

Our work with large enterprise customers and Amazon teams has revealed that high stakes use cases continue to benefit significantly from advanced large language model (LLM) fine-tuning and post-training techniques. In this post, we show you how fine-tuning enabled a 33% reduction in dangerous medication errors (Amazon Pharmacy), engineering 80% human effort reduction (Amazon Global Engineering Services), and content quality assessments improving 77% to 96% accuracy (Amazon A+). These aren’t hypothetical projections—they’re production results from Amazon teams. While many use cases can be effectively addressed through prompt engineering, Retrieval Augmented Generation (RAG) systems, and turn key agent deployment,, our work with Amazon and large enterprise accounts reveals a consistent pattern: One in four high-stakes applications—where patient safety, operational efficiency, or customer trust are on the line—demand advanced fine-tuning and post-training techniques to achieve production-grade performance.
This post details the techniques behind these outcomes: from foundational methods like Supervised Fine-Tuning (SFT) (instruction tuning), and Proximal Policy Optimization (PPO), to Direct Preference Optimization (DPO) for human alignment, to cutting-edge reasoning optimizations such as Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO) purpose-built for agentic systems. We walk through the technical evolution of each approach, examine real-world implementations at Amazon, present a reference architecture on Amazon Web Services (AWS), and provide a decision framework for selecting the right technique based on your use case requirements.
The continued relevance of fine-tuning in the agentic AI
Despite the growing capabilities of foundation models and agent frameworks, roughly one of four enterprise use cases still require advanced fine-tuning to achieve the necessary performance levels. These are typically scenarios where the stakes are high from revenue or customer trust perspectives, domain-specific knowledge is essential, enterprise integration at scale is required, governance and control are paramount, business process integration is complex, or multi-modal support is needed. Organizations pursuing these use cases have reported higher conversion to production, greater return on investment (ROI), and up to 3-fold year-over-year growth when advanced fine-tuning is appropriately applied.
Evolution of LLM fine-tuning techniques for agentic AI
The evolution of generative AI has seen several key advancements in model customization and performance optimization techniques. Starting with SFT, which uses labeled data to teach models to follow specific instructions, the field established its foundation but faced limitations in optimizing complex reasoning. To address these limitations, reinforcement learning (RL) refines the SFT process with a reward-based system that provides better adaptability and alignment with human preference. Among multiple RL algorithms, a significant leap comes with PPO, which consists of a workflow with a value (critic) network and a policy network. The workflow contains a reinforcement learning policy to adjust the LLM weights based on the guidance of a reward model. PPO scales well in complex environments, though it has challenges with stability and configuration complexity.
DPO emerged as a breakthrough in early 2024, addressing PPO’s stability issues by eliminating the explicit reward model and instead working directly with preference data that includes preferred and rejected responses for given prompts. DPO optimizes the LLM weights by comparing the preferred and rejected responses, allowing the LLM to learn and adjust its behavior accordingly. This simplified approach gained widespread adoption, with major language models incorporating DPO into their training pipelines to achieve better performance and more reliable outputs. Other alternatives including Odds Ratio Policy Optimization (ORPO), Relative Preference Optimization (RPO), Identity preference optimization (IPO), Kahneman-Tversky Optimization (KTO), they are all RL methods for human preference alignment. By incorporating comparative and identity-based preference structures, and grounding optimization in behavioral economics, these methods are computationally efficient, interpretable, and aligned with actual human decision-making processes.
As agent-based applications gained prominence in 2025, we observed increasing demands for customizing the reasoning model in agents, to encode domain-specific constraints, safety guidelines, and reasoning patterns that align with agents’ intended functions (task planning, tool use, or multi-step problem solving). The objective is to improve agents’ performance in maintaining coherent plans, avoiding logical contradictions, and making appropriate decisions for the domain specific use cases. To meet these needs, GRPO was introduced to enhance reasoning capabilities and became particularly notable for its implementation in DeepSeek-V1.
The core innovation of GRPO lies in its group-based comparison approach: rather than comparing individual responses against a fixed reference, GRPO generates groups of responses and evaluates each against the average score of the group, rewarding those performing above average while penalizing those below. This relative comparison mechanism creates a competitive dynamic that encourages the model to produce higher-quality reasoning. GRPO is particularly effective for improving chain-of-thought (CoT) reasoning, which is the critical foundation for agent planning and complex task decomposition. By optimizing at the group level, GRPO captures the inherent variability in reasoning processes and trains the model to consistently outperform its own average performance.
Some complex agent tasks might require more fine-grained and crisp corrections within long reasoning chains, DAPO addresses these use cases by building upon GRPO sequence-level rewards, employing a higher clip ratio (approximately 30% higher than GRPO) to encourage more diverse and exploratory thinking processes, implementing dynamic sampling to eliminate less meaningful samples and improve overall training efficiency, applying token-level policy gradient loss to provide more granular feedback on lengthy reasoning chains rather than treating entire sequences as monolithic units, and incorporating overlong reward shaping to discourage excessively verbose responses that waste computational resources. Additionally, when the agentic use cases require long text outputs in the Mixture-of-Experts (MoE) model training, GSPO supports these scenarios by shifting the optimization from GRPO’s token-level importance weights to the sequence level. With these improvements, the new methods (DAPO and GSPO) enable more efficient and sophisticated agent reasoning and planning strategy, while maintaining computational efficiency and appropriate feedback resolution of GRPO.
Real-world applications at Amazon
Using the fine-tuning techniques described in the previous sections, the post-trained LLMs play two crucial roles in agentic AI systems. First is in the development of specialized tool-using components and sub-agents within the broader agent architecture. These fine-tuned models act as domain experts, each optimized for specific functions. By incorporating domain-specific knowledge and constraints during the fine-tuning process, these specialized components can achieve significantly higher accuracy and reliability in their designated tasks compared to general-purpose models. The second key application is to serve as the core reasoning engine, where the foundation models are specifically tuned to excel at planning, logical reasoning, and decision-making, for agents in a highly specific domain. The aim is to improve the model’s ability to maintain coherent plans and make logically sound decisions—essential capabilities for any agent system. This dual approach, combining a fine-tuned reasoning core with specialized sub-components, was emerging as a promising architecture in Amazon for evolving from LLM-driven applications to agentic systems, and building more capable and reliable generative AI applications. The following table depicts multi-agent AI orchestration with of advanced fine-tuning technique examples.
| Amazon Pharmacy | Amazon Global Engineering Services | Amazon A+ Content | |
|---|---|---|---|
| Domain | Healthcare | Construction and facilities | Ecommerce |
| High-stakes factor | Patient safety | Operational efficiency | Customer trust |
| Challenge | $3.5 B annual cost from medication errors | 3+ hour inspection reviews | Quality assessment at 100 million+ scale |
| Techniques | SFT, PPO, RLHF, advanced RL | SFT, PPO, RLHF, advanced RL | Feature-based fine-tuning |
| Key outcome | 33% reduction in medication errors | 80% reduction in human effort | 77%–96% accuracy |
Amazon Healthcare Services (AHS) began its journey with generative AI with a significant challenge two years ago, when the team tackled customer service efficiency through a RAG-based Q&A system. Initial attempts using traditional RAG with foundation models yielded disappointing results, with accuracy hovering between 60 and 70%. The breakthrough came when they fine-tuned the embedding model specifically for pharmaceutical domain knowledge, resulted in a significant improvement to 90% accuracy and an 11% reduction in customer support contacts. In medication safety, medication direction errors can pose serious safety risks and cost up to $3.5 billion annually to correct. By fine-tuning a model with thousands of expert-annotated examples, Amazon Pharmacy created an agent component that validates medication directions using pharmacy logic and safety guidelines. This reduced near-miss events by 33%, as indicated in their Nature Medicine publication. In 2025, AHS is expanding their AI capabilities and transform these separate LLM-driven applications into a holistic multi-agent system to enhance patient experience. These individual applications driven by fine-tuned models play a crucial role in the overall agentic architecture, serving as domain expert tools to address specific mission-critical functions in pharmaceutical services.
The Amazon Global Engineering Services (GES) team, responsible for overseeing hundreds of Amazon fulfillment centers worldwide, embarked on an ambitious journey to use generative AI in their operations. Their initial foray into this technology focused on creating a sophisticated Q&A system designed to assist engineers in efficiently accessing relevant design information from vast knowledge repositories. The team’s approach was fine-tuning a foundation model using SFT, which resulted in a significant improvement in accuracy (measured by semantic similarity score) from 0.64 to 0.81. To better align with the feedback from the subject matter experts (SMEs), the team further refined the model using PPO incorporating the human feedback data, which boosted the LLM-judge scores from 3.9 to 4.2 out of 5, a remarkable achievement that translated to a substantial 80% reduction in the effort required from the domain experts. Similar to the Amazon Pharmacy case, these fine-tuned specialized models will continue to function as domain expert tools within the broader agentic AI system.
In 2025, the GES team ventured into uncharted territory by applying agentic AI systems to optimize their business process. LLM fine-tuning methodologies constitute a critical mechanism for enhancing the reasoning capabilities in AI agents, enabling effective decomposition of complex objectives into executable action sequences that align with predefined behavioral constraints and goal-oriented outcomes. It also serves as critical architecture component in facilitating specialized task execution and optimizing for task-specific performance metrics.
Amazon A+ Content powers rich product pages across hundreds of millions of annual submissions. The A+ team needed to evaluate content quality at scale—assessing cohesiveness, consistency, and relevancy, not just surface-level defects. Content quality directly impacts conversion and brand trust, making this a high-stakes application.
Following the architectural pattern seen in Amazon Pharmacy and Global Engineering Services, the team built a specialized evaluation agent powered by a fine-tuned model. They applied feature-based fine-tuning to Nova Lite on Amazon SageMaker—training a lightweight classifier on vision language model (VLM)-extracted features rather than updating full model parameters. This approach, enhanced by expert-crafted rubric prompts, improved classification accuracy from 77% to 96%. The result: an AI agent that evaluates millions of content submissions and delivers actionable recommendations. This demonstrates a key principle from our maturity framework—technique complexity should match task requirements. The A+ use case, while high-stakes and operating at massive scale, is fundamentally a classification task well-suited to these methods. Not every agent component requires GRPO or DAPO; selecting the right technique for each problem is what delivers efficient, production-grade systems.
Reference architecture for advanced AI orchestration using fine-tuning
Although fine-tuned models serve diverse purposes across different domains and use cases in an agentic AI system, the anatomy of an agent remains largely consistent and can be encompassed in component groupings, as shown in the following architecture diagram.
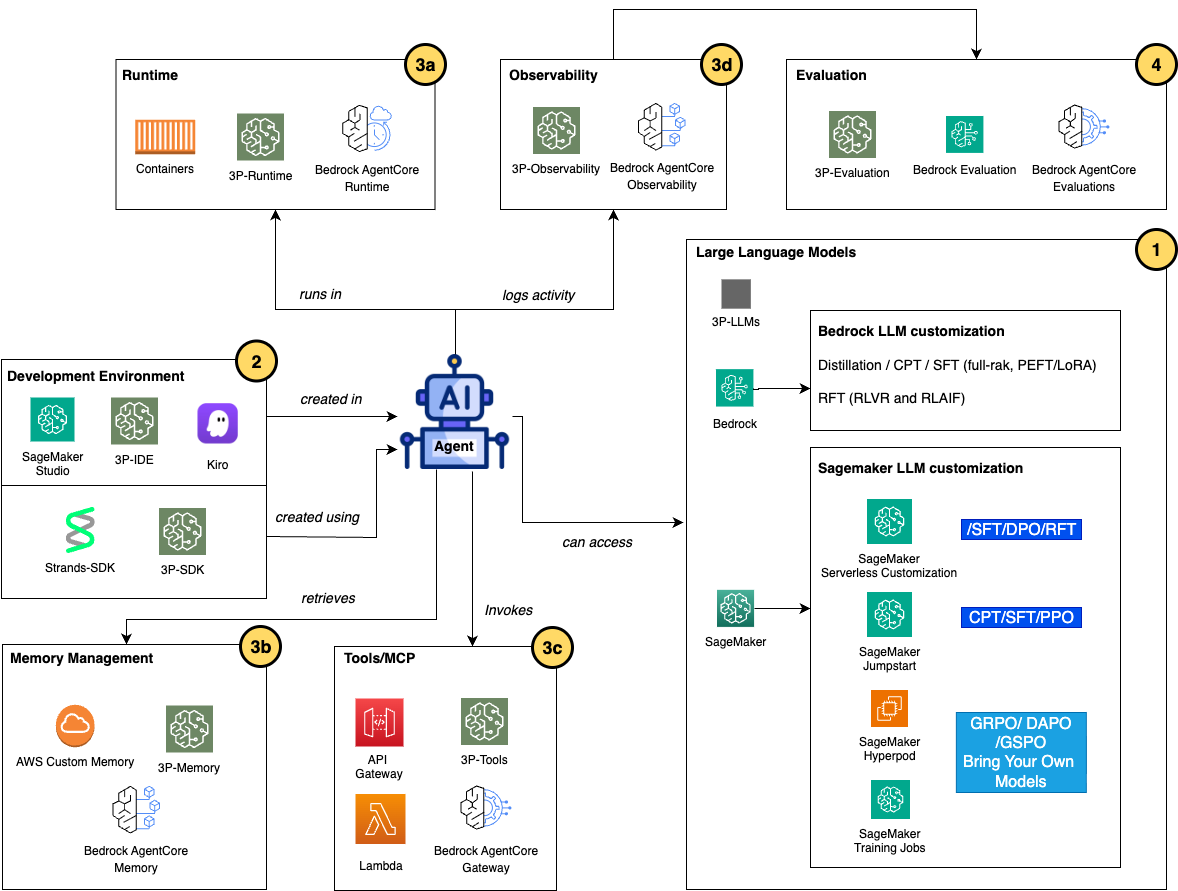
This modular approach adopts a number of AWS generative AI services, including Amazon Bedrock AgentCore, Amazon SageMaker, and Amazon Bedrock, that maintains structure of key groupings that make up an agent while providing various options within each group to improve an AI agent.
- LLM customization for AI agents
Builders can use various AWS services to fine-tune and post-train the LLMs for an AI agent using the techniques discussed in the previous section. If you use LLMs on Amazon Bedrock for your agents, you can use multiple model customization approaches to fine-tune your models. Distillation and SFT through parameter-efficient fine-tuning (PEFT) with low-rank adaptation (LoRA) can be used to address simple customization tasks. For advanced fine-tuning, Continued Pre-training (CPT) extends a foundation model’s knowledge by training on domain-specific corpora (medical literature, legal documents, or proprietary technical content), embedding specialized vocabulary and domain reasoning patterns directly into model weights. Reinforcement fine-tuning (RFT), launched at re:Invent 2025, teaches models to understand what makes a quality response without large amounts of pre-labeled training data. There are two approaches supported for RFT: Reinforcement Learning with Verifiable Rewards (RLVR) uses rule-based graders for objective tasks like code generation or math reasoning, while Reinforcement Learning from AI Feedback (RLAIF) uses AI-based judges for subjective tasks like instruction following or content moderation.
If you require deeper control over model customization infrastructure for your AI agents, Amazon SageMaker AI provides a comprehensive platform for custom model development and fine-tuning. Amazon SageMaker JumpStart accelerates the customization journey by offering pre-built solutions with one-click deployment of popular foundation models (Llama, Mistral, Falcon, and others) and end-to-end fine-tuning notebooks that handle data preparation, training configuration, and deployment workflows. Amazon SageMaker Training jobs provide managed infrastructure for executing custom fine-tuning workflows, automatically provisioning GPU instances, managing training execution, and handling cleanup after completion. This approach suits most fine-tuning scenarios where standard instance configurations provide sufficient compute power and training completes reliably within the job duration limits. You can use SageMaker Training jobs with custom Docker containers and code dependencies housing any machine learning (ML) framework, training library, or optimization technique, enabling experimentation with emerging methods beyond managed offerings.
At re:Invent 2025, Amazon SageMaker HyperPod introduced two capabilities for large-scale model customization: Checkpointless training reduces checkpoint-restart cycles, shortening recovery time from hours to minutes. Elastic training automatically scales workloads to use idle capacity and yields resources when higher-priority workloads peak. These features build on the core strengths of HyperPod—resilient distributed training clusters with automatic fault recovery for multi-week jobs spanning thousands of GPUs. HyperPod supports NVIDIA NeMo and AWS Neuronx frameworks, and is ideal when training scale, duration, or reliability requirements exceed what job-based infrastructure can economically provide.
In SageMaker AI, for builders who want to customize models without managing infrastructure, Amazon SageMaker AI serverless customization, launched at re:Invent 2025, provides a fully managed, UI- and SDK-driven experience for model fine-tuning. This capability provides infrastructure management—SageMaker automatically selects and provisions appropriate compute resources (P5, P4de, P4d, and G5 instances) based on model size and training requirements. Through the SageMaker Studio UI, you can customize popular models (Amazon Nova, Llama, DeepSeek, GPT-OSS, and Qwen) using advanced techniques including SFT, DPO, RLVR, and RLAIF. You can also run the same serverless customization using SageMaker Python SDK in your Jupyter notebook. The serverless approach provides pay-per-token pricing, automatic resource cleanup, integrated MLflow experiment tracking, and seamless deployment to both Amazon Bedrock and SageMaker endpoints.
If you need to customize Amazon Nova models for your agentic workflow, you can do it through recipes and train them on SageMaker AI. It provides end-to-end customization workflow including model training, evaluation, and deployment for inference. with greater flexibility and control to fine-tune the Nova models, optimize hyperparameters with precision, and implement techniques such as LoRA PEFT, full-rank SFT, DPO, RFT, CPT, PPO, and so on. For the Nova models on Amazon Bedrock, you can also train your Nova models by SFT and RFT with reasoning content to capture intermediate thinking steps or use reward-based optimization when exact correct answers are difficult to define. If you have more advanced agentic use cases that require deeper model customization, you can use Amazon Nova Forge—launched at re:Invent 2025—to build your own frontier models from early model checkpoints, blend your datasets with Amazon Nova-curated training data, and host your custom models securely on AWS.
- AI agent development environments and SDKs
The development environment is where developers author, test, and iterate on agent logic before deployment. Developers use integrated development environments (IDEs) such as SageMaker AI Studio (Jupyter Notebooks compared to code editors), Amazon Kiro, or IDEs on local machines like PyCharm. Agent logic is implemented using specialized SDKs and frameworks that abstract orchestration complexity—Strands provides a Python framework purpose-built for multi-agent systems, offering declarative agent definitions, built-in state management, and native AWS service integrations that handle the low-level details of LLM API calls, tool invocation protocols, error recovery, and conversation management. With these development tools handling the low-level details of LLM API calls, developers can focus on business logic rather than infrastructure design and maintenance.
- AI agent deployment and operation
After your AI agent development is completed and ready to deploy in production, you can use Amazon Bedrock AgentCore to handle agent execution, memory, security, and tool integration without requiring infrastructure management. Bedrock AgentCore provides a set of integrated services, including:
-
- AgentCore Runtime offers purpose-built environments that abstract away infrastructure management, while container-based alternatives (SageMaker AI jobs, AWS Lambda, Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon Elastic Container Service (Amazon ECS)) provide more control for custom requirements. Essentially, the runtime is where your carefully crafted agent code meets real users and delivers business value at scale.
- AgentCore Memory gives your AI agents the ability to remember past interactions, enabling them to provide more intelligent, context-aware, and personalized conversations. It provides a straightforward and powerful way to handle both short-term context and long-term knowledge retention without the need to build or manage complex infrastructure.
- With AgentCore Gateway, developers can build, deploy, discover, and connect to tools at scale, providing observability into tool usage patterns, error handling for failed invocations, and integration with identity systems for accessing tools on behalf of users (using OAuth or API keys). Teams can update tool backends, add new capabilities, or modify authentication requirements without redeploying agents because the gateway architecture decouples tool implementation from agent logic—maintaining flexibility as business requirements evolve.
- AgentCore Observability helps you trace, debug, and monitor agent performance in production environments. It provides real-time visibility into agent operational performance through access to dashboards powered by Amazon CloudWatch and telemetry for key metrics such as session count, latency, duration, token usage, and error rates, using the OpenTelemetry (OTEL) protocol standard.
- LLM and AI agent evaluation
When your fine-tuned LLM driven AI agents are running in production, it’s important to evaluate and monitor your models and agents continuously to ensure high quality and performance. Many enterprise use cases require custom evaluation criteria that encode domain expertise and business rules. For the Amazon Pharmacy medication direction validation process, evaluation criteria include: drug-drug interaction detection accuracy (percentage of known contraindications correctly identified), dosage calculation precision (correct dosing adjustments for age, weight, and renal function), near-miss prevention rate (reduction in medication errors that could cause patient harm), FDA labeling compliance (adherence to approved usage, warnings, and contraindications), and pharmacist override rate (percentage of agent recommendations accepted without modification by licensed pharmacists).
For your models on Amazon Bedrock, you can use Amazon Bedrock evaluations to generate predefined metrics and human review workflows. For advanced scenarios, you can use SageMaker Training jobs to fine-tune specialized judge models on domain-specific evaluation datasets. For holistic AI agent evaluation, AgentCore Evaluations, launched at re:Invent 2025, provides automated assessment tools to measure your agent or tools performance on completing specific tasks, handling edge cases, and maintaining consistency across different inputs and contexts.
Decision guide and recommended phased approach
Now that you understand the technical evolution of advanced fine-tuning techniques—from SFT to PPO, DPO, GRPO, DAPO and GSPO—the critical question becomes when and why you should use them. Our experience shows that organizations using a phased maturity approach achieve 70–85% production conversion rates (compared to the 30–40% industry average) and 3-fold year-over-year ROI growth. The 12–18 month journey from initial agent deployment to advanced reasoning capabilities delivers incremental business value at each phase. The key is letting your use case requirements, available data, and measured performance guide advancement—not technical sophistication for its own sake.
The maturity path progresses through four phases (shown in the following table). Strategic patience in this progression builds reusable infrastructure, collects quality training data, and validates ROI before major investments. As our examples demonstrate, aligning technical sophistication with human and business needs delivers transformative outcomes and sustainable competitive advantages in your most critical AI applications.
| Phase | Timeline | When to use | Key outcomes | Data needed | Investment |
| Phase 1: Prompt engineering | 6–8 weeks |
|
|
Minimal prompts, examples | $50K–$80K (2–3 full-time employees (FTE)) |
| Phase 2: Supervised Fine-Tuning (SFT) | 12 weeks |
|
|
500–5,000 labeled examples | $120K–$180K (3–4 FTE and compute) |
| Phase 3: Direct Preference Optimization (DPO) | 16 weeks |
|
|
1,000–10,000 preference pairs | $180K–$280K (4–5 FTE and compute) |
| Phase 4: GRPO and DAPO | 24 weeks |
|
|
10,000+ reasoning trajectories | $400K-$800K (6–8 FTE and HyperPod) |
Conclusion
While agents have transformed how we build AI systems, advanced fine-tuning remains a critical component for enterprises seeking competitive advantage in high-stakes domains. By understanding the evolution of techniques like PPO, DPO, GRPO, DAPO and GSPO, and applying them strategically within agent architectures, organizations can achieve significant improvements in accuracy, efficiency, and safety. The real-world examples from Amazon demonstrate –that the combination of agentic workflows with carefully fine-tuned models delivers dramatic business outcomes.
AWS continues to accelerate these capabilities with several key launches at re:Invent 2025. Reinforcement fine-tuning (RFT) on Amazon Bedrock now enables models to learn quality responses through RLVR for objective tasks and RLAIF for subjective evaluations—without requiring large amounts of pre-labeled data. Amazon SageMaker AI Serverless Customization eliminates infrastructure management for fine-tuning, supporting SFT, DPO, and RLVR techniques with pay-per-token pricing. For large-scale training, Amazon SageMaker HyperPod introduced checkpointless training and elastic scaling to reduce recovery time and optimize resource utilization. Amazon Nova Forge empowers enterprises to build custom frontier models from early checkpoints, blending proprietary datasets with Amazon-curated training data. Finally, AgentCore Evaluation provides automated assessment tools to measure agent performance on task completion, edge cases, and consistency—closing the loop on production-grade agentic AI systems.
As you evaluate your generative AI strategy, use the decision guide and phased maturity approach outlined in this post to identify where advanced fine-tuning can tip the scales from good enough to transformative. Use the reference architecture as a baseline to structure your agentic AI systems, and use the capabilities introduced at re:Invent 2025 to accelerate your journey from initial agent deployment to production-grade outcomes.
About the authors
 Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Principal Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Kristine Pearce is a Principal Worldwide Generative AI GTM Specialist at AWS, focused on SageMaker AI model customization, optimization, and inference at scale. She combines her MBA, BS Industrial Engineering background, and human-centered design expertise to bring strategic depth and behavioral science to AI-enabled transformation. Outside work, she channels her creativity through art.
Kristine Pearce is a Principal Worldwide Generative AI GTM Specialist at AWS, focused on SageMaker AI model customization, optimization, and inference at scale. She combines her MBA, BS Industrial Engineering background, and human-centered design expertise to bring strategic depth and behavioral science to AI-enabled transformation. Outside work, she channels her creativity through art.
 Harsh Asnani is a Worldwide Generative AI Specialist Solutions Architect at AWS specializing in ML theory, MLOPs, and production generative AI frameworks. His background is in applied data science with a focus on operationalizing AI workloads in the cloud at scale.
Harsh Asnani is a Worldwide Generative AI Specialist Solutions Architect at AWS specializing in ML theory, MLOPs, and production generative AI frameworks. His background is in applied data science with a focus on operationalizing AI workloads in the cloud at scale.
 Sung-Ching Lin is a Principal Engineer at Amazon Pharmacy, where he leads the design and adoption of AI/ML systems to improve customer experience and operational efficiency. He focuses on building scalable, agent-based architectures, ML evaluation frameworks, and production-ready AI solutions in regulated healthcare domains.
Sung-Ching Lin is a Principal Engineer at Amazon Pharmacy, where he leads the design and adoption of AI/ML systems to improve customer experience and operational efficiency. He focuses on building scalable, agent-based architectures, ML evaluation frameworks, and production-ready AI solutions in regulated healthcare domains.
 Elad Dwek is a Senior AI Business Developer at Amazon, working within Global Engineering, Maintenance, and Sustainability. He partners with stakeholders from business and tech side to identify opportunities where AI can enhance business challenges or completely transform processes, driving innovation from prototyping to production. With a background in construction and physical engineering, he focuses on change management, technology adoption, and building scalable, transferable solutions that deliver continuous improvement across industries. Outside of work, he enjoys traveling around the world with his family.
Elad Dwek is a Senior AI Business Developer at Amazon, working within Global Engineering, Maintenance, and Sustainability. He partners with stakeholders from business and tech side to identify opportunities where AI can enhance business challenges or completely transform processes, driving innovation from prototyping to production. With a background in construction and physical engineering, he focuses on change management, technology adoption, and building scalable, transferable solutions that deliver continuous improvement across industries. Outside of work, he enjoys traveling around the world with his family.
 Carrie Song is a Senior Program Manager at Amazon, working on AI-powered content quality and customer experience initiatives. She partners with applied science, engineering, and UX teams to translate generative AI and machine learning insights into scalable, customer-facing solutions. Her work focuses on improving content quality and streamlining the shopping experience on product detail pages.
Carrie Song is a Senior Program Manager at Amazon, working on AI-powered content quality and customer experience initiatives. She partners with applied science, engineering, and UX teams to translate generative AI and machine learning insights into scalable, customer-facing solutions. Her work focuses on improving content quality and streamlining the shopping experience on product detail pages.

