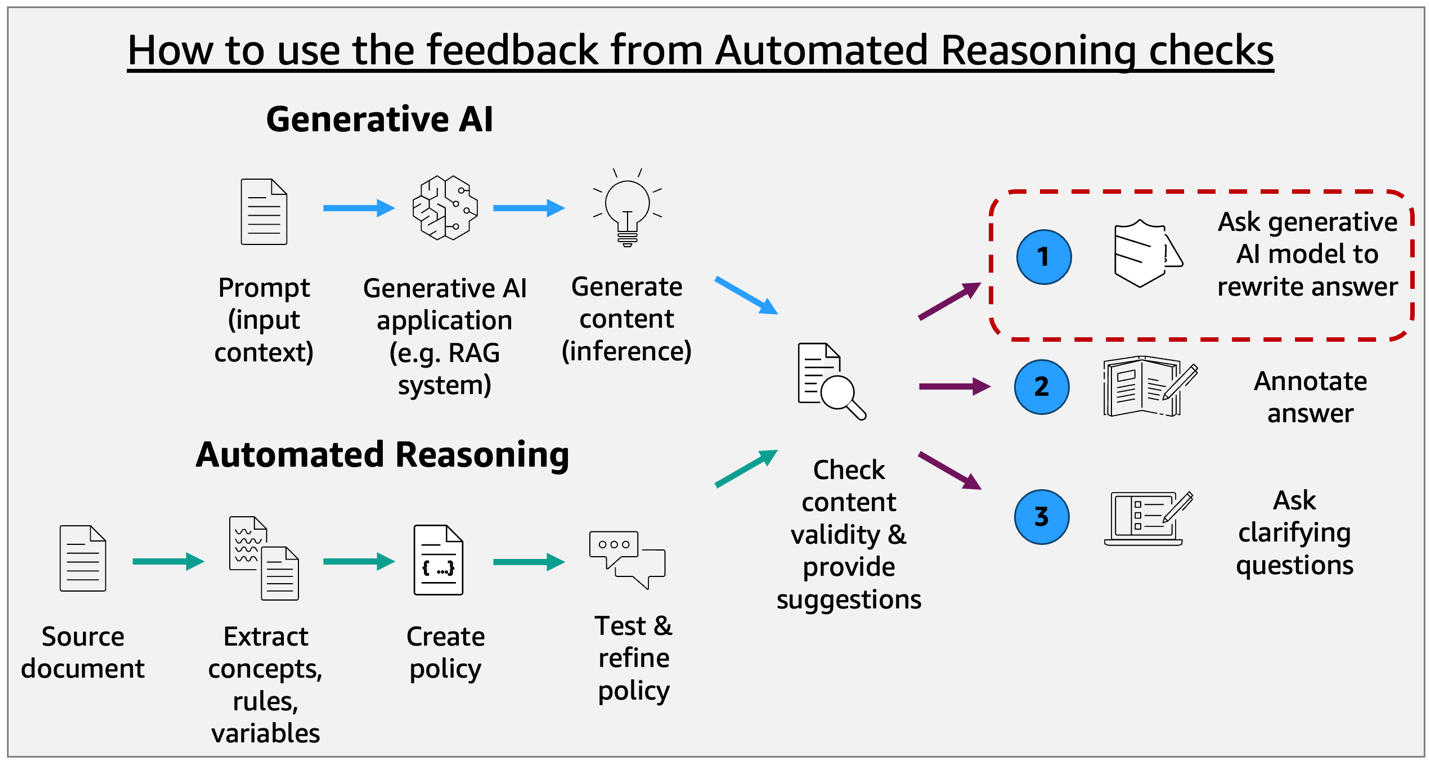
Finding types using a policy example
Consider the example of a policy for determining days off. When implementing Automated Reasoning checks, a policy consists of both a schema of variables (defining concepts like employee type, years of service, and available leave days) and a set of logical rules that establish relationships between these variables (such as eligibility conditions for different types of time off). During validation, the system uses this schema and rule structure to evaluate whether foundation model responses comply with your defined policy constraints.
We want to validate the following input that a user asked the foundation model (FM) powered application and the generated output.
Premises are statements from which a conclusion is drawn and the claim is an assertion of the truth. In this example, the premises inferred are day is equal to “Thursday” and is_public_holiday is true, and the claim is made that is_day_off is true.
This reasoning follows the automated reasoning policy:
With general availability, Automated Reasoning checks now produces seven distinct finding types that offer precise insights into the validation process of a FM generated response:
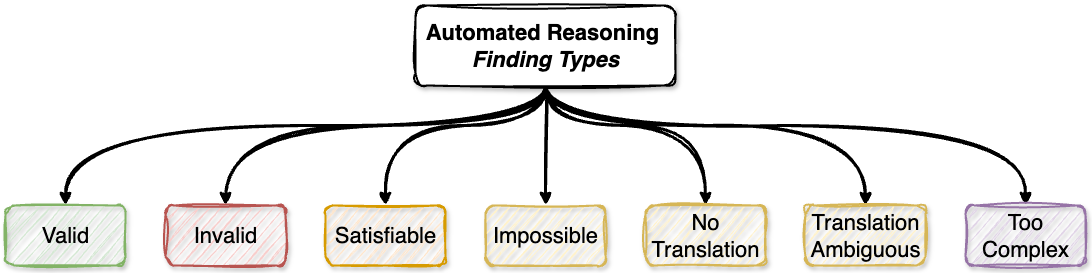
VALID: Confirms Input and Output fully aligns with policy rules, providing confidence that the information in the generated response is correct according to your defined policies. The claims are inferred from the premises and validated by the AR policy to be true, and there are no alternative answers that contradict these claims.
SATISFIABLE: Recognizes that Input and Output could be true or false depending on specific assumptions. These findings help you understand boundary conditions where a response is valid only under certain conditions, so that you can decide whether those assumptions are reasonable in your context. If the required assumptions are false, then an alternative claim consistent with the premises may exist.
INVALID: Identifies Input and Output have policy inaccuracies or factual errors, enhanced with counter-examples that explicitly demonstrate why the validation failed. The claims are not implied by the premises and AR policy, and there exist different claims that would be consistent with the premises and AR policy.
IMPOSSIBLE: Indicates when no valid Claims can be generated because the premises conflict with the AR policy or the policy contains internal contradictions. This finding occurs when the constraints defined in the policy create a logical impossibility.
NO_TRANSLATIONS: Occurs when the Input and Output contains no information that can be translated into relevant data for the AR policy evaluation. This typically happens when the text is entirely unrelated to the policy domain or contains no actionable information.
TRANSLATION_AMBIGUOUS: Identifies when ambiguity in the Input and Output prevents definitive translation into logical structures. This finding suggests that additional context or follow-up questions may be needed to proceed with validation.
TOO_COMPLEX: Signals that the Input and Output contains too much information to process within latency limits. This finding occurs with extremely large or complex inputs that exceed the system’s current processing capabilities.
Scenario generation
You can now generate scenarios directly from your policy, which creates test samples that conform to your policy rules, helps identify edge cases, and supports verification of your policy’s business logic implementation. With this capability policy authors can see concrete examples of how their rules work in practice before deployment, reducing the need for extensive manual testing. The scenario generation also highlights potential conflicts or gaps in policy coverage that might not be apparent from examining individual rules.
Test management system
A new test management system allows you to save and annotate policy tests, build test libraries for consistent validation, execute tests automatically to verify policy changes, and maintain quality assurance across policy versions. This system includes versioning capabilities that track test results across policy iterations, making it easier to identify when changes might have unintended consequences. You can now also export test results for integration into existing quality assurance workflows and documentation processes.
Expanded options with direct guardrail integration
Automated Reasoning checks now integrates with Amazon Bedrock APIs, enabling validation of AI generated responses against established policies throughout complex interactions. This integration extends to both the Converse and RetrieveAndGenerate actions, allowing policy enforcement across different interaction modalities. Organizations can configure validation confidence thresholds appropriate to their domain requirements, with options for stricter enforcement in regulated industries or more flexible application in exploratory contexts.
Solution – AI-powered hospital readmission risk assessment system
Now that we have explained the capabilities of Automated Reasoning checks, let’s work through a solution by considering the use case of an AI-powered hospital readmission risk assessment system. This AI system automates hospital readmission risk assessment by analyzing patient data from electronic health records to classify patients into risk categories (Low, Intermediate, High) and recommends personalized intervention plans based on CDC-style guidelines. The objective of this AI system is to reduce the 30-day hospital readmission rates by supporting early identification of high-risk patients and implementing targeted interventions. This application is an ideal candidate for Automated Reasoning checks because the healthcare provider prioritizes verifiable accuracy and explainable recommendations that can be mathematically proven to comply with medical guidelines, supporting both clinical decision-making and satisfying the strict auditability requirements common in healthcare settings.
Note: The referenced policy document is an example created for demonstration purposes only and should not be used as an actual medical guideline or for clinical decision-making.
Prerequisites
To use Automated Reasoning checks in Amazon Bedrock, verify you have met the following prerequisites:
- An active AWS account
- Confirmation of AWS Regions where Automated Reasoning checks is available
- Appropriate IAM permissions to create, test, and invoke Automated Reasoning policies (Note: The IAM policy should be fine-grained and limited to necessary resources using proper ARN patterns for production usage):
- Key service limits: Be aware of the service limits when implementing Automated Reasoning checks.
- With Automated Reasoning checks, you pay based on the amount of text processed. For more information, see Amazon Bedrock pricing. For more information, see Amazon Bedrock pricing.
Use case and policy dataset overview
The full policy document used in this example can be accessed from the Automated Reasoning GitHub repository. To validate the results from Automated Reasoning checks, being familiar with the policy is helpful. Moreover, refining the policy that is created by Automated Reasoning is key in achieving a soundness of over 99%.
Let’s review the main details of the sample medical policy that we are using in this post. As we start validating responses, it is helpful to verify it against the source document.
- Risk assessment and stratification: Healthcare facilities must implement a standardized risk scoring system based on demographic, clinical, utilization, laboratory, and social factors, with patients classified into Low (0-3 points), Intermediate (4-7 points), or High Risk (8+ points) categories.
- Mandatory interventions: Each risk level requires specific interventions, with higher risk levels incorporating lower-level interventions plus additional measures, while certain conditions trigger automatic High Risk classification regardless of score.
- Quality metrics and compliance: Facilities must achieve specific completion rates including 95%+ risk assessment within 24 hours of admission and 100% completion before discharge, with High Risk patients requiring documented discharge plans.
- Clinical oversight: While the scoring system is standardized, attending physicians maintain override authority with proper documentation and approval from the discharge planning coordinator.
Create and test an Automated Reasoning checks’ policy using the Amazon Bedrock console
The first step is to encode your knowledge—in this case, the sample medical policy—into an Automated Reasoning policy. Complete the following steps to create an Automated Reasoning policy:
- On the Amazon Bedrock console, choose Automated Reasoning under Build in the navigation pane.
- Choose Create policy.
- Provide a policy name and policy description.

- Add source content from which Automated Reasoning will generate your policy. You can either upload document (pdf, txt) or enter text as the ingest method.

- Include a description of the intent of the Automated Reasoning policy you’re creating. The intent is optional but provides valuable information to the Large Language Models that are translating the natural language based document into a set of rules that can be used for mathematical verification. For the sample policy, you can use the following intent:
This logical policy validates claims about the clinical practice guideline providing evidence-based recommendations for healthcare facilities to systematically assess and mitigate hospital readmission risk through a standardized risk scoring system, risk-stratified interventions, and quality assurance measures, with the goal of reducing 30-day readmissions by 15-23% across participating healthcare systems. Following is an example patient profile and the corresponding classification. <Patient Profile>Age: 82 years Length of stay: 10 days Has heart failure One admission within last 30 days Lives alone without caregiver <Classification> High Risk
- Once the policy has been created, we can inspect the definitions to see which rules, variables and types have been created from the natural language document to represent the knowledge into logic.
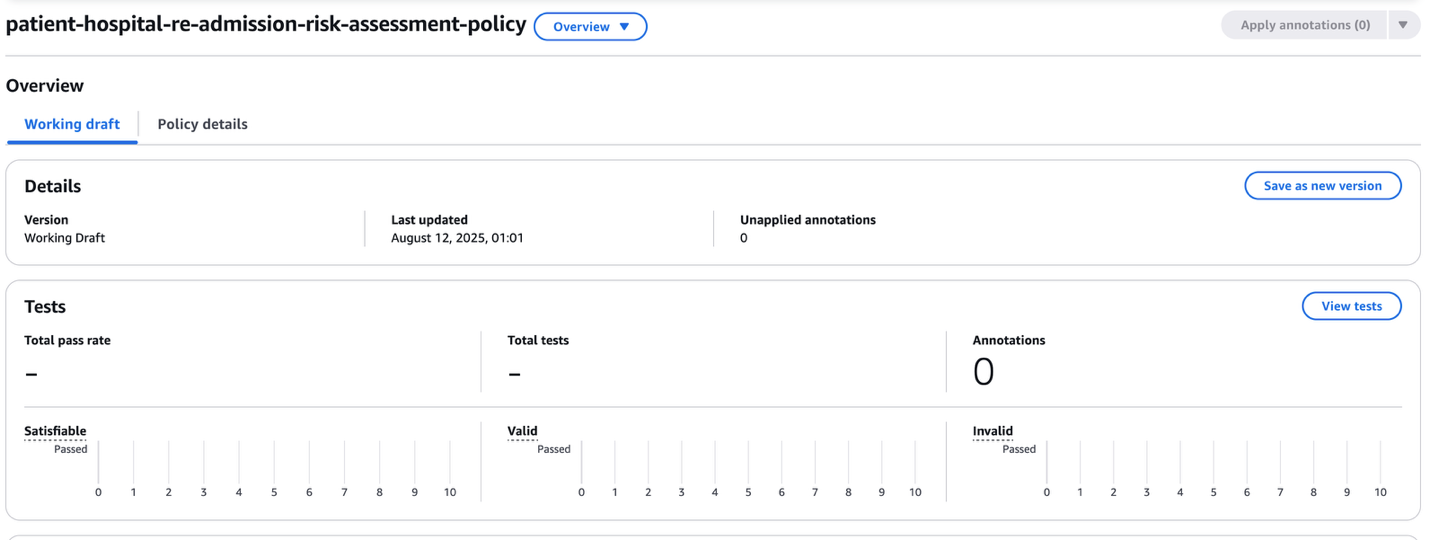

You may see differences in the number of rules, variables, and types generated compared to what is shown in this example. This is due to the non-deterministic processing of the supplied document. To address this, the recommended guidance is to perform a human-in-the-loop review of the generated information in the policy before using it with other systems.
Exploring the Automated Reasoning checks’ definition
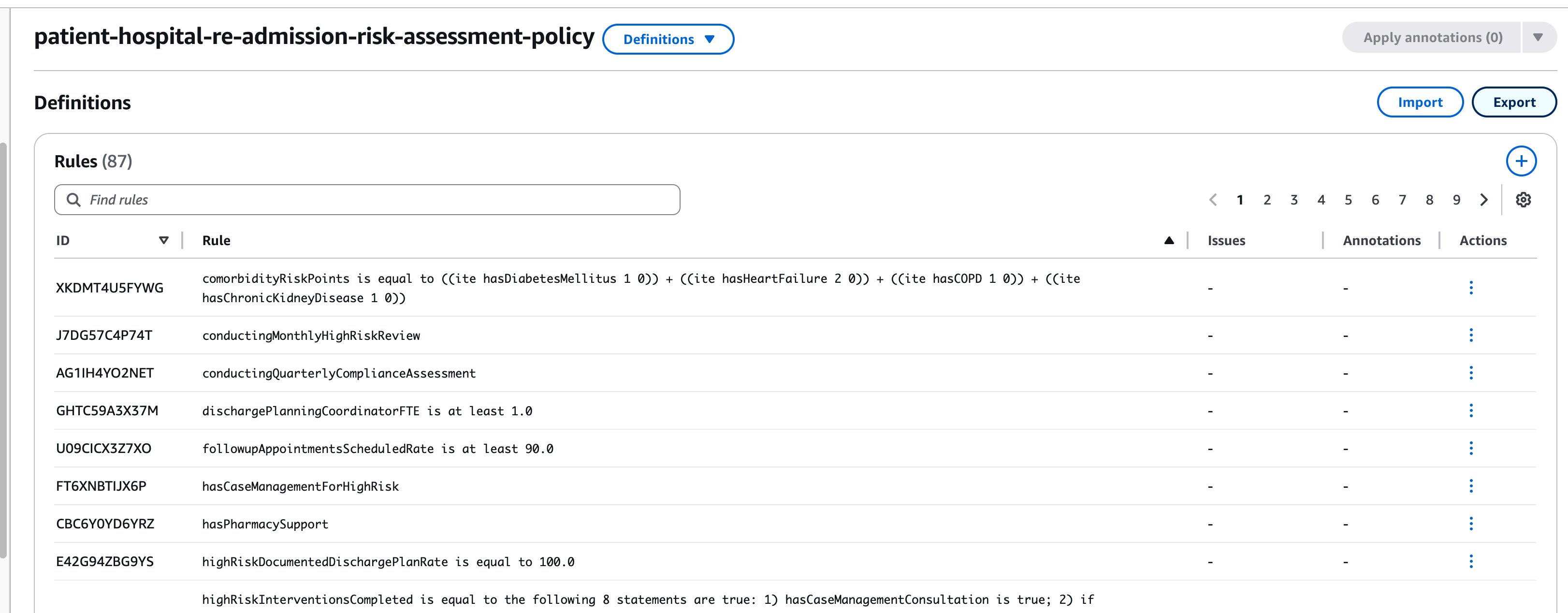
A Variable in automated reasoning for policy documents is a named container that holds a specific type of information (like Integer, Real Number, or Boolean) and represents a distinct concept or measurement from the policy. Variables act as building blocks for rules and can be used to track, measure, and evaluate policy requirements. From the image below, we can see examples like admissionsWithin30Days (an Integer variable tracking previous hospital admissions), ageRiskPoints (an Integer variable storing age-based risk scores), and conductingMonthlyHighRiskReview (a Boolean variable indicating whether monthly reviews are being performed). Each variable has a clear description of its purpose and the specific policy concept it represents, making it possible to use these variables within rules to enforce policy requirements and measure compliance. Issues also highlight that some variables are unused. It is particularly important to verify which concepts these variables represent and to identify if rules are missing.
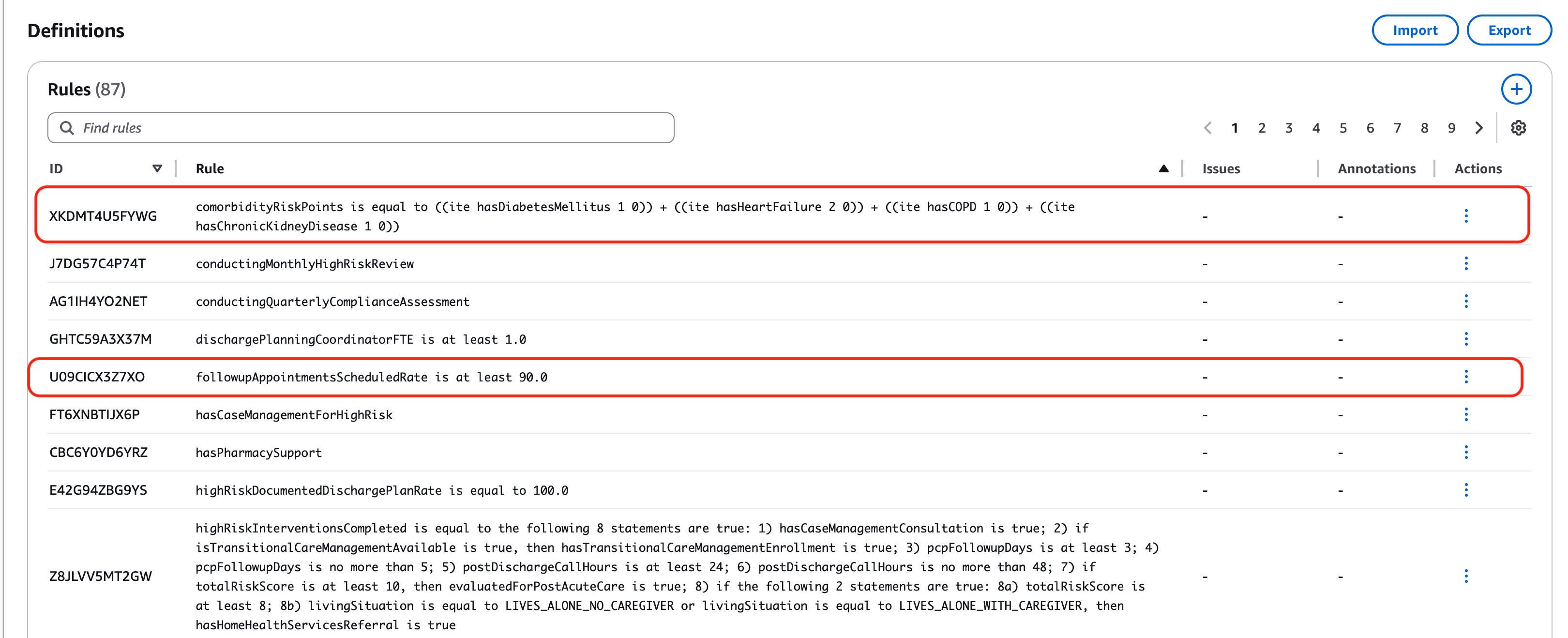
In the Definitions, we see ‘Rules’, ‘Variables’ and ‘Types’. A rule is an unambiguous logical statement that Automated Reasoning extracts from your source document. Consider this simple rule that has been created: followupAppointmentsScheduledRate is at least 90.0 – This rule has been created from the Section III A Process Measures, which states that healthcare facilities should monitor various process indications, requiring that follow up appointments scheduled prior to discharge should be 90% or higher.
Let’s look at a more complex rule:
This rule calculates a patient’s risk points based on their existing medical conditions (comorbidities) as specified in the policy document. When evaluating a patient, the system checks for four specific conditions: diabetes mellitus of any type (worth 1 point), heart failure of any classification (worth 2 points), chronic obstructive pulmonary disease (worth 1 point), and chronic kidney disease stages 3-5 (worth 1 point). The rule adds these points together by using boolean logic – meaning it multiplies each condition (represented as true=1 or false=0) by its assigned point value, then sums all values to generate a total comorbidity risk score. For instance, if a patient has both heart failure and diabetes, they would receive 3 total points (2 points for heart failure plus 1 point for diabetes). This comorbidity score then becomes part of the larger risk assessment framework used to determine the patient’s overall readmission risk category.

The Definitions also include custom variable types. Custom variable types, also known as enumerations (ENUMs), are specialized data structures that define a fixed set of allowable values for specific policy concepts. These custom types maintain consistency and accuracy in data collection and rule enforcement by limiting values to predefined options that align with the policy requirements. In the sample policy, we can see that four custom variable types have been identified:
AdmissionType: This defines the possible types of hospital admissions (MEDICAL, SURGICAL, MIXED_MEDICAL_SURGICAL, PSYCHIATRIC) that determine whether a patient is eligible for the readmission risk assessment protocol.HealthcareFacilityType: This specifies the types of healthcare facilities (ACUTE_CARE_HOSPITAL_25PLUS, CRITICAL_ACCESS_HOSPITAL) where the readmission risk assessment protocol may be implemented.LivingSituation: This categorizes a patient’s living arrangement (LIVES_ALONE_NO_CAREGIVER, LIVES_ALONE_WITH_CAREGIVER) which is a critical factor in determining social support and risk levels.RiskCategory: This defines the three possible risk stratification levels (LOW_RISK, INTERMEDIATE_RISK, HIGH_RISK) that can be assigned to a patient based on their total risk score.
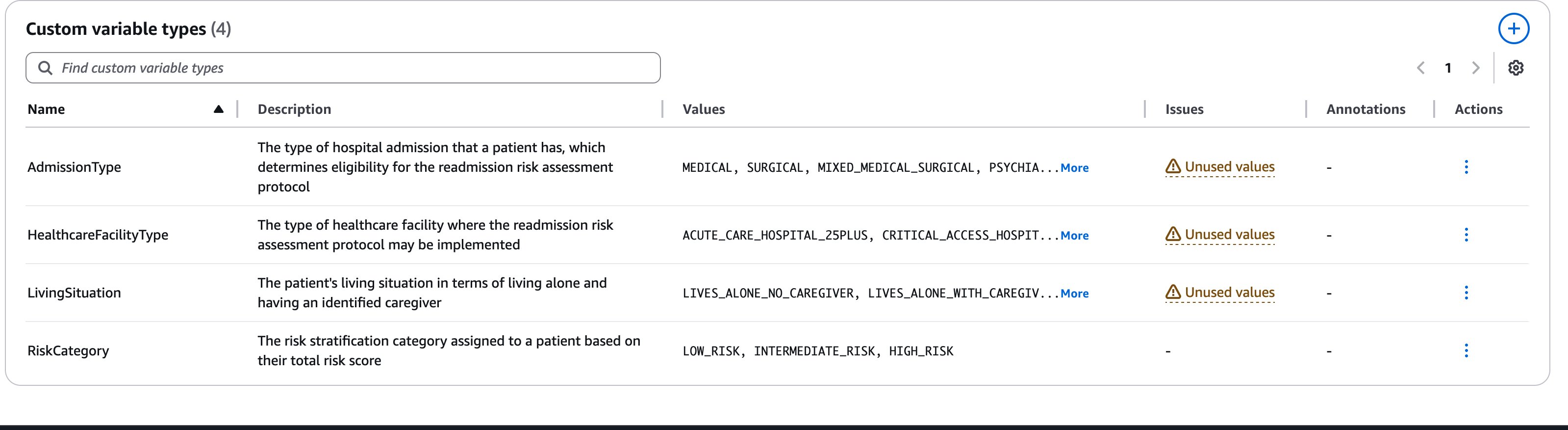
An important step in improving soundness (accuracy of Automated Reasoning checks when it says VALID), is the policy refinement step of making sure that the rules, variable, and types that are captured best represent the source of truth. In order to do this, we will head over to the test suite and explore how to add tests, generate tests and use the results from the tests to apply annotations that will update the rules.
Testing the Automated Reasoning policy and policy refinement
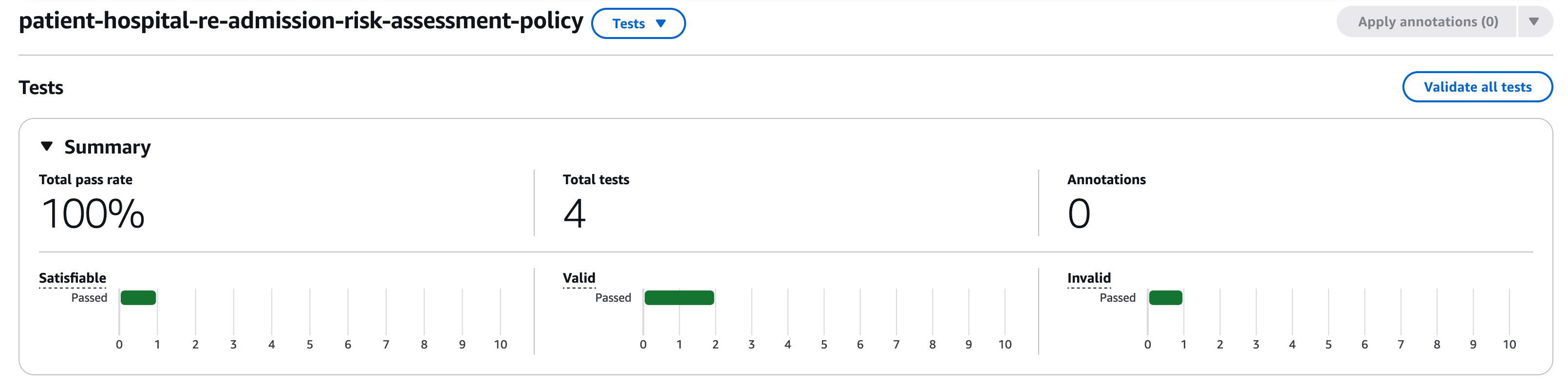
The test suite in Automated Reasoning provides test capabilities for two purposes: First, we want to run different scenarios and test the various rules and variables in the Automated Reasoning policy and refine them so that they accurately represent the ground truth. This policy refinement step is important to improving the soundness of Automated Reasoning checks. Second, we want metrics to understand how well the Automated Reasoning checks performs for the defined policy and the use case. To do so, we can open the Tests tab on Automated Reasoning console.
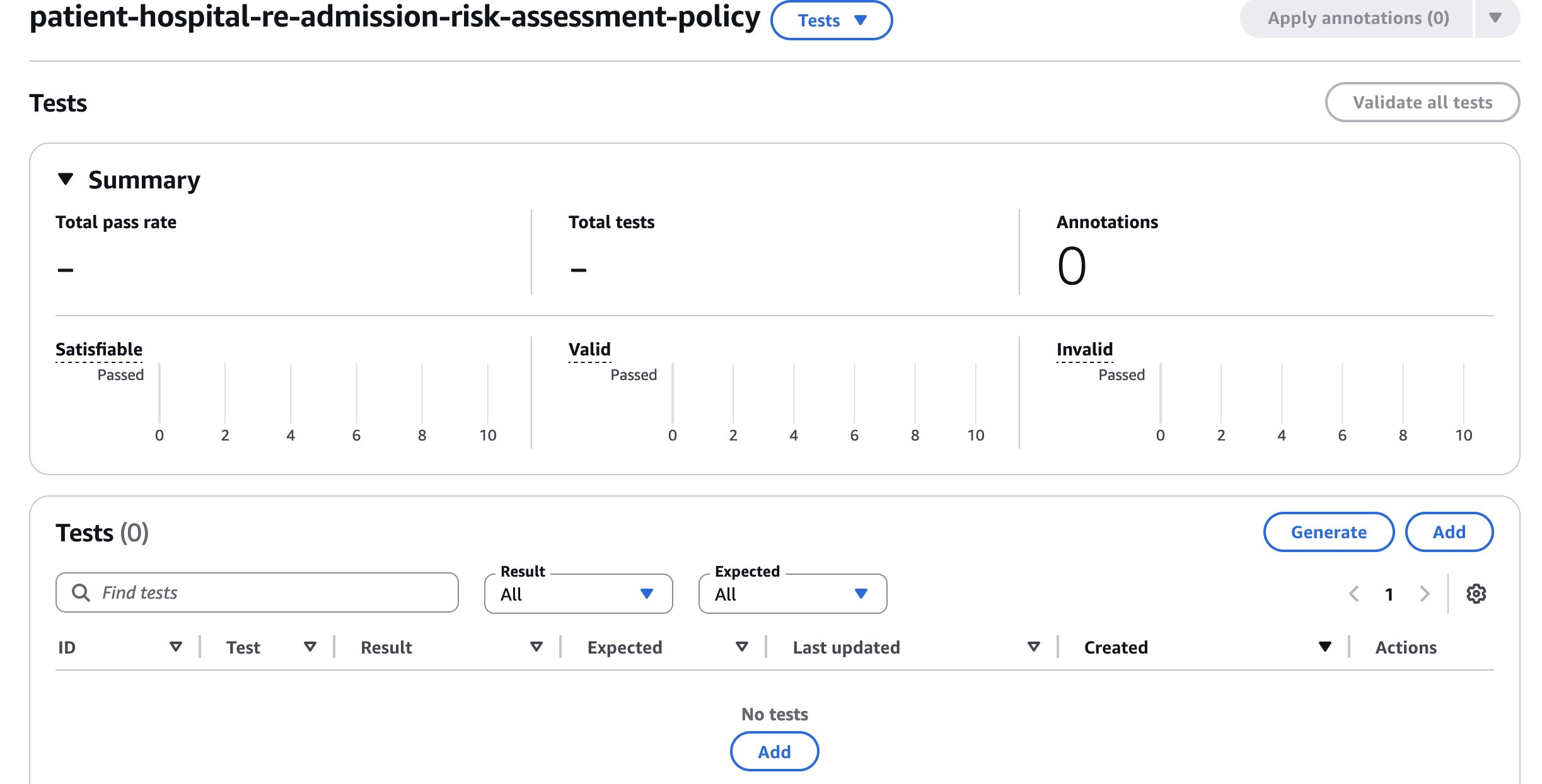
Test samples can be added manually by using the Add button. To scale up the testing, we can generate tests from the policy rules. This testing approach helps verify both the semantic correctness of your policy (making sure rules accurately represent intended policy constraints) and the natural language translation capabilities (confirming the system can correctly interpret the language your users will use when interacting with your application). In the image below, we can see a test sample generated and before adding it to the test suite, the SME should indicate if this test sample is possible (thumbs up) or not possible (thumbs up). The test sample can then be saved to the test suite.
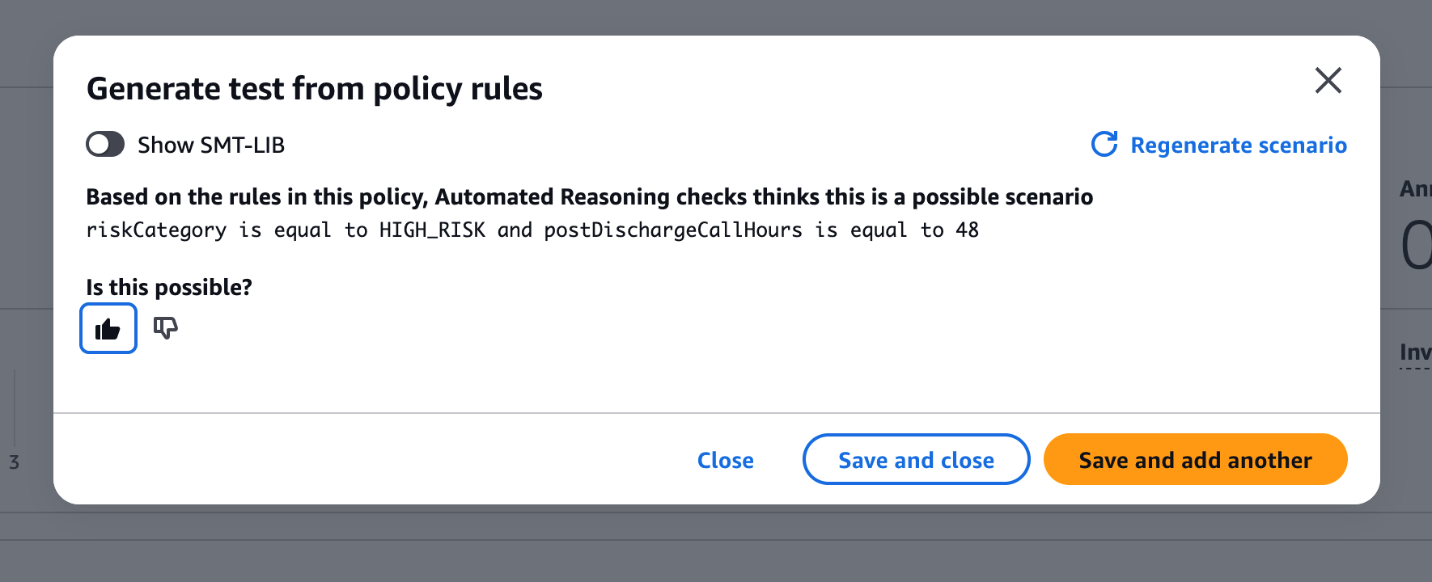
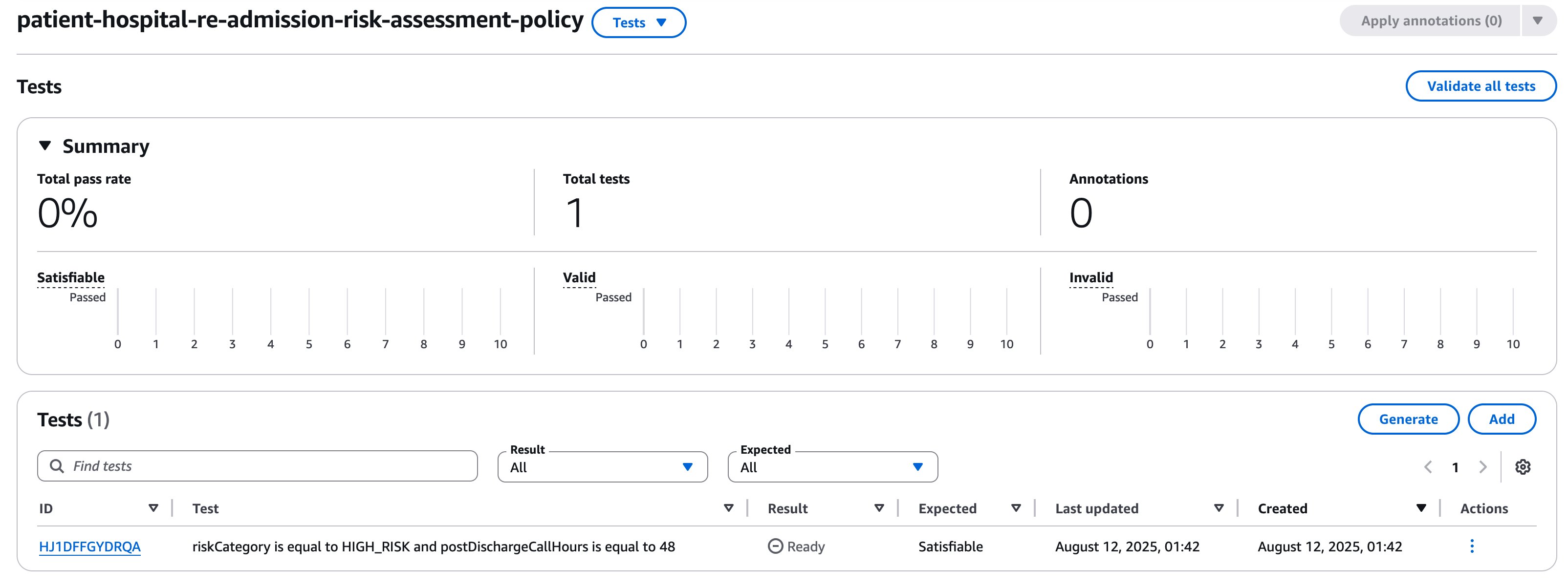
Once the test sample is created, it possible to run this test sample alone, or all the test samples in the test suite by choosing on Validate all tests. Upon executing, we see that this test passed successfully.
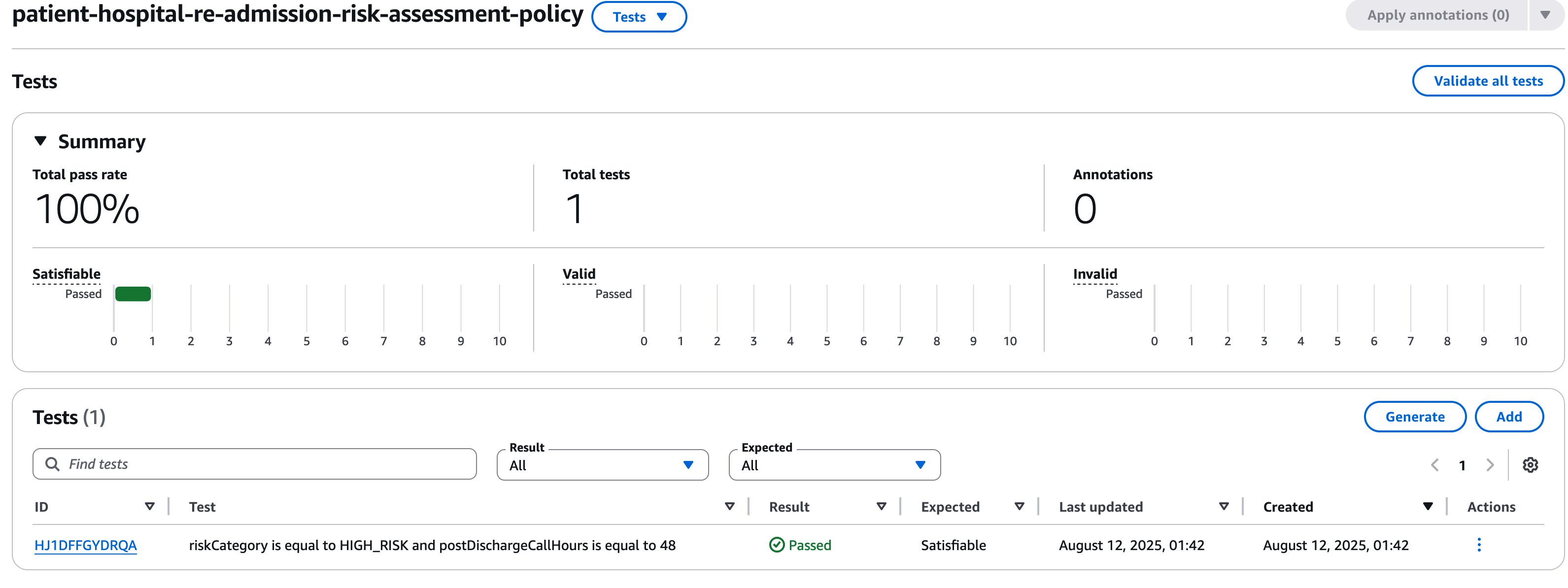
You can manually create tests by providing an input (optional) and output. These are translated into logical representations before validation occurs.
How translation works:
Translation converts your natural language tests into logical representations that can be mathematically verified against your policy rules:
- Automated Reasoning Checks uses multiple LLMs to translate your input/output into logical findings
- Each translation receives a confidence vote indicating translation quality
- You can set a confidence threshold to control which findings are validated and returned
Confidence threshold behavior:
The confidence threshold controls which translations are considered reliable enough for validation, balancing strictness with coverage:
- Higher threshold: Greater certainty in translation accuracy but also higher chance of no findings being validated.
- Lower threshold: Greater chance of getting validated findings returned, but potentially less certain translations
- Threshold = 0: All findings are validated and returned regardless of confidence
Ambiguous results:
When no finding meets your confidence threshold, Automated Reasoning Checks returns “Translation Ambiguous,” indicating uncertainty in the content’s logical interpretation.The test case we will create and validate is:
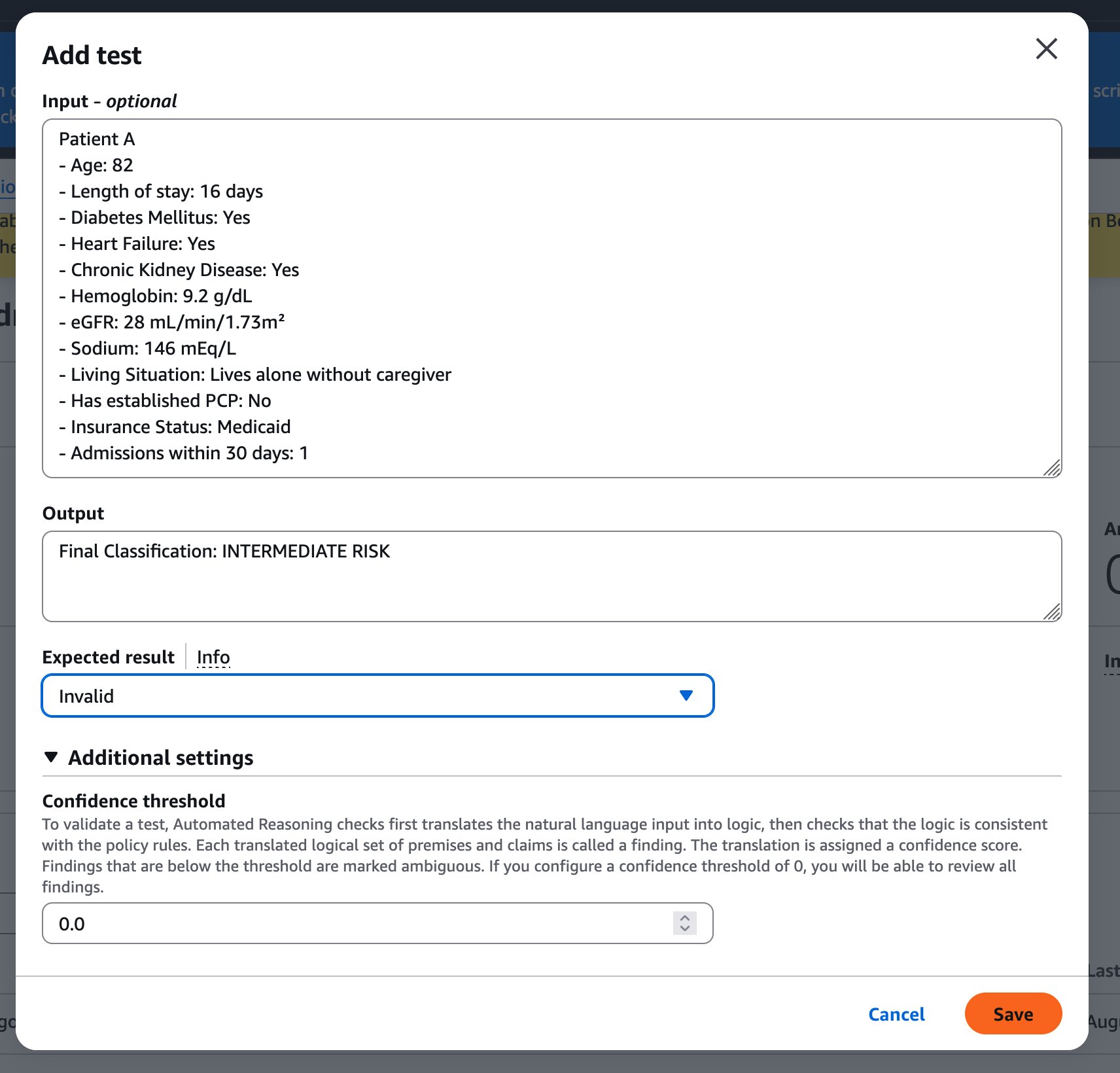
We see that this test passed upon running it, the result of ‘INVALID’ matches our expected results. Additionally Automated Reasoning checks also shows that 12 rules were contradicting the premises and claims, which lead to the output of the test sample being ‘INVALID’
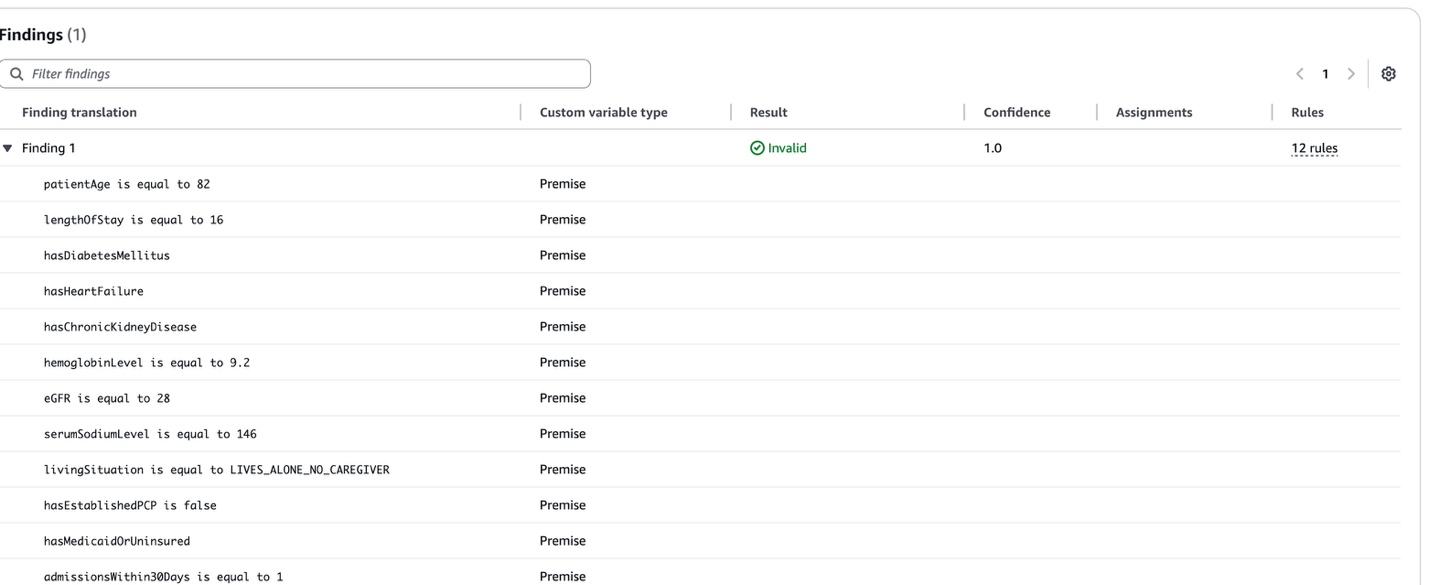
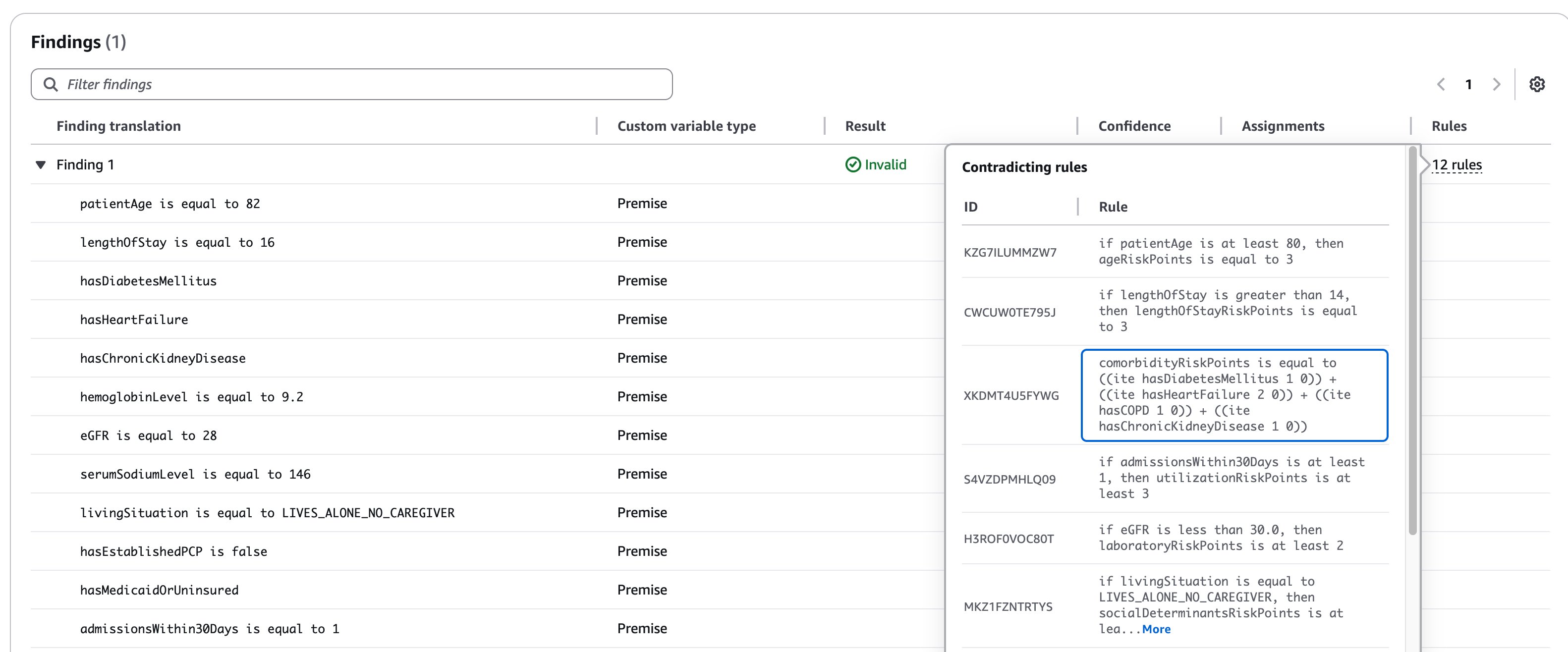
Let’s examine some of the visible contradicting rules:
- Age risk: Patient is 82 years old
- Rule triggers: “if patientAge is at least 80, then ageRiskPoints is equal to 3”
- Length of stay risk: Patient stayed 16 days
- Rule triggers: “if lengthOfStay is greater than 14, then lengthOfStayRiskPoints is equal to 3”
- Comorbidity risk: Patient has multiple conditions
- Rule calculates: “comorbidityRiskPoints = (hasDiabetesMellitus × 1) + (hasHeartFailure × 2) + (hasCOPD × 1) + (hasChronicKidneyDisease × 1)”
- Utilization risk: Patient has 1 admission within 30 days
- Rule triggers: “if admissionsWithin30Days is at least 1, then utilizationRiskPoints is at least 3”
- Laboratory risk: Patient’s eGFR is 28
- Rule triggers: “if eGFR is less than 30.0, then laboratoryRiskPoints is at least 2”
These rules are likely producing conflicting risk scores, making it impossible for the system to determine a valid final risk category. These contradictions show us which rules where used to determine that the input text of the test is INVALID.
Let’s add another test to the test suite, as shown in the screenshot below:
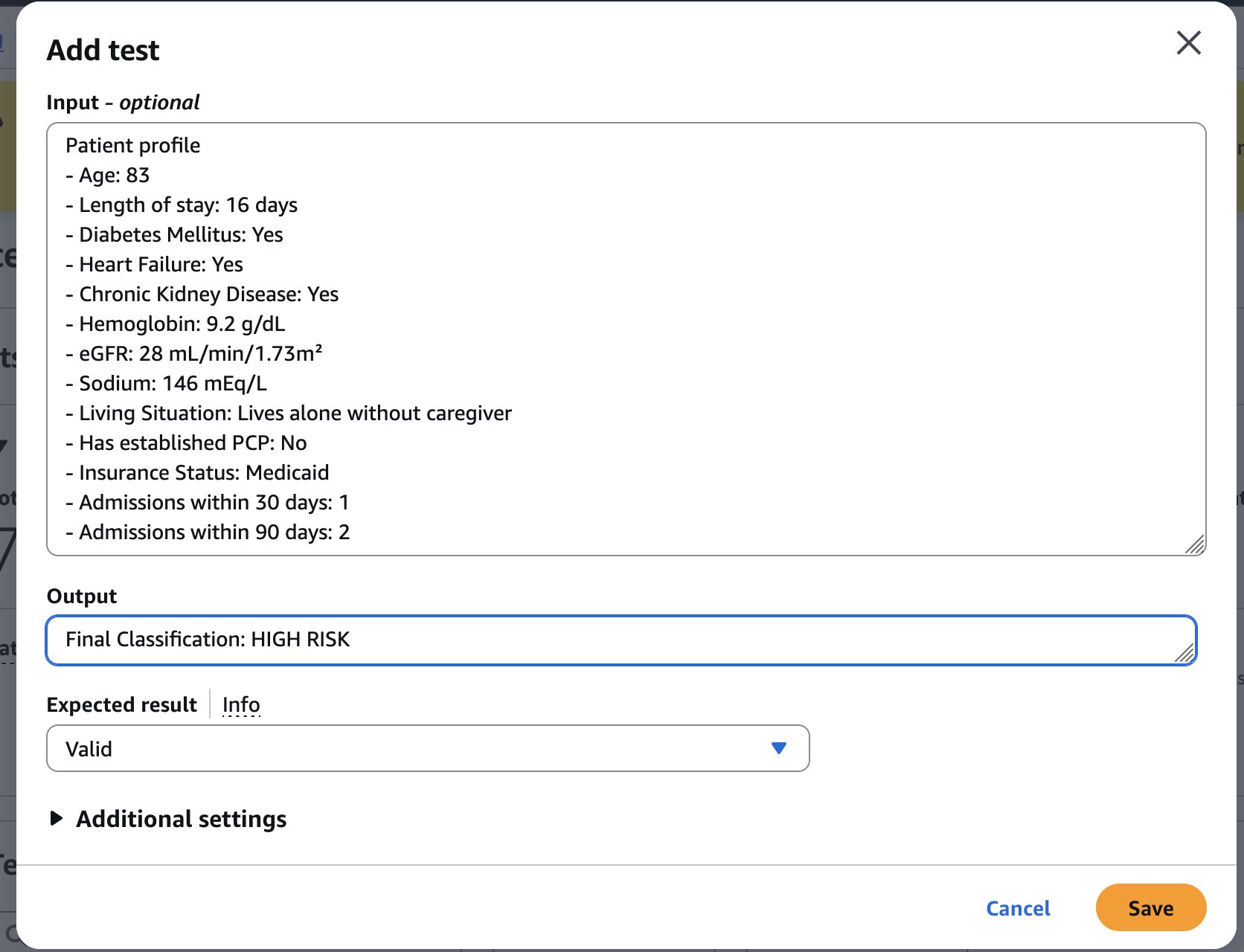
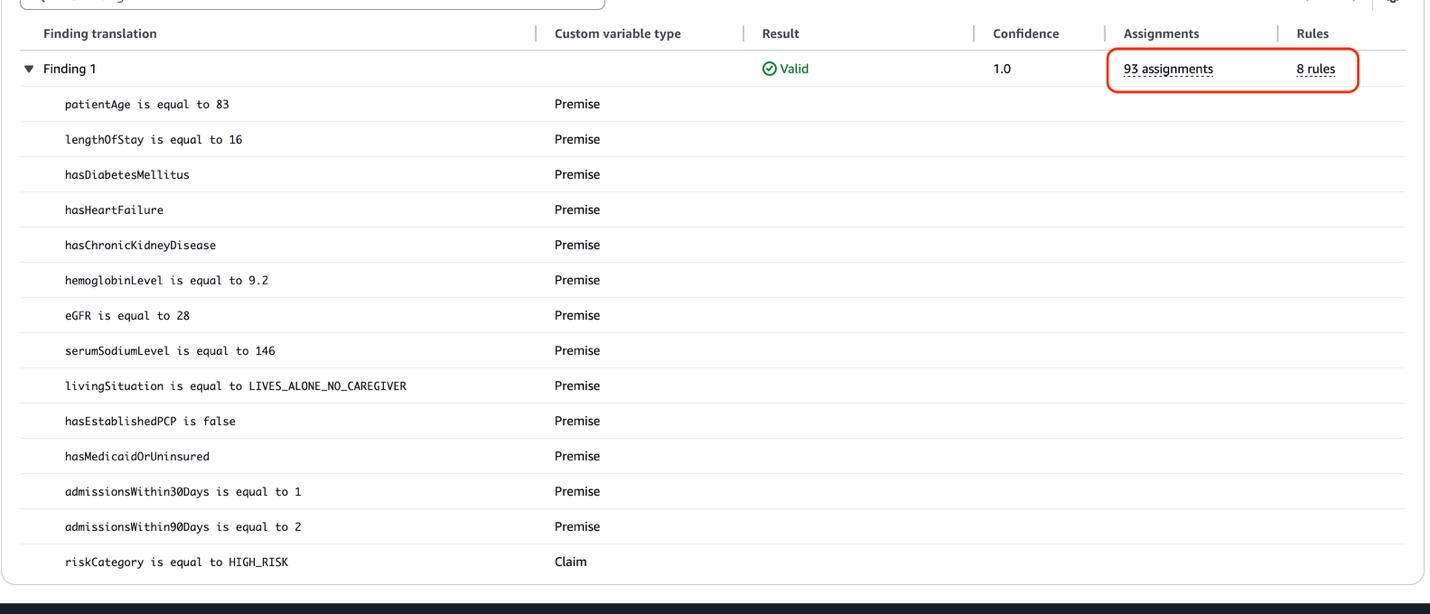
When this test is executed, we see that each of the patient details are extracted as premises, to validate the claim that the risk of readmission if high. We see that 8 rules have been applied to verify this claim. The key rules and their validations include:
- Age risk: Validates that patient age ≥ 80 contributes 3 risk points
- Length of stay risk: Confirms that stay >14 days adds 3 risk points
- Comorbidity risk: Calculated based on presence of Diabetes Mellitus, Heart Failure, Chronic Kidney Disease
- Utilization risk: Evaluates admissions history
- Laboratory risk: Evaluates risk based on Hemoglobin level of 9.2 and eGFR of 28
Each premise was evaluated as true, with multiple risk factors present (advanced age, extended stay, multiple comorbidities, concerning lab values, living alone without caregiver, and lack of PCP), supporting the overall Valid classification of this HIGH RISK assessment.
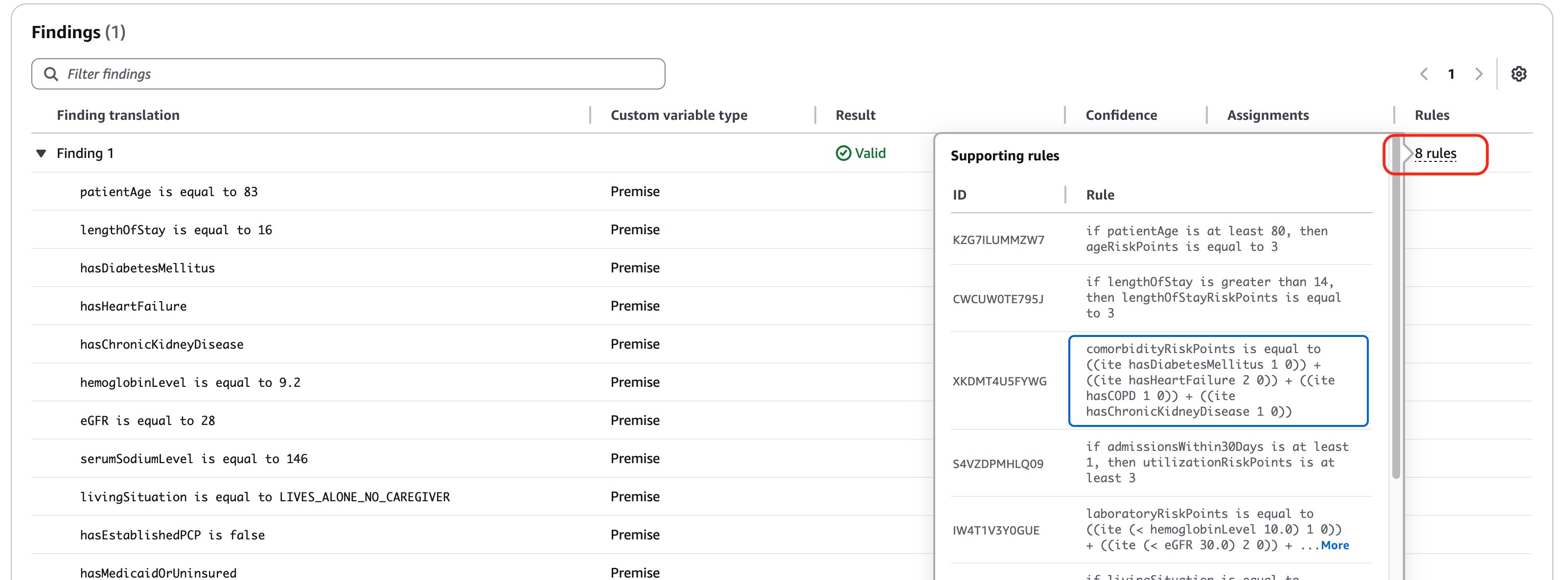
Moreover, the Automated Reasoning engine performed an extensive validation of this test sample using 93 different assignments to increase the soundness that the HIGH RISK classification is correct. Various related rules from the Automated Reasoning policy are used to validate the samples against 93 different scenarios and variable combinations. In this manner, Automated Reasoning checks confirms that there is no possible situation under which this patient’s HIGH RISK classification could be invalid. This thorough verification process affirms the reliability of the risk assessment for this elderly patient with multiple chronic conditions and complex care needs.In the event of a test sample failure, the 93 assignments would serve as an important diagnostic tool, pinpointing specific variables and their interactions that conflict with the expected outcome, thereby enabling subject matter experts (SMEs) to analyze the relevant rules and their relationships to determine if adjustments are needed in either the clinical logic or risk assessment criteria. In the next section, we will look at policy refinement and how SMEs can apply annotations to improve and correct the rules, variables, and custom types of the Automated Reasoning policy.
Policy refinement through annotations
Annotations provide a powerful improvement mechanism for Automated Reasoning policies when tests fail to produce expected results. Through annotations, SMEs can systematically refine policies by:
- Correcting problematic rules by modifying their logic or conditions
- Adding missing variables essential to the policy definition
- Updating variable descriptions for greater precision and clarity
- Resolving translation issues where original policy language was ambiguous
- Deleting redundant or conflicting elements from the policy
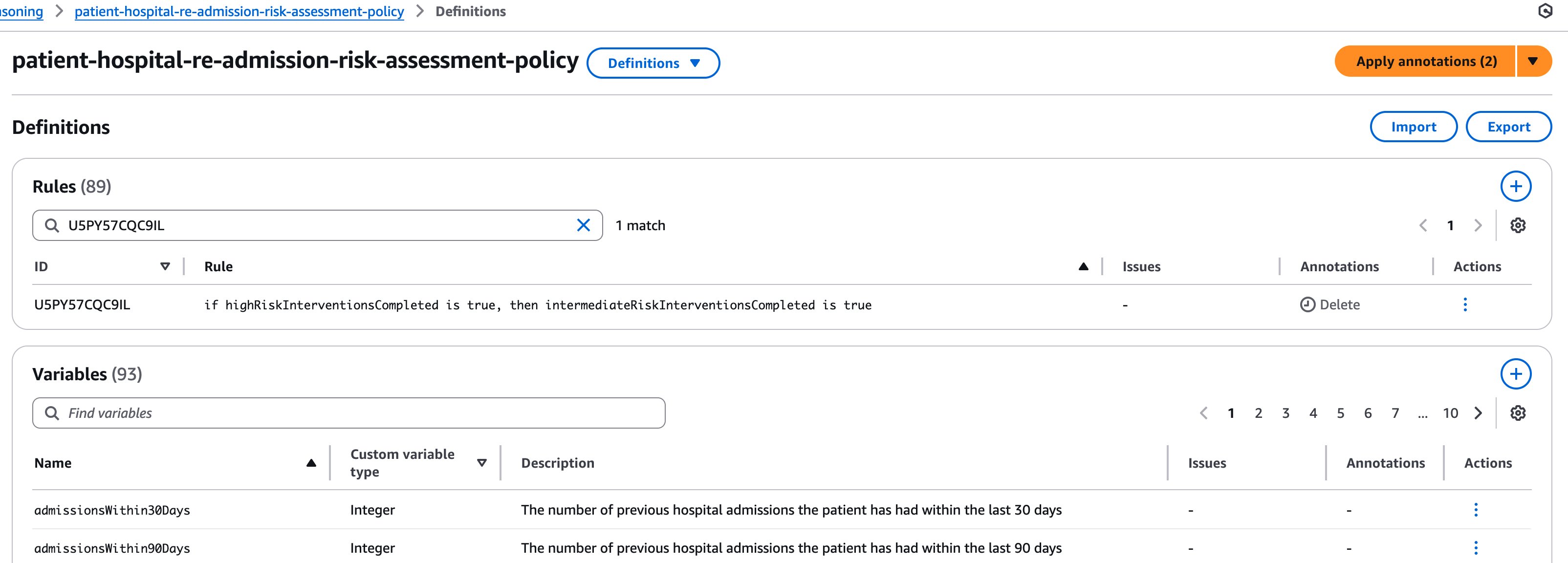
This iterative process of testing, annotating, and updating creates increasingly robust policies that accurately encode domain expertise. As shown in the figure below, annotations can be applied to modify various policy elements, after which the refined policy can be exported as a JSON file for deployment.
In the following figure, we can see how annotations are being applied, and rules are deleted in the policy. Similarly, additions and updates can be made to rules, variables, or the custom types.
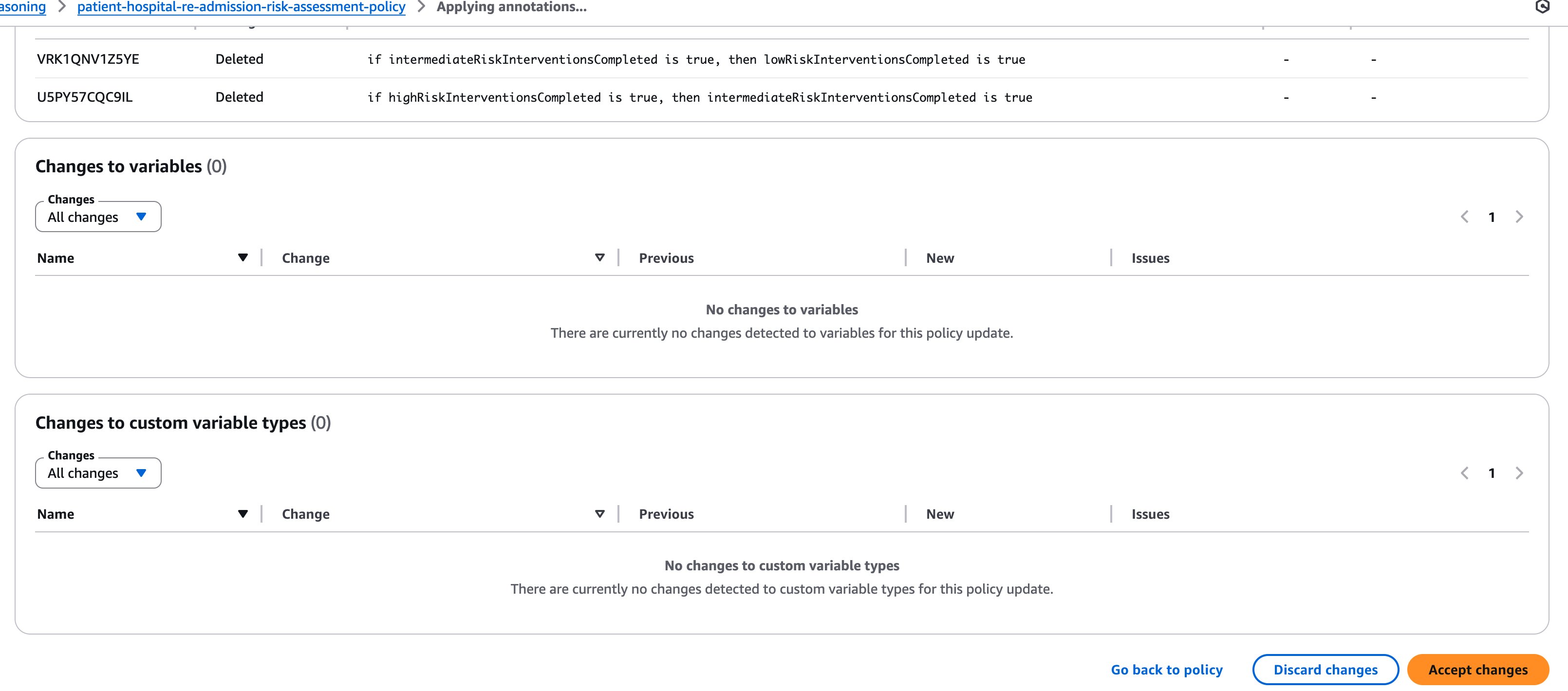
When the subject matter expert has validated the Automated Reasoning policy through testing, applying annotations, and validating the rules, it is possible to export the policy as a JSON file.
Using Automated Reasoning checks at inference
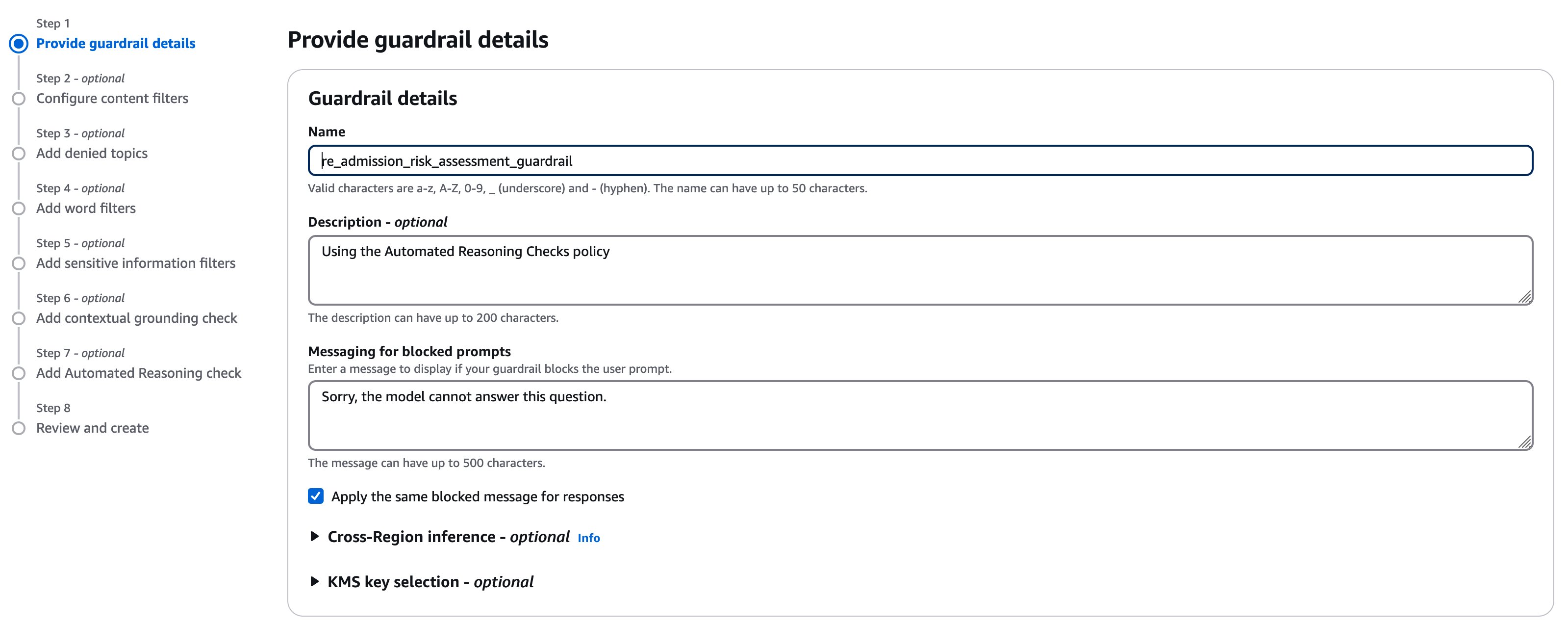
To use the Automated Reasoning checks with the created policy, we can now navigate to Amazon Bedrock Guardrails, and create a new guardrail by entering the name, description, and the messaging that will be displayed when the guardrail intervenes and blocks a prompt or a output from the AI system.
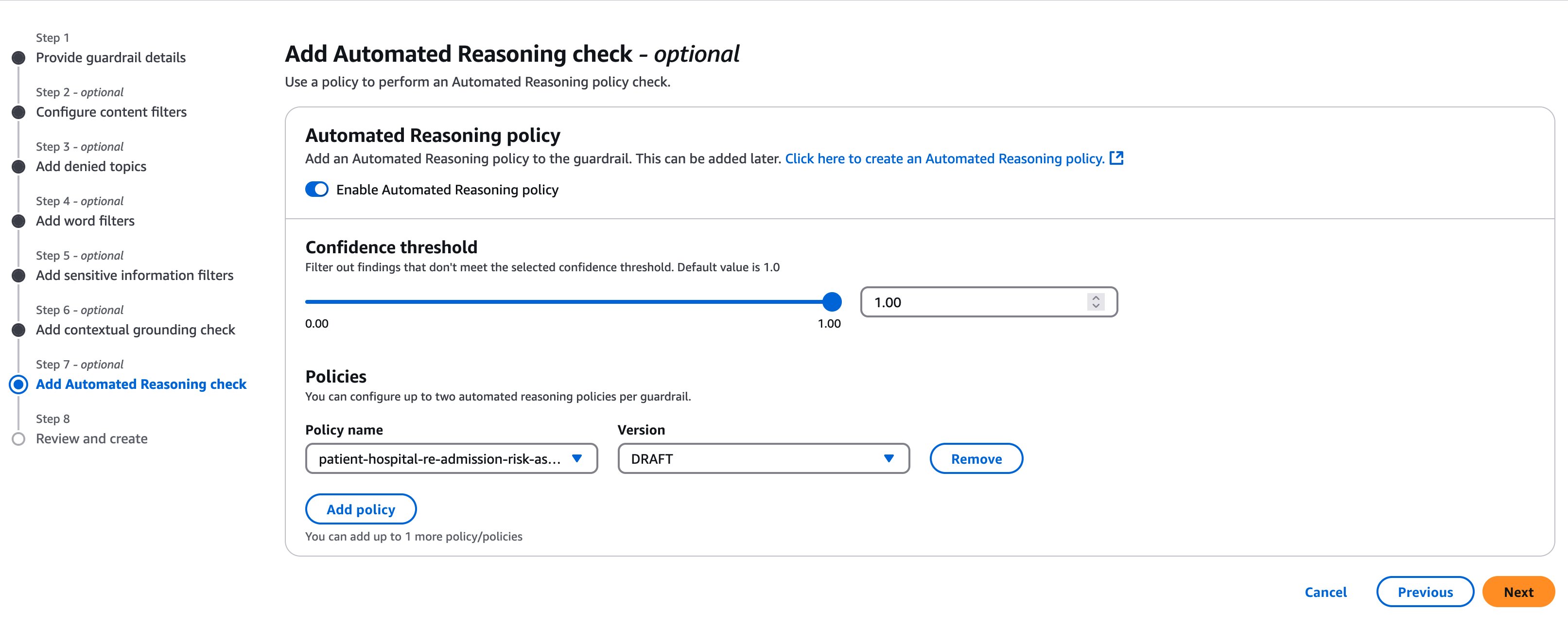
Now, we can attach Automated Reasoning check by using the toggle to Enable Automated Reasoning policy. We can set a confidence threshold, which determines how strictly the policy should be enforced. This threshold ranges from 0.00 to 1.00, with 1.00 being the default and most stringent setting. Each guardrail can accommodate up to two separate automated reasoning policies for enhanced validation flexibility. In the following figure, we are attaching the draft version of the medical policy related to patient hospital readmission risk assessment.
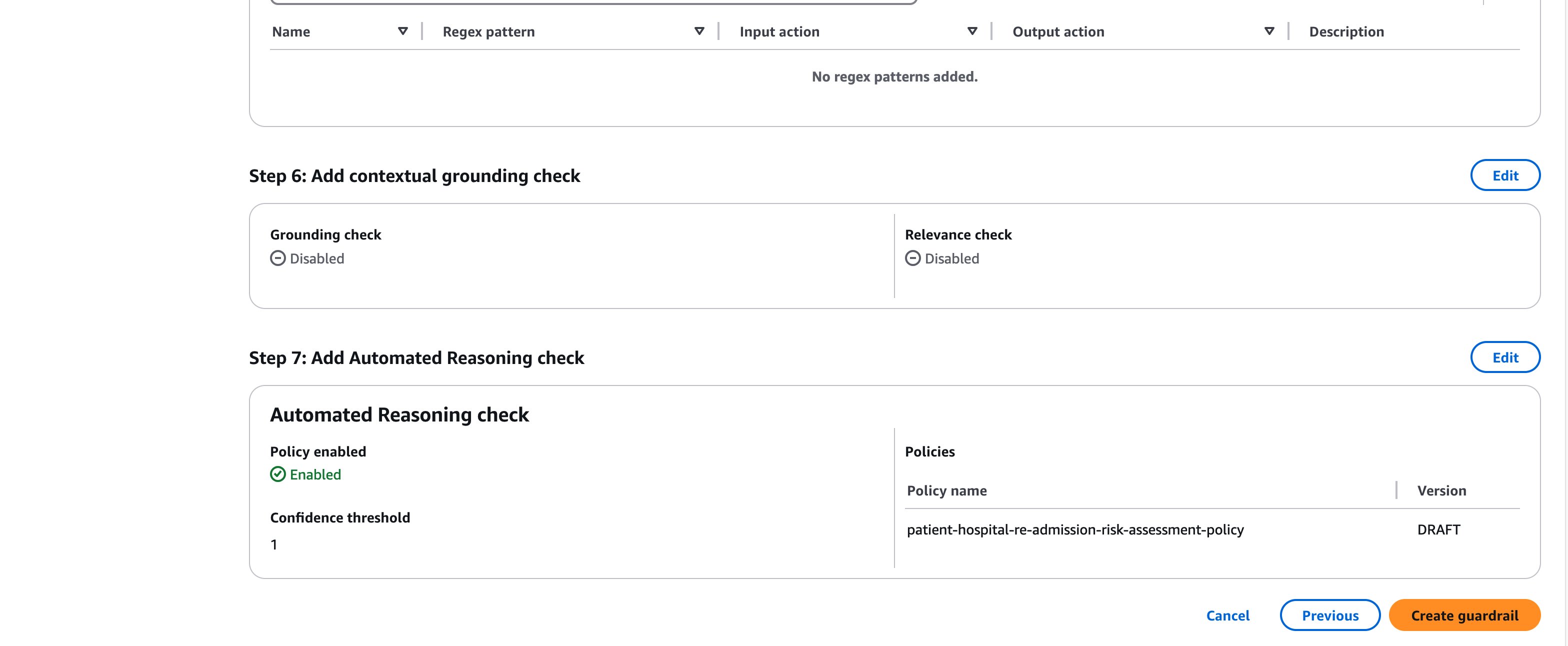
Now we can create the guardrail. Once you’ve established the guardrail and linked your automated reasoning policies, verify your setup by reviewing the guardrail details page to confirm all policies are properly attached.
Clean up
When you’re finished with your implementation, clean up your resources by deleting the guardrail and automated reasoning policies you created. Before deleting a guardrail, be sure to disassociate it from all resources or applications that use it.
Conclusion
In this first part of our blog, we explored how Automated Reasoning checks in Amazon Bedrock Guardrails help maintain the reliability and accuracy of generative AI applications through mathematical verification. You can use increased document processing capacity, advanced validation mechanisms, and comprehensive test management features to validate AI outputs against business rules and domain knowledge. This approach addresses key challenges facing enterprises deploying generative AI systems, particularly in regulated industries where factual accuracy and policy compliance are essential. Our hospital readmission risk assessment demonstration shows how this technology supports the validation of complex decision-making processes, helping transform generative AI into systems suitable for critical business environments. You can use these capabilities through both the AWS Management Console and APIs to establish quality control processes for your AI applications.
To learn more, and build secure and safe AI applications, see the technical documentation and the GitHub code samples, or access to the Amazon Bedrock console.
About the authors
 Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
 Bharathi Srinivasan is a Generative AI Data Scientist at the AWS Worldwide Specialist Organization. She works on developing solutions for Responsible AI, focusing on algorithmic fairness, veracity of large language models, and explainability. Bharathi guides internal teams and AWS customers on their responsible AI journey. She has presented her work at various learning conferences.
Bharathi Srinivasan is a Generative AI Data Scientist at the AWS Worldwide Specialist Organization. She works on developing solutions for Responsible AI, focusing on algorithmic fairness, veracity of large language models, and explainability. Bharathi guides internal teams and AWS customers on their responsible AI journey. She has presented her work at various learning conferences.
 Nafi Diallo is a Senior Automated Reasoning Architect at Amazon Web Services, where she advances innovations in AI safety and Automated Reasoning systems for generative AI applications. Her expertise is in formal verification methods, AI guardrails implementation, and helping global customers build trustworthy and compliant AI solutions at scale. She holds a PhD in Computer Science with research in automated program repair and formal verification, and an MS in Financial Mathematics from WPI.
Nafi Diallo is a Senior Automated Reasoning Architect at Amazon Web Services, where she advances innovations in AI safety and Automated Reasoning systems for generative AI applications. Her expertise is in formal verification methods, AI guardrails implementation, and helping global customers build trustworthy and compliant AI solutions at scale. She holds a PhD in Computer Science with research in automated program repair and formal verification, and an MS in Financial Mathematics from WPI.

