

Managing large photo collections presents significant challenges for organizations and individuals. Traditional approaches rely on manual tagging, basic metadata, and folder-based organization, which can become impractical when dealing with thousands of images containing multiple people and complex relationships. Intelligent photo search systems address these challenges by combining computer vision, graph databases, and natural language processing to transform how we discover and organize visual content. These systems capture not just who and what appears in photos, but the complex relationships and contexts that make them meaningful, enabling natural language queries and semantic discovery.
In this post, we show you how to build a comprehensive photo search system using the AWS Cloud Development Kit (AWS CDK) that integrates Amazon Rekognition for face and object detection, Amazon Neptune for relationship mapping, and Amazon Bedrock for AI-powered captioning. We demonstrate how these services work together to create a system that understands natural language queries like “Find all photos of grandparents with their grandchildren at birthday parties” or “Show me pictures of the family car during road trips.”
The key benefit is the ability to personalize and customize search focus on specific people, objects, or relationships while scaling to handle thousands of photos and complex family or organizational structures. Our approach demonstrates that integrating Amazon Neptune graph database capabilities with Amazon AI services enables natural language photo search that understands context and relationships, moving beyond simple metadata tagging to intelligent photo discovery. We showcase this through a complete serverless implementation that you can deploy and customize for your specific use case.
Solution overview
This section outlines the technical architecture and workflow of our intelligent photo search system. As illustrated in the following diagram, the solution uses serverless AWS services to create a scalable, cost-effective system that automatically processes photos and enables natural language search.
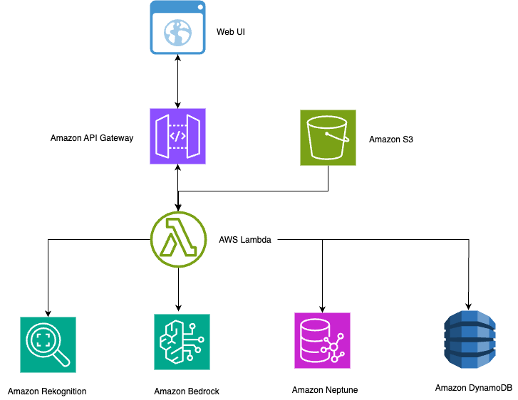
The serverless architecture scales efficiently for multiple use cases:
- Corporate – Employee recognition and event documentation
- Healthcare – HIPAA-compliant photo management with relationship tracking
- Education – Student and faculty photo organization across departments
- Events – Professional photography with automated tagging and client delivery
The architecture combines several AWS services to create a contextually aware photo search system:
- Amazon API Gateway for REST API endpoints and web interface integration
- Amazon Bedrock with Anthropic’s Claude 3.5 Sonnet for AI-powered contextual image captioning
- Amazon DynamoDB for fast metadata storage and retrieval
- AWS Lambda for serverless compute orchestration across solution components
- Amazon Neptune for storing complex relationships as a graph database
- Amazon Rekognition for face detection, recognition, and object labeling
- Amazon Simple Storage Service (Amazon S3) for scalable photo storage and triggering processing workflows
The system follows a streamlined workflow:
- Images are uploaded to S3 buckets with automatic Lambda triggers.
- Reference photos in the faces/ prefix are processed to build recognition models.
- New photos trigger Amazon Rekognition for face detection and object labeling.
- Neptune stores connections between people, objects, and contexts.
- Amazon Bedrock creates contextual descriptions using detected faces and relationships.
- DynamoDB stores searchable metadata with fast retrieval capabilities.
- Natural language queries traverse the Neptune graph for intelligent results.
The complete source code is available on GitHub.
Prerequisites
Before implementing this solution, ensure you have the following:
- An AWS account with appropriate permissions for Amazon S3, Lambda, Amazon Rekognition, Neptune, Amazon Bedrock, and DynamoDB
- The AWS Command Line Interface (AWS CLI) v2.15.0 or later configured with programmatic access
- The AWS CDK v2.92.0 or later installed (
npm install -g aws-cdk) - Python 3.11 or later with pip package manager
- Node.js 18.x or later for AWS CDK operations
- Basic knowledge of serverless architectures and graph databases
- Access to Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock in your AWS Region
Deploy the solution
Download the complete source code from the GitHub repository. More detailed setup and deployment instructions are available in the README.
The project is organized into several key directories that separate concerns and enable modular development:
The solution uses the following key Lambda functions:
- image_processor.py – Core processing with face recognition, label detection, and relationship-enriched caption generation
- search_handler.py – Natural language query processing with multi-step relationship traversal
- relationships_handler_neptune.py – Configuration-driven relationship management and graph connections
- label_relationships.py – Hierarchical label queries, object-person associations, and semantic discovery
To deploy the solution, complete the following steps:
- Run the following command to install dependencies:
pip install -r requirements_neptune.txt
- For a first-time setup, fun the following command to bootstrap the AWS CDK:
cdk bootstrap
- Run the following command to provision AWS resources:
cdk deploy
- Set up Amazon Cognito user pool credentials in the web UI.
- Upload reference photos to establish the recognition baseline.
- Create sample family relationships using the API or web UI.
The system automatically handles face recognition, label detection, relationship resolution, and AI caption generation through the serverless pipeline, enabling natural language queries like “person’s mother with car” powered by Neptune graph traversals.
Key features and use cases
In this section, we discuss the key features and use cases for this solution.
Automate face recognition and tagging
With Amazon Rekognition, you can automatically identify individuals from reference photos, without manual tagging. Upload a few clear images per person, and the system recognizes them across your entire collection, regardless of lighting or angles. This automation reduces tagging time from weeks to hours, supporting corporate directories, compliance archives, and event management workflows.
Enable relationship-aware search
By using Neptune, the solution understands who appears in photos and how they are connected. You can run natural language queries such as “Sarah’s manager” or “Mom with her children,” and the system traverses multi-hop relationships to return relevant images. This semantic search replaces manual folder sorting with intuitive, context-aware discovery.
Understand objects and context automatically
Amazon Rekognition detects objects, scenes, and activities, and Neptune links them to people and relationships. This enables complex queries like “executives with company vehicles” or “teachers in classrooms.” The label hierarchy is generated dynamically and adapts to different domains—such as healthcare or education—without manual configuration.
Generate context-aware captions with Amazon Bedrock
Using Amazon Bedrock, the system creates meaningful, relationship-aware captions such as “Sarah and her manager discussing quarterly results” instead of generic ones. Captions can be tuned for tone (such as objective for compliance, narrative for marketing, or concise for executive summaries), enhancing both searchability and communication.
Deliver an intuitive web experience
With the web UI, users can search photos using natural language, view AI-generated captions, and adjust tone dynamically. For example, queries like “mother with children” or “outdoor activities” return relevant, captioned results instantly. This unified experience supports both enterprise workflows and personal collections.
The following screenshot demonstrates using the web UI for intelligent photo search and caption styling.
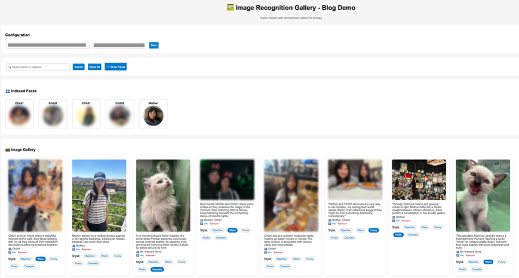
Scale graph relationships with label hierarchies
Neptune scales to model thousands of relationships and label hierarchies across organizations or datasets. Relationships are automatically generated during image processing, enabling fast semantic discovery while maintaining performance and flexibility as data grows.
The following diagram illustrates an example person relationship graph (configuration-driven).
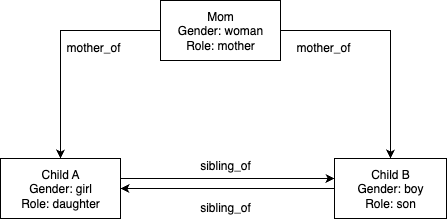
Person relationships are configured through JSON data structures passed to the initialize_relationship_data() function. This configuration-driven approach supports unlimited use cases without code modifications—you can simply define your people and relationships in the configuration object.
The following diagram illustrates an example label hierarchy graph (automatically generated from Amazon Rekognition).
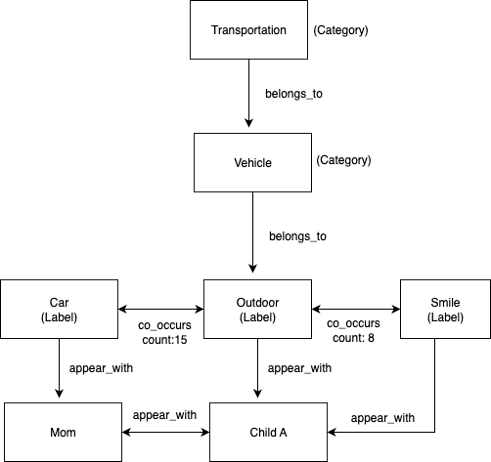
Label hierarchies and co-occurrence patterns are automatically generated during image processing. Amazon Rekognition provides category classifications that create the belongs_to relationships, and the appears_with and co_occurs_with relationships are built dynamically as images are processed.
The following screenshot illustrates a subset of the complete graph, demonstrating multi-layered relationship types.
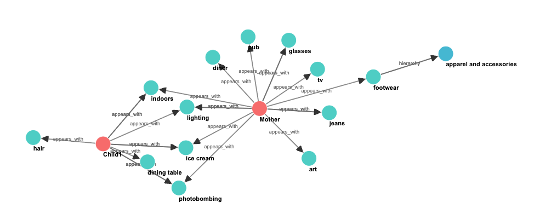
Database generation methods
The relationship graph uses a flexible configuration-driven approach through the initialize_relationship_data() function. This mitigates the need for hard-coding and supports unlimited use cases:
The label relationship database is created automatically during image processing through the store_labels_in_neptune() function:
With these functions, you can manage large photo collections with complex relationship queries, discover photos by semantic context, and find themed collections through label co-occurrence patterns.
Performance and scalability considerations
Consider the following performance and scalability factors:
- Handling bulk uploads – The system processes large photo collections efficiently, from small family albums to enterprise archives with thousands of images. Built-in intelligence manages API rate limits and facilitates reliable processing even during peak upload periods.
- Cost optimization – The serverless architecture makes sure you only pay for actual usage, making it cost-effective for both small teams and large enterprises. For reference, processing 1,000 images typically costs approximately $15–25 (including Amazon Rekognition face detection, Amazon Bedrock caption generation, and Lambda function execution), with Neptune cluster costs of $100–150 monthly regardless of volume. Storage costs remain minimal at under $1 per 1,000 images in Amazon S3.
- Scaling performance – The Neptune graph database approach scales efficiently from small family structures to enterprise-scale networks with thousands of people. The system maintains fast response times for relationship queries and supports bulk processing of large photo collections with automatic retry logic and progress tracking.
Security and privacy
This solution implements comprehensive security measures to protect sensitive image and facial recognition data. The system encrypts data at rest using AES-256 encryption with AWS Key Management Service (AWS KMS) managed keys and secures data in transit with TLS 1.2 or later. Neptune and Lambda functions operate within virtual private cloud (VPC) subnets, isolated from direct internet access, and API Gateway provides the only public endpoint with CORS policies and rate limiting. Access control follows least-privilege principles with AWS Identity and Access Management (IAM) policies that grant only minimum required permissions: Lambda functions can only access specific S3 buckets and DynamoDB tables, and Neptune access is restricted to authorized database operations. Image and facial recognition data stays within your AWS account and is never shared outside AWS services. You can configure Amazon S3 lifecycle policies for automated data retention management, and AWS CloudTrail provides complete audit logs of data access and API calls for compliance monitoring, supporting GDPR and HIPAA requirements with additional Amazon GuardDuty monitoring for threat detection.
Clean up
To avoid incurring future charges, complete the following steps to delete the resources you created:
- Delete images from the S3 bucket:
aws s3 rm s3://YOUR_BUCKET_NAME –recursive
- Delete the Neptune cluster (this command also automatically deletes Lambda functions):
cdk destroy
- Remove the Amazon Rekognition face collection:
aws rekognition delete-collection --collection-id face-collection
Conclusion
This solution demonstrates how Amazon Rekognition, Amazon Neptune, and Amazon Bedrock can work together to enable intelligent photo search that understands both visual content and context. Built on a fully serverless architecture, it combines computer vision, graph modeling, and natural language understanding to deliver scalable, human-like discovery experiences. By turning photo collections into a knowledge graph of people, objects, and moments, it redefines how users interact with visual data—making search more semantic, relational, and meaningful. Ultimately, it reflects the reliability and trustworthiness of AWS AI and graph technologies in enabling secure, context-aware photo understanding.
To learn more, refer to the following resources:
- AWS CDK Documentation
- Amazon Rekognition Developer Guide
- Amazon Neptune User Guide
- Amazon Bedrock User Guide


